附录 D — 假设检验实例

D.1 单数字变量-均值比较
D.1.1 问题陈述
疾病控制中心进行的全国家庭成长调查收集了有关家庭生活、结婚和离婚、怀孕、不孕不育、避孕措施以及男女健康的信息。
本次调查收集的变量之一是初婚年龄。2006 年至 2010 年间,5,534 名随机抽样的美国女性完成了调查(这里抽样的女性至少结过一次婚)。
我们是否有证据表明 2006 年至 2010 年所有美国女性的平均初婚年龄都大于 23 岁?
以上是一个典型的单数字变量均值比较问题,目标是根据调查样本的均值,检验总体均值是否等于某个特定值(这里是5534名调查参与人员的平均初婚年龄)。
D.1.2 初步探索数据
age_at_marriage <- read_csv(
"D:/Document/0.Study R/0.R4DS/data/inference-data/ageAtMar.csv",
show_col_types = FALSE
)
# 主要统计量
age_summary <- age_at_marriage |>
summarize(
sample_size = n(),
mean = mean(age),
sd = sd(age),
minimum = min(age),
lower_quartile = quantile(age, 0.25),
median = median(age),
upper_quartile = quantile(age, 0.75),
max = max(age)
)
age_summary |>
pivot_longer(
everything(),
names_to = "Statistic",
values_to = "Value"
)# A tibble: 8 × 2
Statistic Value
<chr> <dbl>
1 sample_size 5534
2 mean 23.4
3 sd 4.72
4 minimum 10
5 lower_quartile 20
6 median 23
7 upper_quartile 26
8 max 43 # 可视化-直方图
ggplot(age_at_marriage, aes(x = age)) +
geom_histogram(binwidth = 3, fill = "lightblue", color = "black") +
labs(
title = "Distribution of Age at First Marriage",
x = "Age at First Marriage",
y = "Frequency"
) +
theme_minimal()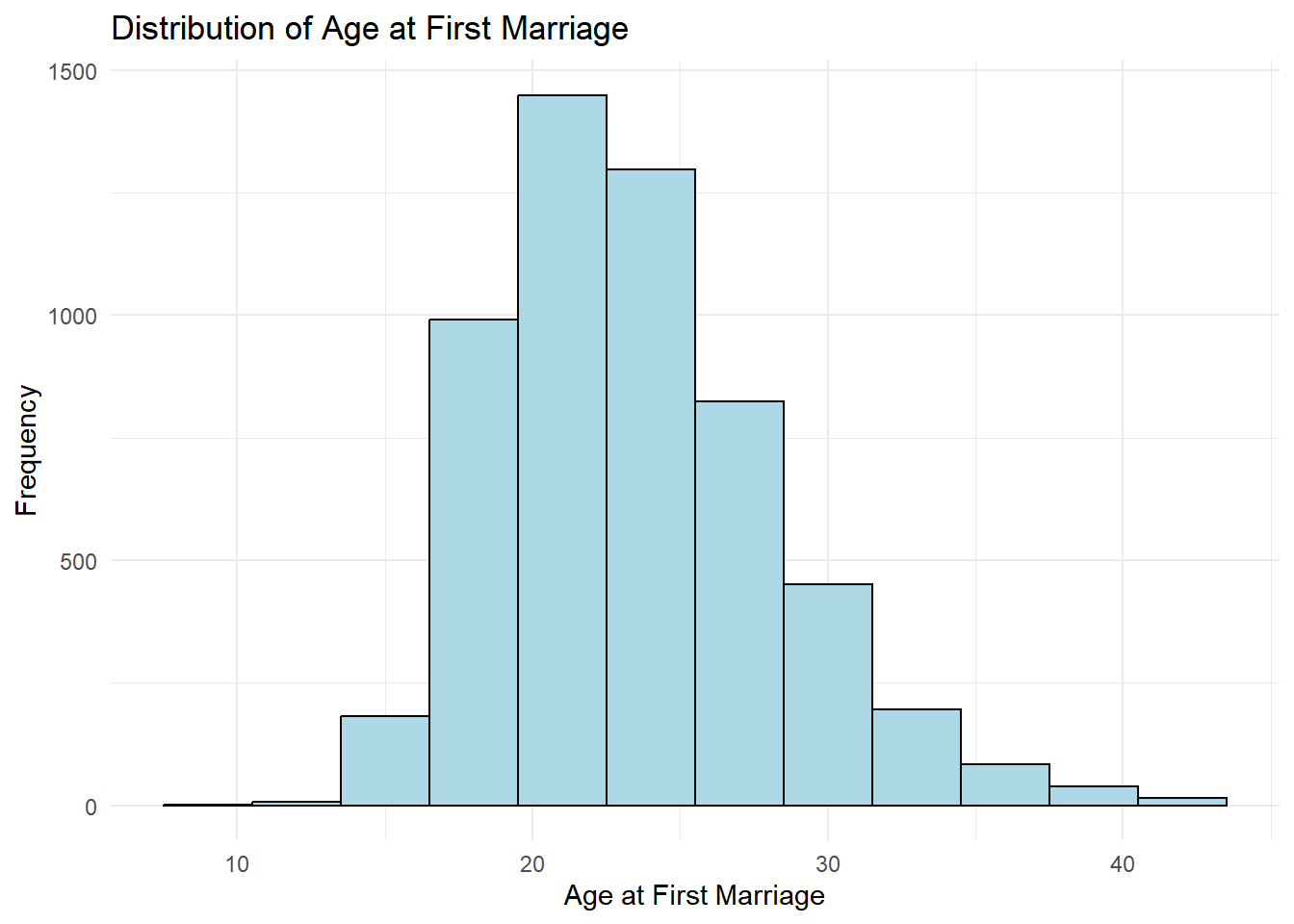
Response: age (numeric)
# A tibble: 1 × 1
stat
<dbl>
1 23.4通过 初步探索数据:
我们可以看到初婚年龄的分布情况大致是符合正态分布的,并计算出样本的平均初婚年龄23.4岁。
接下来,我们将使用假设检验来评估样本均值是否显著高于23岁。用专业的术语来说,为样本均值23.4是否在统计意义上大于总体平均值23。
我们不妨先猜测下,样本均值23.4是否显著大于23岁,这两个数字非常接近,且我们的样本量很大(5534),所以我个人猜测样本均值23.4在统计意义上可能并不显著大于23岁。
D.1.3 假设检验
- 设定原假设和备选假设:
- 原假设 \(H_0: μ = 23\) (初婚年龄的总体均值等于23岁)
- 备选假设 \(H_1: μ > 23\) (初婚年龄的总体均值大于23岁)
选择显著性水平 (α):通常选择 α = 0.05。
进行假设检验:
set.seed(2018)
# define null dist
null_dist_marriage_age <- age_at_marriage |>
specify(response = age) |>
hypothesize(null = "point", mu = 23) |>
generate(reps = 1000, type = "bootstrap") |>
calculate(stat = "mean")
# get p-value
p_value_marriage_age <- null_dist_marriage_age |>
get_p_value(obs_stat = obs_mean_marriage_age, direction = "greater")
p_value_marriage_age# A tibble: 1 × 1
p_value
<dbl>
1 0# visualize null distribution
null_dist_marriage_age |>
visualize() +
shade_p_value(
obs_stat = obs_mean_marriage_age,
direction = "greater"
)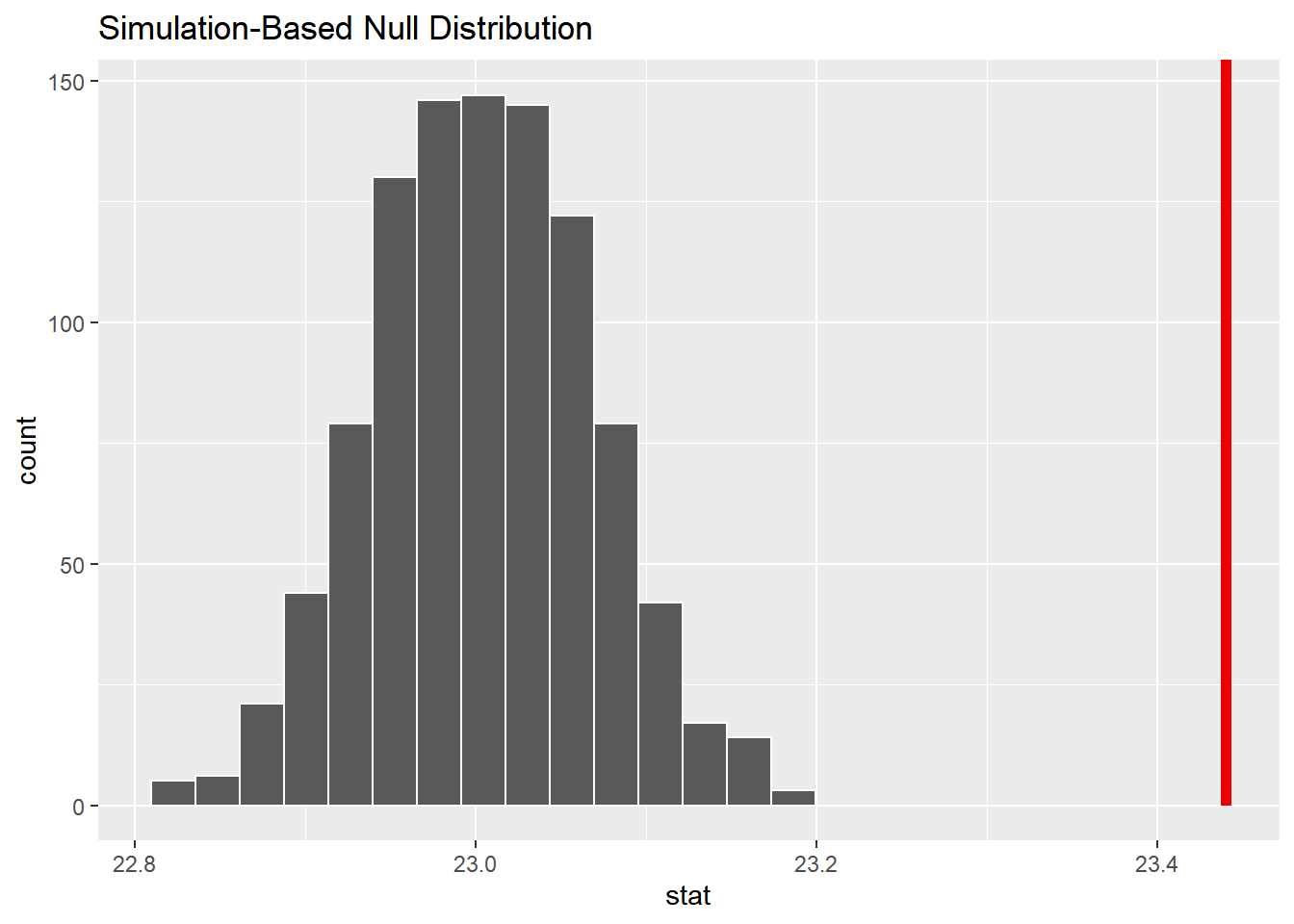
结果显示p-value为0,小于显著性水平0.05,因此我们拒绝原假设,认为2006年至2010年所有美国女性的平均初婚年龄显著大于23岁。
D.1.4 区间估计
# define boot dist
boot_dist_marriage_age <- age_at_marriage |>
specify(response = age) |>
# without hypothesize() step
generate(rep = 1000, type = "bootstrap") |>
calculate(stat = "mean")
# get 95% conf interval
conf_interval_marriage_age <- boot_dist_marriage_age |>
get_ci(level = 0.95, type = "percentile")
conf_interval_marriage_age# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 23.3 23.6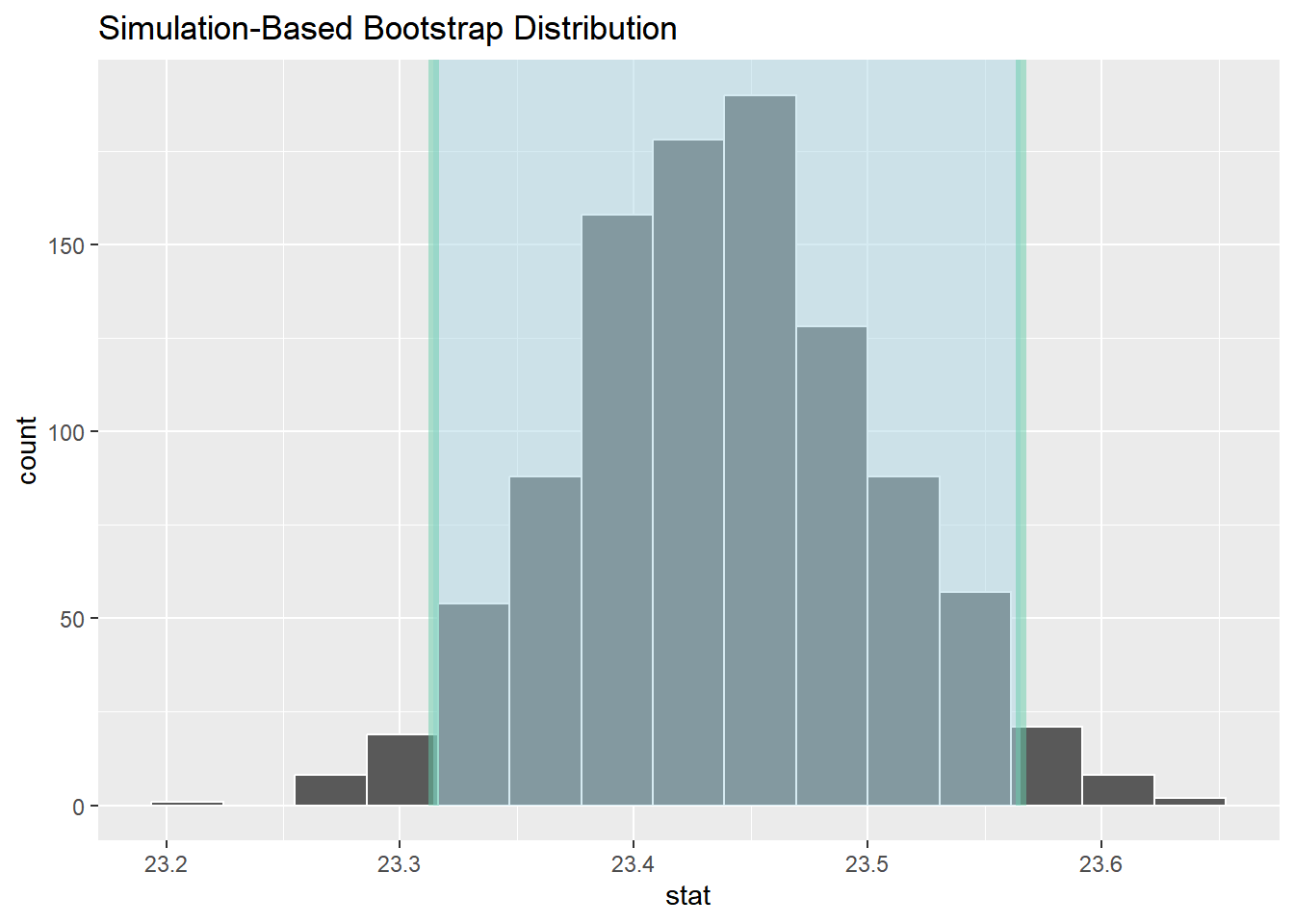
结果显示,95% 置信区间为 (23.29, 23.51),不包含假设的总体均值23,因此我们有信心认为总体均值大于23岁。
D.2 两数字变量(独立)-均值比较
D.2.1 问题陈述
假设一名应届毕业生正在考虑在俄亥俄州克利夫兰或加利福尼亚州萨克拉门托这两个地方工作,他想看看其中一个城市的平均收入是否高于另一个城市。他想根据 2000 年人口普查中随机选择的两个样本进行假设检验。
这个问题是一个典型的两数字变量均值比较问题,目标是根据两个独立样本的均值,检验两个总体均值是否存在显著差异(这里是克利夫兰和萨克拉门托的平均收入)。
D.2.2 初步探索数据
# load and clean data
cle_sac <- read.delim(
"D:/Document/0.Study R/0.R4DS/data/inference-data/cleSac.txt"
) |>
rename(
metro_area = Metropolitan_area_Detailed,
income = Total_personal_income
) |>
na.omit()
# summarize data
inc_summ <- cle_sac |>
group_by(metro_area) |>
summarize(
sample_size = n(),
mean = mean(income),
sd = sd(income),
minimum = min(income),
lower_quartile = quantile(income, 0.25),
median = median(income),
upper_quartile = quantile(income, 0.75),
max = max(income)
)
inc_summ# A tibble: 2 × 9
metro_area sample_size mean sd minimum lower_quartile median
<chr> <int> <dbl> <dbl> <int> <dbl> <dbl>
1 Cleveland_ OH 212 27467. 27681. 0 8475 21000
2 Sacramento_ CA 175 32428. 35774. 0 8050 20000
# ℹ 2 more variables: upper_quartile <dbl>, max <int># visualize data
ggplot(cle_sac, aes(x = metro_area, y = income)) +
geom_boxplot() +
stat_summary(fun = mean, geom = "point", color = "red")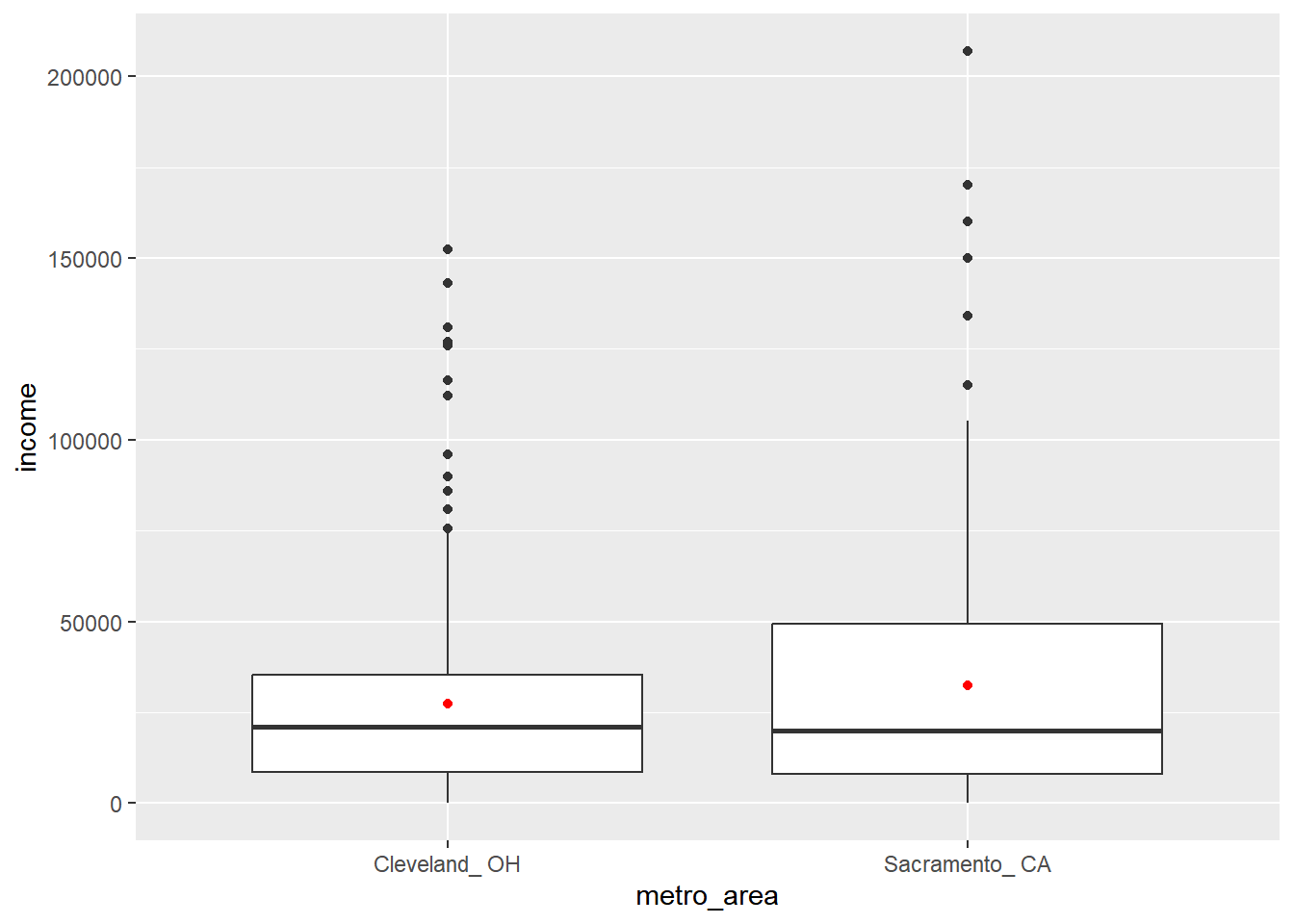
通过 初步探索数据:
- 我们可以看到克利夫兰和萨克拉门托的收入分布情况,并计算出两个样本的平均收入分别为 29,835 美元和 32,402 美元。
- 禁通过可视化图表可以看出,萨克拉门托的收入中位数和均值都高于克利夫兰,但这种差异在统计意义上是否显著还有待检验。
D.2.3 假设检验
- 设定原假设和备选假设:
- 原假设 \(H_0: μ_{Sac} = μ_{Cle}\) (克利夫兰和萨克拉门托的平均收入相等)
- 备选假设 \(H_1: μ_{Sac} ≠ μ_{Cle}\) (克利夫兰和萨克拉门托的平均收入不等)
- 选择显著性水平 (α):通常选择 α = 0.05。
- 进行假设检验:
Response: income (numeric)
Explanatory: metro_area (factor)
# A tibble: 1 × 1
stat
<dbl>
1 4960.# define null dist
null_dist_income <- cle_sac |>
specify(income ~ metro_area) |>
hypothesize(null = "independence") |>
generate(reps = 1000) |>
calculate(
stat = "diff in means",
order = c("Sacramento_ CA", "Cleveland_ OH")
)
# get p-value
p_value_income <- null_dist_income |>
get_p_value(obs_stat = obs_diff_income, direction = "both")
p_value_income# A tibble: 1 × 1
p_value
<dbl>
1 0.132# visualize null distribution
null_dist_income |>
visualize() +
shade_p_value(
obs_stat = obs_diff_income,
direction = "both"
)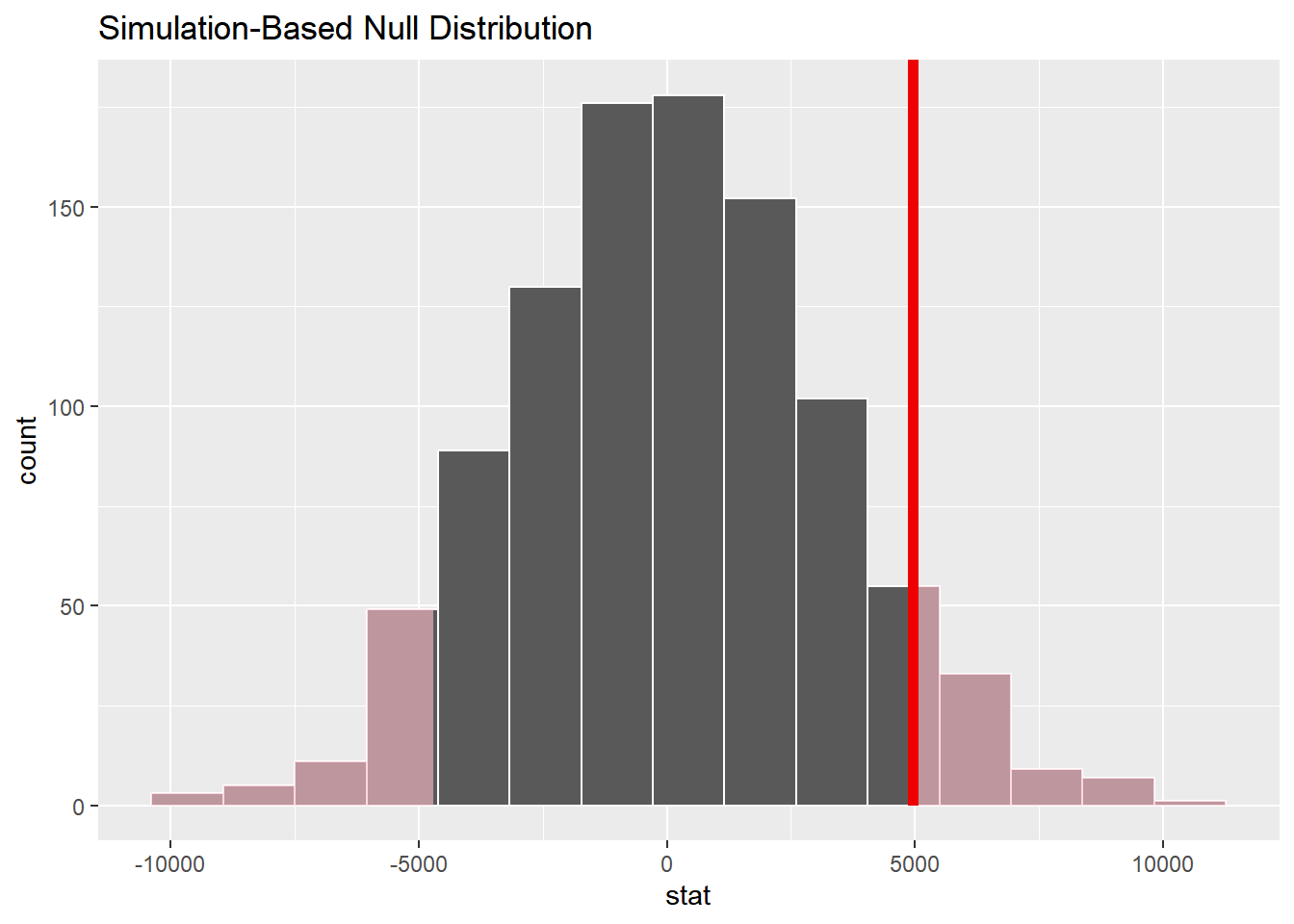
结果显示p-value为0.122,大于显著性水平0.05,因此我们不能在95%的置信区间上拒绝原假设,无法做出克利夫兰和萨克拉门托的平均收入在统计意义上存在显著差异的结论。
D.2.4 区间估计
boot_dist_income <-
cle_sac |>
specify(income ~ metro_area) |>
# without hypothesize() step
generate(rep = 1000, type = "bootstrap") |>
calculate(
stat = "diff in means",
order = c("Sacramento_ CA", "Cleveland_ OH")
)
# get 95% conf interval
conf_interval_income <- boot_dist_income |>
get_ci(level = 0.95, type = "percentile")
conf_interval_income# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 -1096. 11742.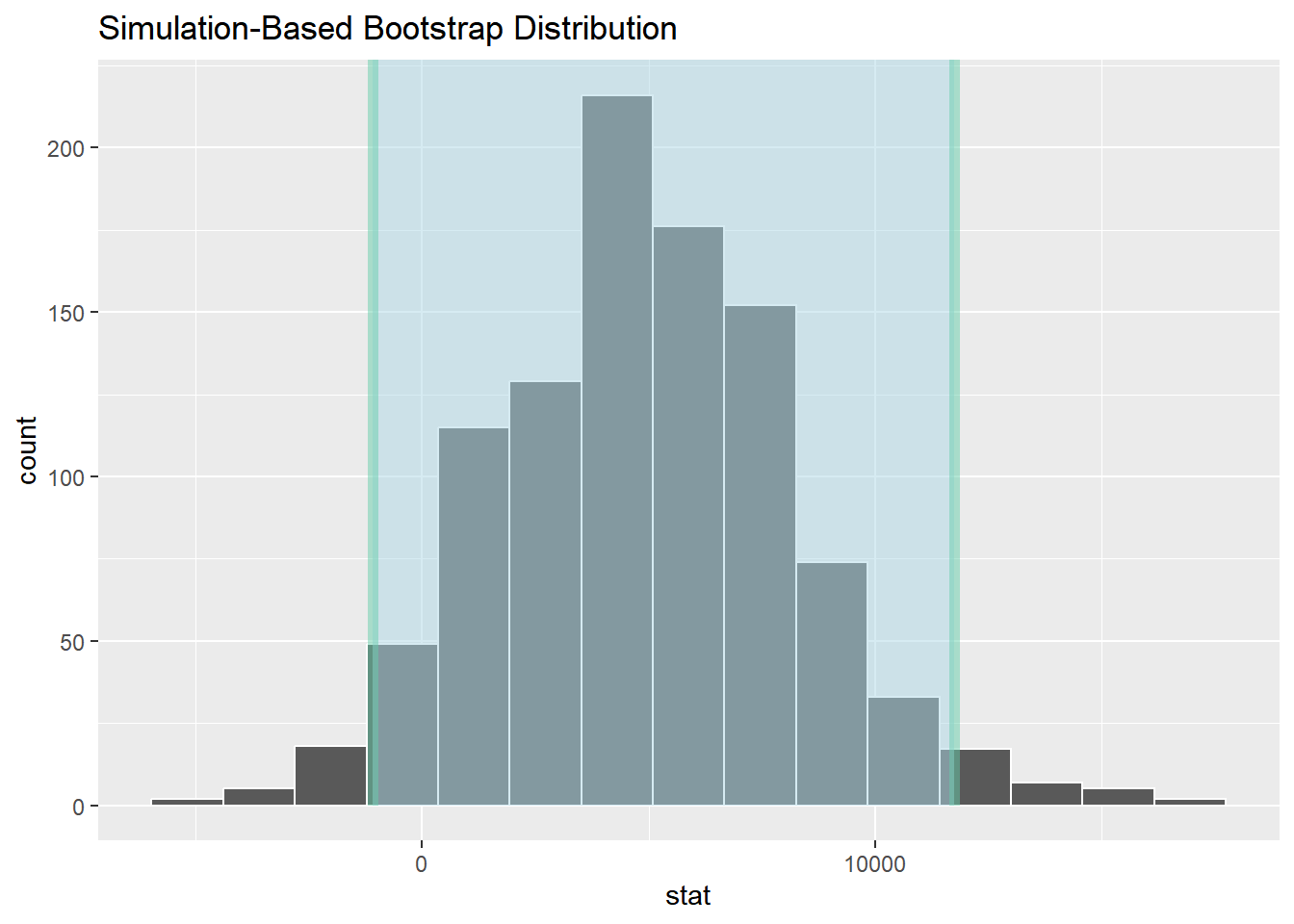
结果显示,95% 置信区间为 (-1108, 11185),包含了0值,因此我们没有足够的证据表明两个城市的平均收入存在显著差异。
D.3 两数字变量(配对)-均值比较
D.3.1 问题陈述
饮用水中的微量金属会对水体产生影响,异常高的浓度会对健康造成危害。在一段河流上随机选择的 10 个位置测量底层水和地表水中锌浓度的 10 对数据。数据是否表明地表水中的真实平均浓度小于底层水?
D.3.2 初步探索数据
# A tibble: 10 × 2
loc_id pair_diff
<dbl> <dbl>
1 1 -0.0150
2 2 -0.0280
3 3 -0.177
4 4 -0.121
5 5 -0.102
6 6 -0.107
7 7 -0.0190
8 8 -0.0660
9 9 -0.058
10 10 -0.111 Response: pair_diff (numeric)
# A tibble: 1 × 1
stat
<dbl>
1 -0.0804# plot data
ggplot(zinc_diff, aes(pair_diff)) +
geom_histogram(binwidth = 0.04, color = "white")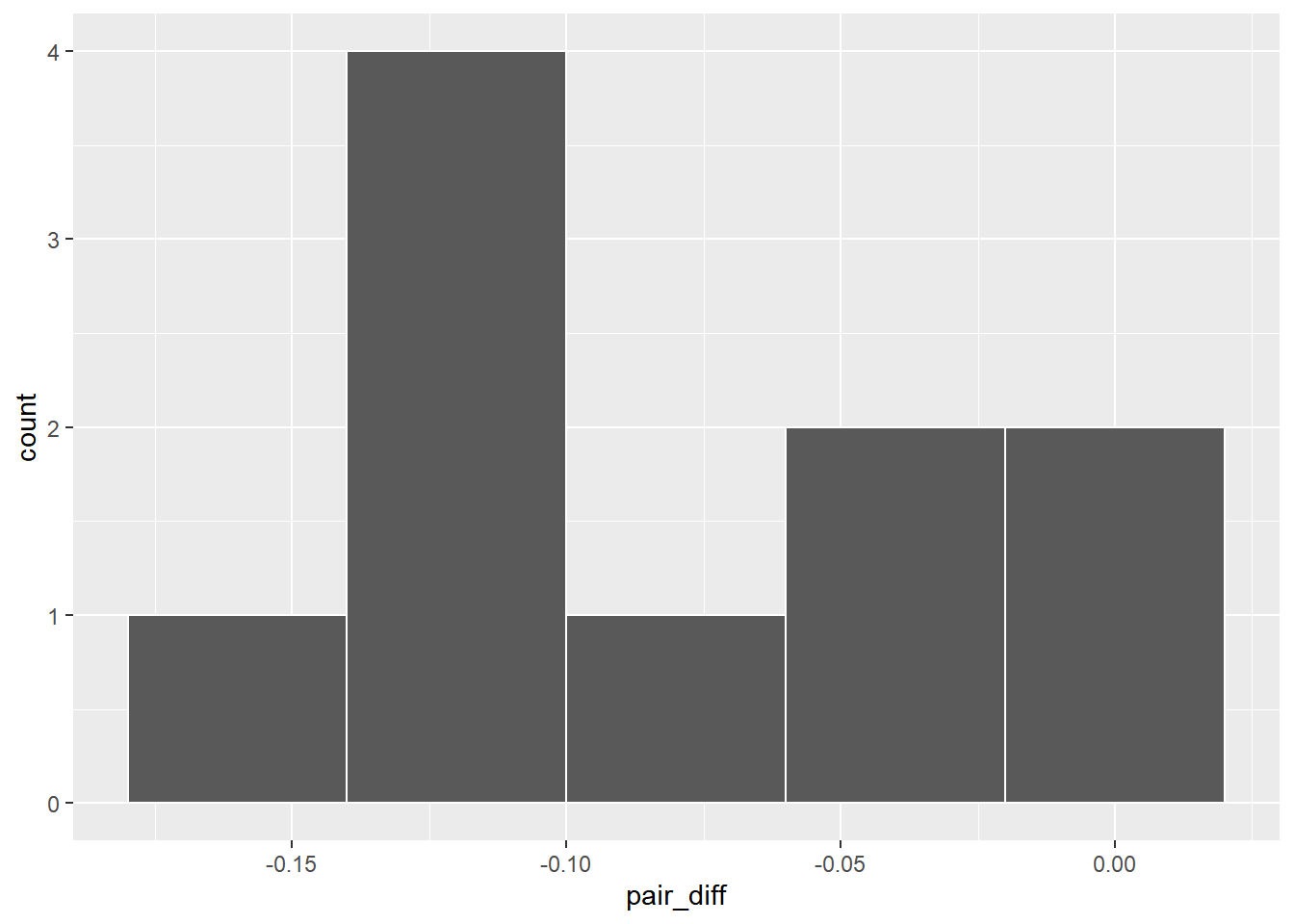
我们正在寻找样本配对平均差 -0.08 在统计学上是否小于 0。它们似乎很接近,但数据是配对的(两个水层的zinc数据可能相互影响)。
D.3.3 假设检验
- 设定原假设和备选假设:
- 原假设:地表水的平均浓度与其配对位置的地层水相同。
- 备择假设:地表水中的平均浓度小于预期配对位置的底层水的平均浓度。
- 选择显著性水平 (α):通常选择 α = 0.05。
- 进行假设检验:
# define null dist
null_dist_zinc_paired <- zinc_diff |>
specify(response = pair_diff) |>
hypothesize(null = "point", mu = 0) |>
generate(reps = 10000) |>
calculate(stat = "mean")
# get p-value
p_value_zinc_paired <- null_dist_zinc_paired |>
get_p_value(obs_stat = obs_diff_zinc, direction = "less")
# visualize null distribution
null_dist_zinc_paired |>
visualize() +
shade_p_value(
obs_stat = obs_diff_zinc,
direction = "less"
)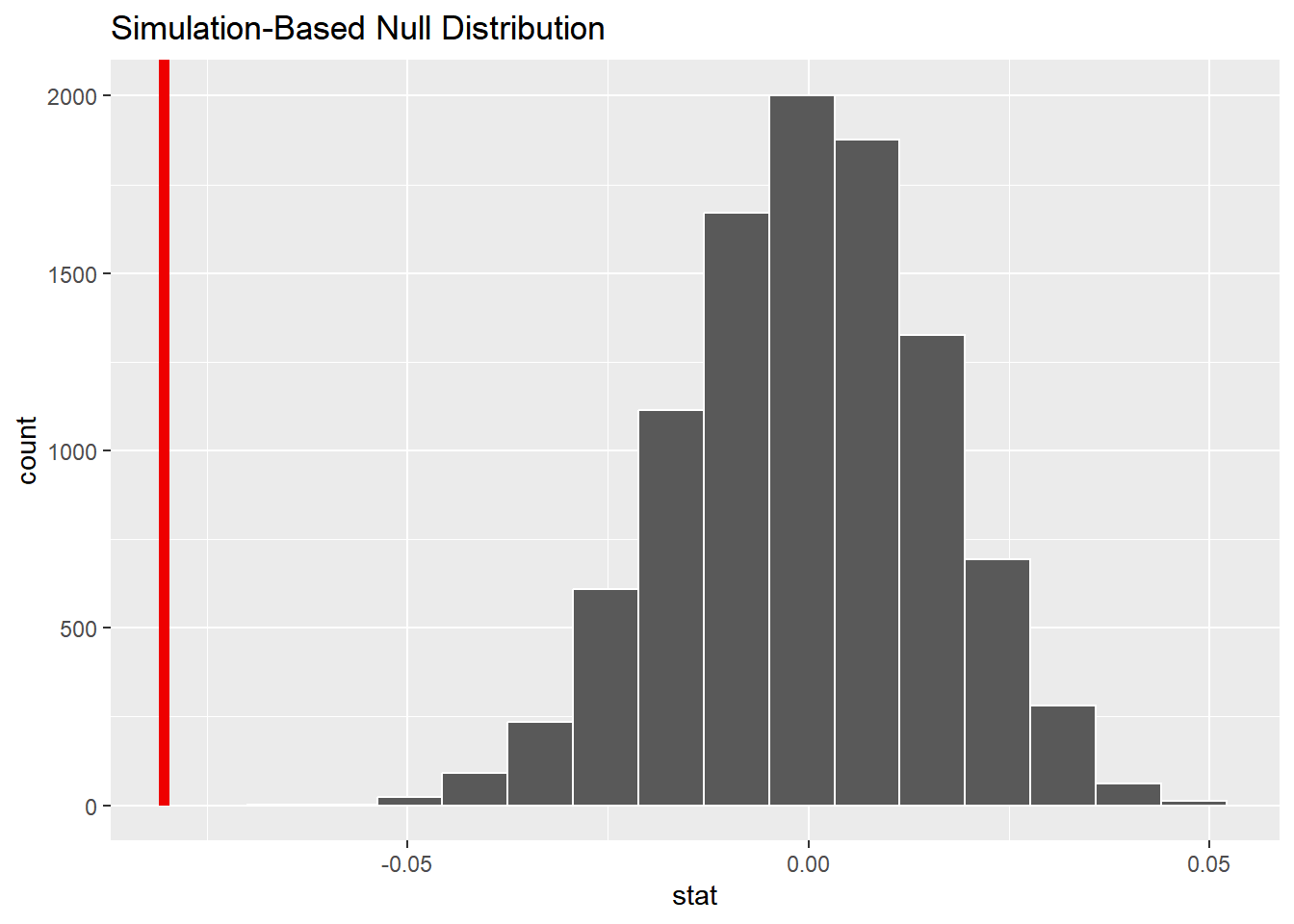
结果显示p-value为0,小于显著性水平0.05,因此我们拒绝原假设,认为地表水中的真实平均浓度显著小于底层水。
D.3.4 区间估计
# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 -0.112 -0.0502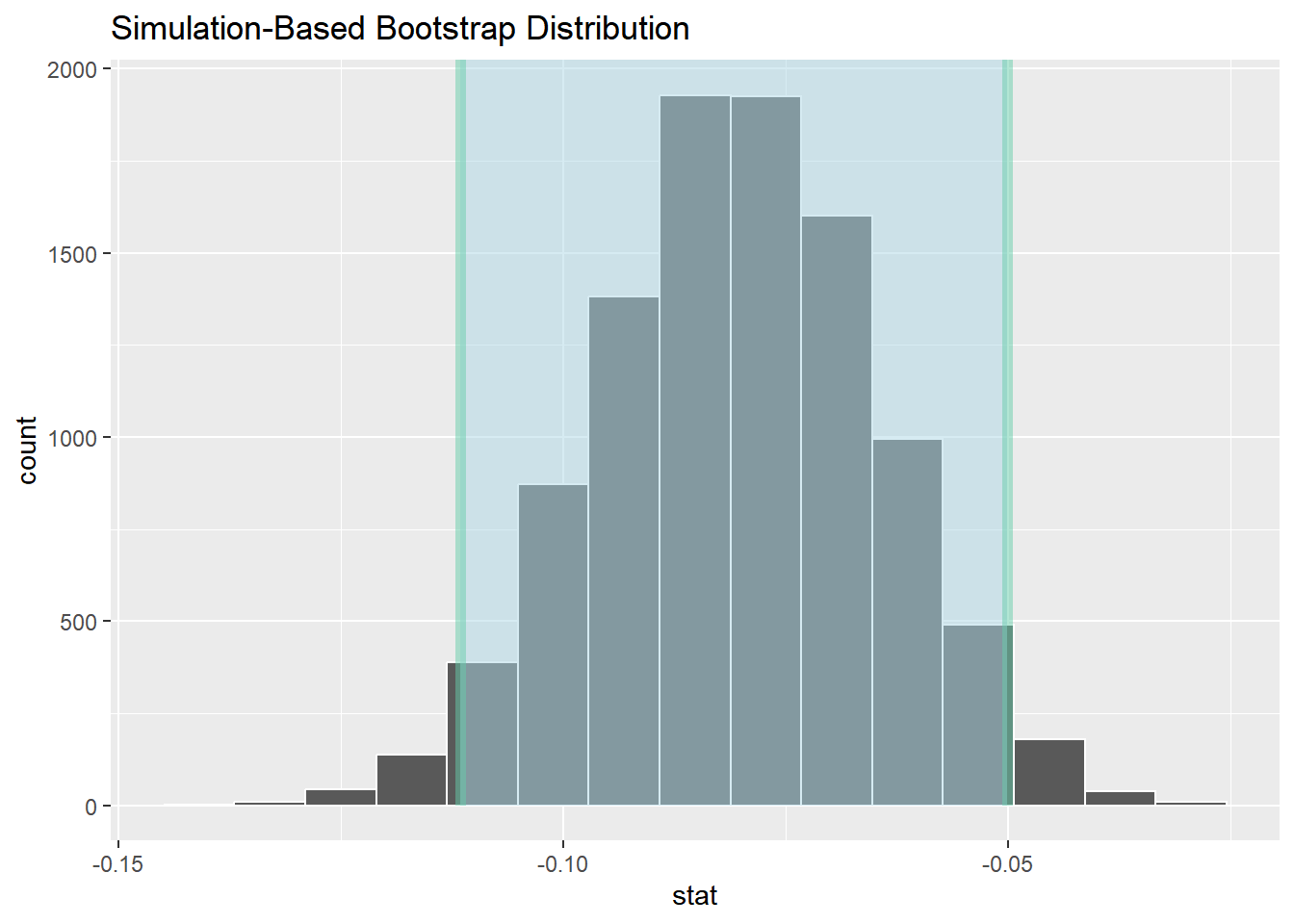
结果显示,结果显示,95% 置信区间为 (-0.111, -0.0507),未包含0值,且整个置信区间均小于0,因此我们有足够的证据表明表面水的锌浓度低于底层水的锌浓度。
D.4 单分类变量-比例比较
D.4.1 问题陈述
假设一家大型电力公司的首席执行官表示,其公司的 1,000,000 名客户中有 80% 对他们获得的服务感到满意。为了验证这一说法,当地报纸使用简单的随机抽样对 100 名客户进行了调查,其中73人满意,27人不满意。
根据样本的这些发现,我们能否拒绝 CEO 关于 80% 的客户满意的假设?
D.4.2 初步探索数据
D.4.3 假设检验
- 设定原假设和备选假设:
- 原假设 (H0): p = 0.80 (客户满意度等于80%)
- 备选假设 (H1): p ≠ 0.80 (客户满意度不等于80%)
- 选择显著性水平 (α):通常选择 α = 0.05。