25 假设检验
更多假设检验/统计推断的例子,请参看 附录 D。
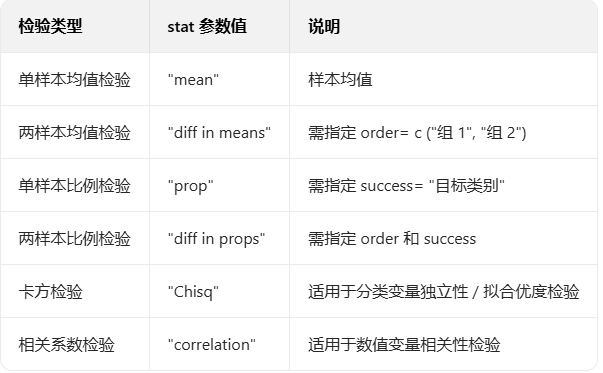
- 区间估计(置信区间)需要知道变量的分布类型为正态分布。
- 中心极限定理(CentralLimit Theorem, CLT):当样本数量足够大时,无论单个随机变量本身服从什么分布,这些变量的均值会近似服从正态分布(即 “钟形曲线” 分布)。
- 中心极限定理是区间估计的核心,在样本量较大的情况下,所有变量的均值均近似服从正态分布,所以可以使用正态分布来近似样本均值的分布,从而进行置信区间估计。
25.1 假设检验原理
实际中,只能得到抽取样本的统计结果(即只能得到总体的部分样本的统计量),想要进一步推断总体的特征,必然会产生错误,那么犯错的概率为多少时可以接受这种推断呢?
为此,统计学家基于小概率反证法思想开发了假设检验这一统计方法。所谓小概率反证法思想,是指小概率事件,即发生的概率P<0.01或P<0.05的事件,在一次试验中基本上不会发生。具体来说,反证法思想是先提出假设(一般称之为原假设,记为H0),再用适当的统计方法确定假设成立的可能性大小。若可能性小,则认为这个原假设不成立;若可能性大,则不认为原假设不成立。
假设检验的基本逻辑是:如果原假设为真,则检验统计量(样本数据的函数)将服从某种概率分布。
检验统计量(test statistic)是用于假设检验计算的统计量,即使用样本估计得出的统计量。观察统计量(observed test statistic)是原始样本的统计量,用于与检验统计量进行比较。
p值:具体来说:
- 先提出原假设 \(H_0\)(零假设),接着在原假设为真的前提下,基于样本数据计算出检验统计量值,与统计学家建立的这些统计量应服从的概率分布进行对比,就可以知道在百分之多少(P值1)的机遇下会得到目前的结果。
- 若经比较后发现,出现该结果的概率(P值)很小,即原假设(零假设)是基本不会发生的小概率事件,则应拒绝原假设,
- 显著性水平:充当p值的临界值,如果p值低于显著性水平,则说明原假设越不显著,越应拒绝原假设。
假设检验的判断方法有两种:p值法和临界值法。
以t检验为例
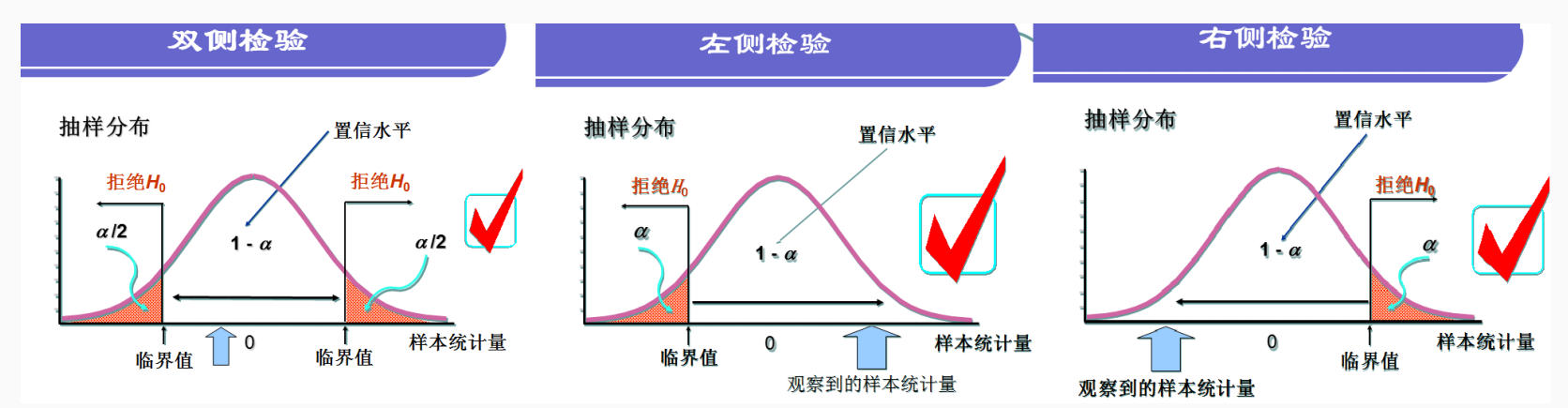
如 图 25.3 所示,临界值法以显著水平处的统计量值为界限,白色的区域是接受域,阴影部分为拒绝阈,通过计算统计量值 \(t_0\) 来得出对应的结论。
以0.05显著水平为例:
-
双侧检验:\(H_0: \mu = \mu_0, \mu \neq \mu_0\)
- 在原假设 \(H_0\) 下,根据样本数据计算出t统计量 \(t_0\)
- \(P值=P\lbrace |t| \geq t_0 \rbrace\),表示 \(t_0\) 的双侧尾部的面积。
- 若 \(P < 0.05\) (在双尾部分),则在0.05显著水平下拒绝原假设。
-
左侧检验:\(H_0: \mu \geq \mu_0, \mu \leq \mu_0\)
- 在原假设 \(H_0\) 下,根据样本数据计算出t统计量 \(t_0\)
- \(P值=P\lbrace t \leq t_0 \rbrace\),表示 \(t_0\) 的左侧尾部的面积。
- 若 \(P < 0.05\)( 在左侧尾部分),则在0.05显著水平下拒绝原假设。
-
右侧检验:\(H_0: \mu \leq \mu_0, \mu \geq \mu_0\)
- 在原假设 \(H_0\) 下,根据样本数据计算出t统计量 \(t_0\)
- \(P值=P\lbrace t \geq t_0 \rbrace\) ,表示 \(t_0\) 的左侧尾部的面积。
- 若 \(P < 0.05\) (在右侧尾部分),则在0.05显著水平下拒绝原假设。
25.1.1 解释假设检验
- 无法拒绝原假设和接受原假设是有区别的:
- 原假设和备选假设其中一个为真。
- 假设检验为假定原假设为真的情况下进行的。
- 仅当样本中发现的证据表明备选假设为真时,我们才拒绝原假设而接受备选假设。显著性水平就是为了证明我们需要这个证据的强度。
- 正确的说法应该为拒绝原假设或无法拒绝原假设。
使用假设检验,首先需要明确原假设和备选假设是什么;然后调用相应的函数计算得到结果;最后解读结果:如果p值小于0.05(置信水平设为95%时),则拒绝原假设,并得出实验有效或结果统计上显著的结论。
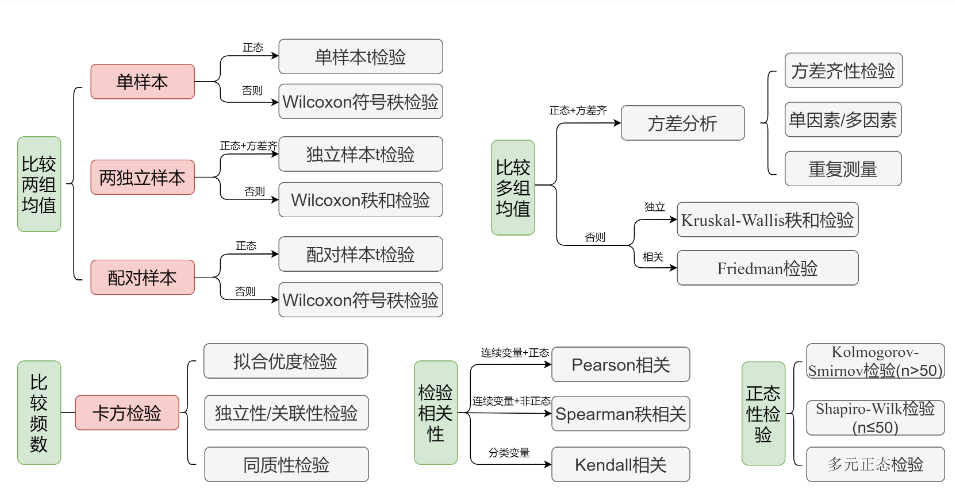
图 D.1 展示了常用的假设检验及其适用的情况。
25.2 原假设和备选假设的设定讨论
在实际问题的操作和解决中,通常将研究者希望收集证据予以拒绝的假设作为原假设,而将研究者希望收集证据予以支持的假设作为备选假设。例如,质量标准规定产品平均重量达到500克为合格品,质量检验人员通常希望找出不合格产品,即研究者希望通过收集证据予以支持的是该批产品的平均重量不足500克,及原假设应设定为产品平均质量达到了500g。
原假设与备择假设是一对完全互斥事件,一项检验中,原假设和备择假设有且只有一项成立。
因为原假设假定总体参数未发生变化,所以“=”总是在原假设上,尽管原假设也可能存在方向,但实际检验时只需要针对取“=”时的情形。
由于备择假设是研究者希望通过收集证据予以支持的假设,一般情况下,建立假设时,先建立备择假设在确定原假设。
由于假设是基于研究者的角度和立场出发,同样的问题因立场不同会有完全不同方向甚至反向的假设。
25.2.1 假设设定例1
一采购商需要采购一批构件,某供应商称其提供的构件合格率超过95%,为了检验其可信度,采购商随机抽取了一批样本进行检验。试陈述用于检验的原假设与备择假设。
- 设零件合格率为 \(\pi\),检验者为采购商,其立场是对供应商提供的构建合格率数据有疑问,即希望收集证据证明构建合格率不足95%。
- 那么原假设应该设定为合格率大于95,备选假设为合格率不足95%。
25.2.2 假设设定例2
一乳制品生产商生产的奶粉被媒体曝光某种营养成分大大低于国家规定的2%的含量标准。
问题1: 现质量监督部门从保护消费者权益角度出发,对曝光的奶粉进行抽查,请对检验做出假设。 问题2: 如果生产商相信其产品不存在上述问题,判断这是由竞争对手操纵的不正当竞争手段,并委托市场上的第三方检测机构进行检测,请对这一检验作出假设。
分析:设奶粉的营养成分含量为π
对于问题1,质量监督部门希望收寄证明该奶粉营养成分含量低于2%。那么原假设应设定为营养成分高于2%,备选假设为营养成分低于2%。 对于问题2,生产商希望收寄证明该奶粉营养成分没问题。那么原假设应设定为营养成分低于2%,备选假设为营养成分高于2%。
25.3 使用标准误计算置信区间
即使一个代表性非常好的样本,也无法完全与总体等同,总会存在一定的抽样误差。
例如用100人的平均身高作为总体参数\(\mu\)的估计,如果在随机抽样100人,又得到另一个平均身高……依次类推做10次抽样,就可以计算出样本统计量:10个平均身高和10个标准差。这10个平均身高也可以计算标准差(即标准误,样本统计量的标准差),它反映了样本统计量之间差别(即抽样误差)的大小。
而实际中不可能多次抽样计算每个样本的统计量,再计算各统计量间的差异。通长我们获取一个尽可能大的样本来计算标准误,借助以下公式。式 式 25.1 中,s为样本标准差,n为样本量。
\[ se = s\sqrt{n} \tag{25.1}\]
标误几乎在所有的统计方法中都会出现,因为其大小直接发硬了抽样是否有足够的代表性,进而考察得出的结果是否有可靠性。
由于抽样误差的存在,如果用样本统计量直接估计总体参数,则肯定会有一定偏差。所以在估计总体参数时,需要考虑到这种偏差大小,即用置信区间(\(参数估计值 \pm 估计误差\))来估计总体参数。
根据中心极限定理,从任何分布中抽样,只要样本量足够大,其统计量最终会服从正态分布。因此,估计误差通常用对应一定正态分位数的z值在乘以抽样误差的标准误来表示。例如,95%置信区间一般表示为\(参数估计值 \pm 1.96 \times 标准误\)
25.3.1 Bootstrap法估计置信区间
对于某些抽样分布未知或难以计算的统计量,就需要使用Bootstrap(自助)重抽样法2来研究抽样样本变化所带来的变异。
Bootstrap 法的基本思想是:样本是从总体中随机抽取的,则包含总体的全部信息,那么不妨就把该样本视为”总体”,进行多次有放回抽样生成一系列经验样本,再对每个经验样本计算统计量,就可以得到统计量的分布,进而用于统计推断。
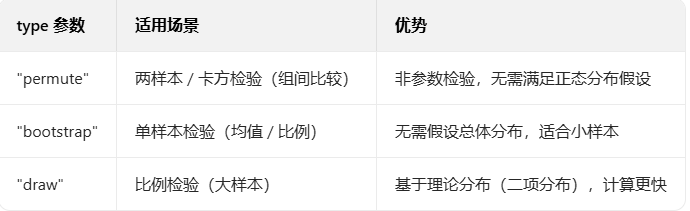
tidymodels 系列的 infer 包提供了统一的、tidy的统计推断工作流,主要函数有:
specify(): 设定感兴趣的变量或变量关系
hypothesize(): 设定零假设
generate(): 基于零假设生成数据
calculate(): 根据上述数据,计算统计量的分布
visualize(): 可视化
还有获取/绘制 p 值/置信区间的函数。
Bootstrap法估计统计量置信区间的基本步骤如下:
从原始样本中有会放的随机抽取n个个体构成子样本。
对子样本计算想要的统计量。
重复前两步K次,得到K个统计量的估计值。
根据K个估计值获得统计量的分布,并计算置信区间。
25.4 案例1:动作电影和爱情电影的评分谁更高?
movies_sample# A tibble: 68 × 4
title year rating genre
<chr> <int> <dbl> <chr>
1 Underworld 1985 3.1 Action
2 Love Affair 1932 6.3 Romance
3 Junglee 1961 6.8 Romance
4 Eversmile, New Jersey 1989 5 Romance
5 Search and Destroy 1979 4 Action
6 Secreto de Romelia, El 1988 4.9 Romance
7 Amants du Pont-Neuf, Les 1991 7.4 Romance
8 Illicit Dreams 1995 3.5 Action
9 Kabhi Kabhie 1976 7.7 Romance
10 Electric Horseman, The 1979 5.8 Romance
# ℹ 58 more rowsmovies_sample |>
ggplot(aes(x = genre, y = rating)) +
geom_boxplot()
# A tibble: 2 × 4
genre n mean_rating sed_dev
<chr> <int> <dbl> <dbl>
1 Action 32 5.28 1.36
2 Romance 36 6.32 1.61爱情电影比动作电影的平均得分更高,这是否可以说明所有的爱情片评分都高于动作片?
25.4.1 构建假设检验
- 设定原假设和备选假设:
- \(H_0: \mu_a-\mu_r = 0\),即两类电影得分没有显著差异,平均得分之差为0。
- \(H_1: \mu_a-\mu_r \neq 0\)
- 设定显著性水平:
- 设定显著性水平 \(\alpha = 0.001\)。
- 在所有条件相同的情况下,显著性水平值越小,p值小于α的可能性越低。因此,我们拒绝原假设而支持替代假设的几率较低。
- 构建假设检验
null_dist_movies <- movies_sample |>
specify(formula = rating ~ genre) |>
# 设定原假设
hypothesise(null = "independence") |>
# 进行置换检验
generate(reps = 1000, type = "permute") |>
# 计算检验统计量
calculate(
stat = "diff in means",
order = c("Action", "Romance")
)
null_dist_moviesResponse: rating (numeric)
Explanatory: genre (factor)
Null Hypothesis: indep...
# A tibble: 1,000 × 2
replicate stat
<int> <dbl>
1 1 0.511
2 2 -0.870
3 3 0.251
4 4 0.251
5 5 0.635
6 6 0.133
7 7 0.0684
8 8 -0.315
9 9 -0.215
10 10 -0.557
# ℹ 990 more rows得到检验统计量分布,是由1000个检验统计量构成的。这个分布假设原假设为真。
- 计算原始样本统计量
Response: rating (numeric)
Explanatory: genre (factor)
# A tibble: 1 × 1
stat
<dbl>
1 -1.05- 可视化和计算p值
visualise(null_dist_movies, bins = 10) +
shade_p_value(
obs_stat = obs_diff_means,
direction = "both"
)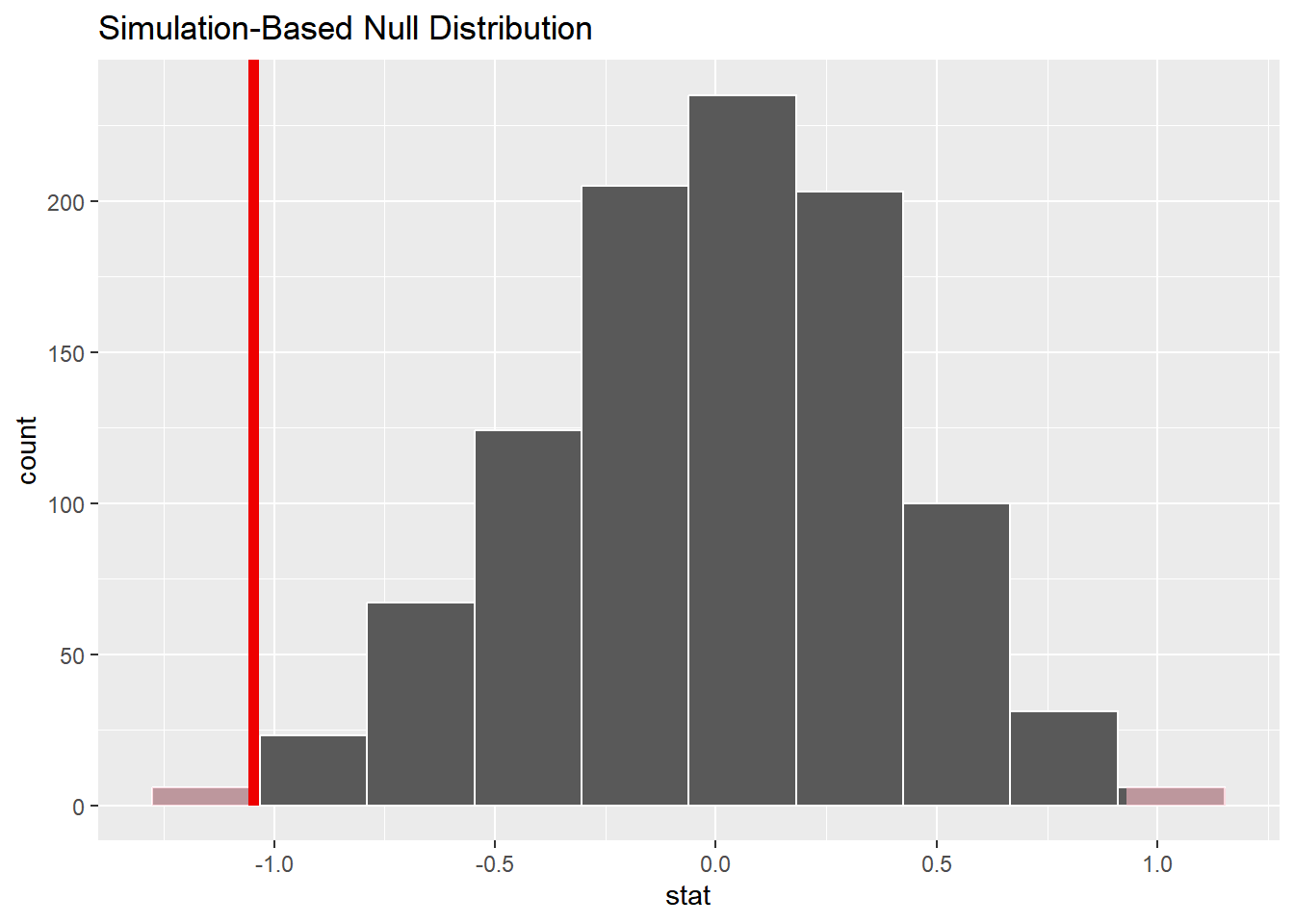
- 图中分布为原假设分布。
- 红色的直线为原始样本统计量(原始样本中两类电影评分平均值之差)。
- 图中有两个形成p值的的区域,分别位于两侧尾巴处。
null_dist_movies |>
get_p_value(obs_stat = obs_diff_means, direction = "both")# A tibble: 1 × 1
p_value
<dbl>
1 0.01\(p值=0.012\) 很小,即只有很小的概率可以观察到差异的存在,亦即拒绝原假设。
但p值还是远大于我们设定的置信水平 \(\alpha=0.001\),即我们在0.001的置信水平上倾向于无法拒绝原假设。
在这个数据样本中,我们没有所需的证据来表明我们应该拒绝爱情电影和动作电影之间IMDb平均收视率没有差异的假设。换言之,我们不能说所有IMDb电影的浪漫和动作电影评分平均存在差异。
- 获取CI
计算置信区间和传统方法一样,唯二的区别是:
不需要设定
hypothesize()了,因为我们不再设定原假设为真。将重采样的
type设定为bootstrap。
bootstrap_dist <- movies_sample |>
specify(formula = rating ~ genre) |>
generate(reps = 1000, type = "bootstrap") |>
calculate(stat = "diff in means", order = c("Action", "Romance"))
percentile_ci <- bootstrap_dist |>
get_ci(
level = 0.9,
type = "percentile"
)
visualise(bootstrap_dist) +
shade_ci(endpoints = percentile_ci)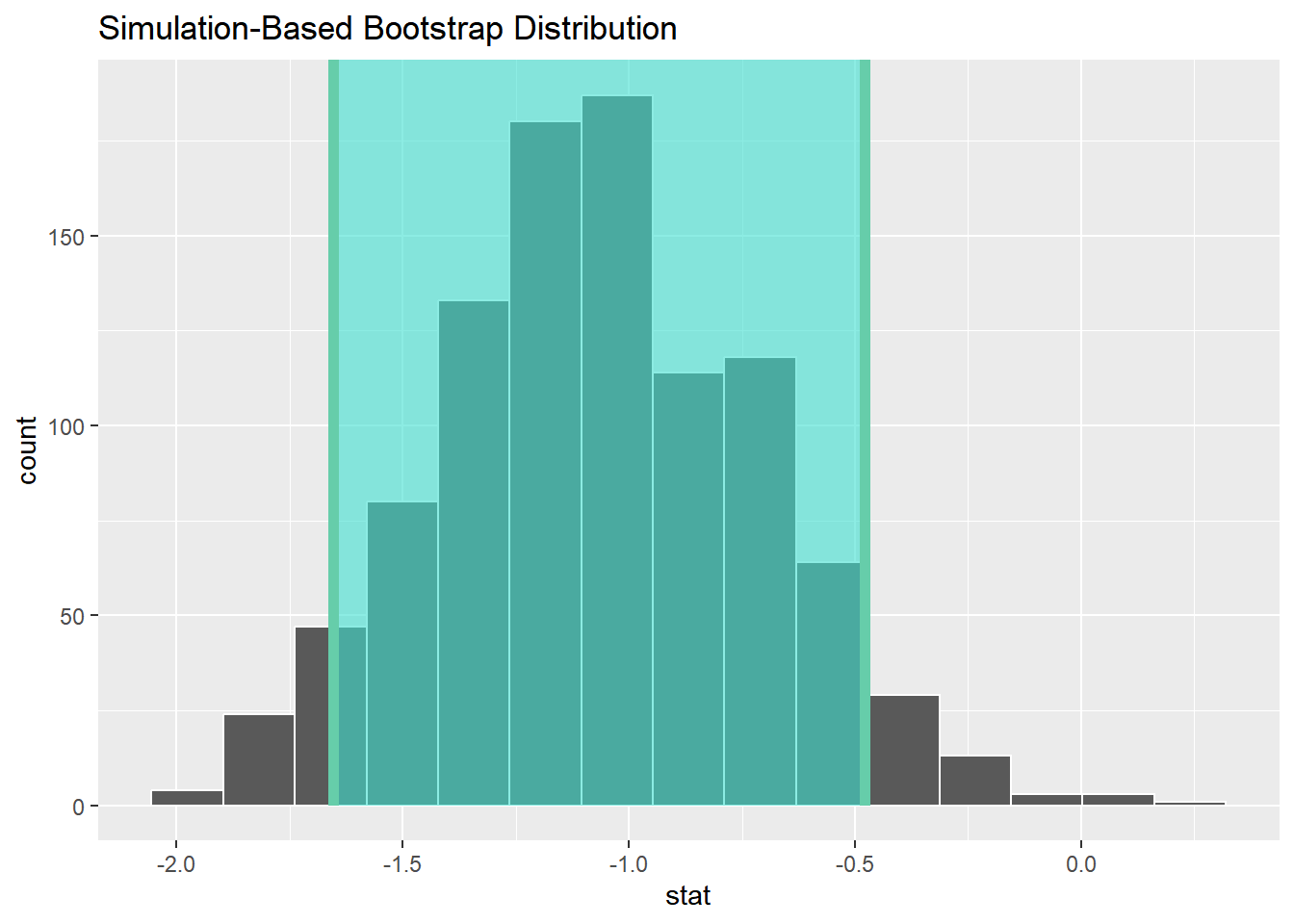
- 结果显示,动作电影和爱情电影差异的置信区间为 \([-1.60, 0.459]\),原始的样本统计量为-1.05,包含在置信区间之内。
- 得出的结论与假设检验一致,无法证明IMDb电影的浪漫和动作电影评分平均存在差异。
25.5 案例2: 航天事业的预算是否有党派门户之见?
# A tibble: 8 × 3
NASA party n
<fct> <fct> <int>
1 TOO LITTLE Dem 8
2 TOO LITTLE Ind 13
3 TOO LITTLE Rep 9
4 ABOUT RIGHT Dem 22
5 ABOUT RIGHT Ind 37
6 ABOUT RIGHT Rep 17
7 TOO MUCH Dem 13
8 TOO MUCH Ind 22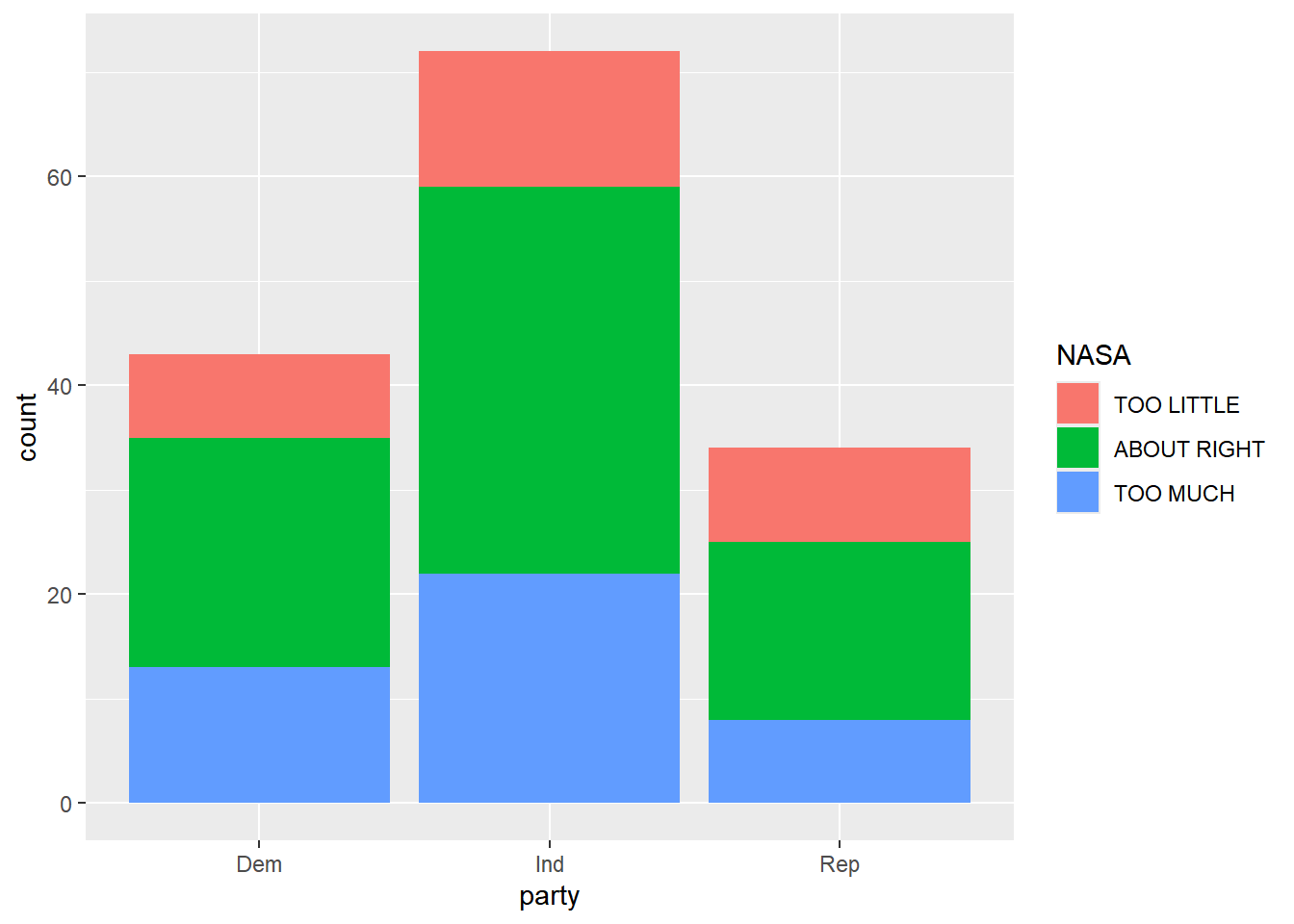
- 设定原假设与备选假设
零假设: 不同党派对预算的态度的构成比(TOO LITTLE, ABOUT RIGHT, TOO MUCH) 没有区别
备选假设:不同党派对预算的态度的构成比(TOO LITTLE, ABOUT RIGHT, TOO MUCH) 存在区别
- 假设检验
Response: NASA (factor)
Explanatory: party (factor)
# A tibble: 1 × 1
stat
<dbl>
1 1.33# 设定原假设
null_dist <- gss |>
specify(NASA ~ party) |>
hypothesise(
null = "independence"
) |>
generate(reps = 5000, type = "permute") |>
calculate(stat = "Chisq") # 卡方检验-分类变量独立性
null_distResponse: NASA (factor)
Explanatory: party (factor)
Null Hypothesis: independence
# A tibble: 5,000 × 2
replicate stat
<int> <dbl>
1 1 2.20
2 2 3.18
3 3 1.49
4 4 1.41
5 5 1.34
6 6 1.12
7 7 3.09
8 8 1.71
9 9 4.19
10 10 3.96
# ℹ 4,990 more rows# 计算p值
null_dist |>
get_p_value(obs_stat = obs_stat, direction = "greater")# A tibble: 1 × 1
p_value
<dbl>
1 0.858# 可视化
null_dist |>
visualise() +
shade_p_value(obs_stat = obs_stat, direction = "right")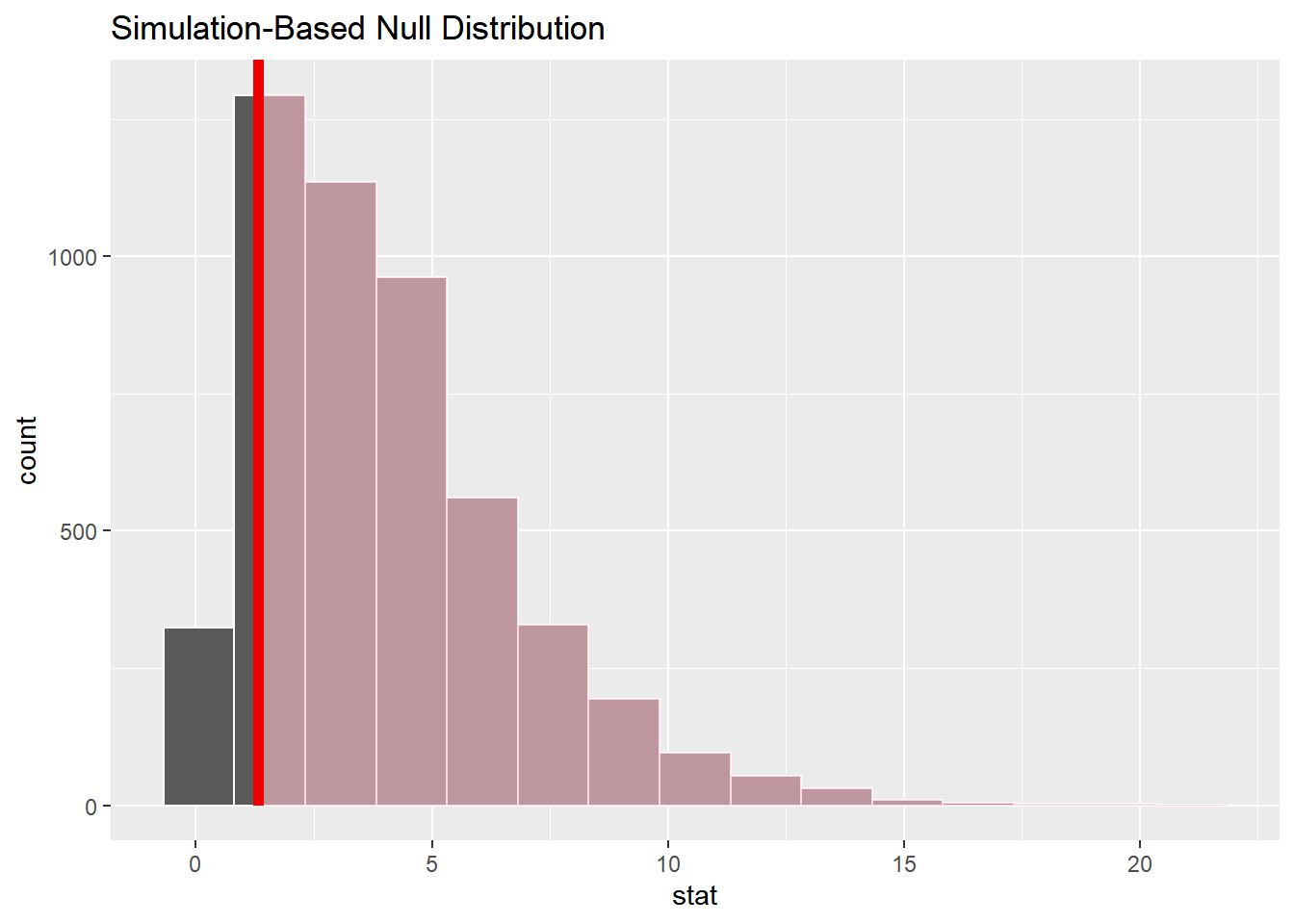
结果显示 \(p{-}value > 0.05\),表示不能拒绝原假设,即没有足够证据证明党派对航天投资有显著影响。
- 置信区间
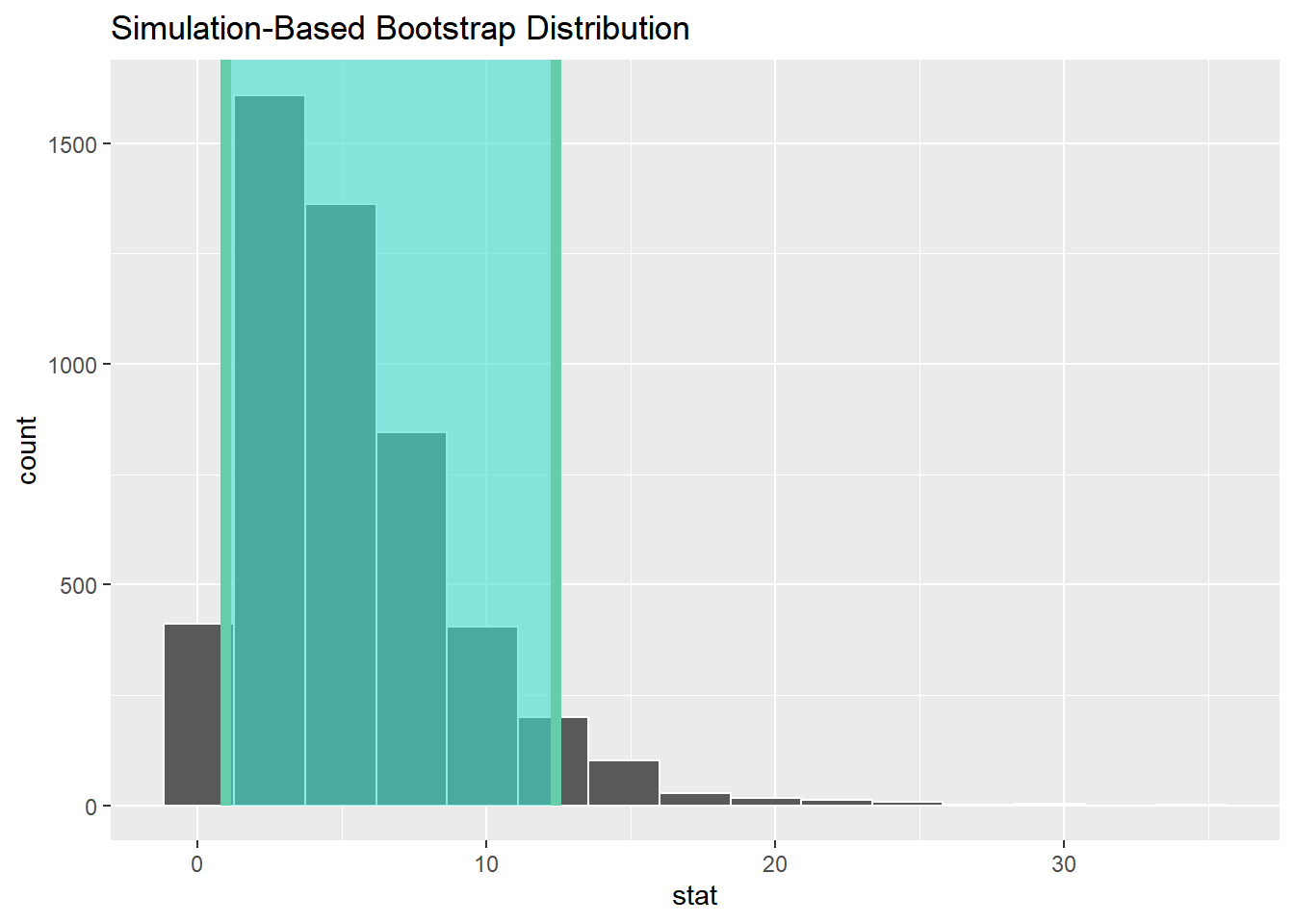
结果显示,不同党派对航天的投资置信区间为 \([0.980, 12.7]\),原始的样本统计量为1.33,包含在置信区间之内,即没有足够证据证明党派对航天投资有显著影响,得出的结论与假设检验一致。