# fmt: skip
df15_1 <- data.frame(
cho = c(
5.68, 3.79, 6.02, 4.85, 4.60, 6.05, 4.90, 7.08, 3.85, 4.65, 4.59, 4.29,
7.97, 6.19, 6.13, 5.71, 6.40, 6.06, 5.09, 6.13, 5.78, 5.43, 6.50, 7.98,
11.54, 5.84, 3.84
),
tg = c(
1.90, 1.64, 3.56, 1.07, 2.32, 0.64, 8.50, 3.00, 2.11, 0.63, 1.97, 1.97,
1.93, 1.18, 2.06, 1.78, 2.40, 3.67, 1.03, 1.71, 3.36, 1.13, 6.21, 7.92,
10.89, 0.92, 1.20
),
ri = c(
4.53, 7.32, 6.95, 5.88, 4.05, 1.42, 12.60, 6.75, 16.28, 6.59, 3.61,
6.61, 7.57, 1.42, 10.35, 8.53, 4.53, 12.79, 2.53, 5.28, 2.96, 4.31,
3.47, 3.37, 1.20, 8.61, 6.45
),
hba = c(
8.2, 6.9, 10.8, 8.3, 7.5, 13.6, 8.5, 11.5, 7.9, 7.1, 8.7, 7.8, 9.9,
6.9, 10.5, 8.0, 10.3, 7.1, 8.9, 9.9, 8.0, 11.3, 12.3, 9.8, 10.5, 6.4, 9.6
),
fpg = c(
11.2, 8.8, 12.3, 11.6, 13.4, 18.3, 11.1, 12.1, 9.6, 8.4, 9.3, 10.6,
8.4, 9.6, 10.9, 10.1, 14.8, 9.1, 10.8, 10.2, 13.6, 14.9, 16.0, 13.2, 20.0, 13.3, 10.4
)
)39 预测数值型数据-回归方法
39.1 简单线性回归
本节我们关注简单线性回归。
简单线性回归的基本表达式如下 式 39.1 ,也可将其描述为Y对X的回归。
\[ Y \approx \beta_0+\beta_1X \tag{39.1}\]
式 39.1 中,\(\beta_0\) 和 \(\beta_1\) 为模型的系数或参数。
提示
在回归模型中: - \(\beta_1\) 的解释为:当其他自变量不变时,自变量x每增加一个单位,因变量y的变化量会变化 \(\beta_1\) 个单位。 - \(\beta_0\) 的解释为:当其他自变量取值为0时,因变量y的值,及因变量y的初始取值。
39.1.1 估计系数
- 残差平方和(
RSS):真实值与预测值之差的平方和。 - 我们希望找到 截距 \(\beta_0\) 和 系数 \(\beta_1\) ,使得RSS达到最小。
- 使用最小二乘法1选择 \(\beta_0\) 和 \(\beta_1\)。计算公式如下 式 39.2。
\[ \begin{align} \hat{\beta_1} &= \frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})}{\sum_{i=1}^n(x_i-\bar{x})^2} \\ \hat{\beta_0} &= \bar{y} - \hat{\beta_1}\bar{x} \end{align} \tag{39.2}\]
式中:\(\bar{y}\) 和 \(\bar{x}\) 分别对应 \(y_i\) 和 \(x_i\) 的样本均值。
39.1.2 评估系数估计值的准确性
样本均值和总体均值的含义不同,但一般的说,样本均值能提供对总体均值的良好估计。
-
我们通常使用标准误差评估样本均值的准确性。如下 式 39.3 所示:
标准误差是标准差的平方的均值。 \[ Var(\hat{\mu}) = SE(\hat{\mu})^2 = \frac{\delta^2}{n} \tag{39.3}\] 式中,\(\delta^2\)为总体方差,\(n\)为样本量。
标准误差体现了估计均值偏离实际均值的平均量。
标准误差可用于计算置信区间。如下 式 39.4 所示,即置信区间为估计值加减标准误差的2倍的值所组成的取值范围。 \[ CI = [\hat{y} \pm 2\times SE(\hat{y})] \tag{39.4}\]
标准误差可以用于假设检验。
通常,总体方差\(\delta^2\)是未知的,可以通过估算得出其估计值,这个估计值叫做残差标准误(RES)。如下 式 39.5 所示,式中RSS为残差平方和。
\[ RSE = \sqrt{\frac{RSS}{n-2}} \tag{39.5}\]
注记
- 一个很小的p值表示在预测变量和响应变量之间真实关系位置的情况下,不太可能完全由于偶然而观察到预测变量和响应变量之间的强关系。即当p值足够小,我们便拒绝零假设,即声明预测变量和响应变量之间存在关系。
- 典型的拒绝零假设的临界p值为0.05和0.1。
零假设是我们希望证实的事件的对立事件,例如我们希望证实一种药对某种症状有效,则零假设应设定为无效。如果p值足够小,则应拒绝零,从而得出实验有效应或统计结果显著的结论
39.1.3 评价模型的准确性
- 判断线性回归拟合效果(模型准确性)通常用到两个量,即上一节提到的残差标准误( 式 39.5 )和 \(R^2\) 统计量。
- 残差标准误度量了模型失拟(lack of fit)的程度,RSE越小,模型拟合效果越好。
- \(R^2\) 统计量取值在[0,1]之间,越接近1,则表示模型拟合结果越好。此外,\(R^2\) 统计量也描述了预测变量和响应变量间的相关性,事实上在简单线性回归中,\(R^2\) 统计量和相关系数 \(r^2\) 是相等的。在R的模型拟合过程中,\(R^2\) 统计量通常会直接在结果中给出。
39.2 多元线性回归
39.2.1 一些重要问题
-
预测变量 \(X_1, X_2,...,X_p\) 中是否至少有一个可以用来预测响应变量?(响应变量与预测变量间是否存在关系?)
- 多元回归分析的第一步是计算\(F统计量\)并检查其p值。
- 多元统计分析中使用\(F统计量\)及其p值断定响应变量与预测变量间是否存在关系。
- 一个较大的\(F统计量\)值(远大于1),可以一定程度上说明至少一个预测变量与响应变量有关。
- 当\(F统计量\)接近1时,我们需要结合其p值进行判断,当p值足够小时,也可推断至少一个预测变量与响应变量有关。
- 在多元回归中,\(F统计量\)是t检验和p值的重要补充。
-
是否所有预测变量均有助于解释响应变量?(选定重要变量)
- 并非所有的预测变量均与响应变量密切相关。
- 有3种不同的方法筛选更优、更少的初始模型(即选定重要变量)
- 向前选择:从初始模型2开始,把RSS最小的变量逐一加入模型,直到满足某种规则时停止。
- 向后选择:先从包含所有变量的模型开始,逐一删除p值最大的变量(即统计学上最不显著的变量),直到剩余变量的p值均低于某个阈值为止。注意,当预测变量数p>响应变量数(观测数)n时,不能使用向后选择;向前选择不受此约束。
- 混合选择:即向前和向后两种选择方法的结合。从初始模型开始,依次增加变量,当变量增加时,已有变量的p值也会随之变化(增加或减少);一旦模型中某个变量的p值超过一定阈值,就执行向后选择,即从模型中删除该变量,然后继续向前选择的过程。不断交替执行这些步骤,直到模型所有变量的p值都足够低且新加入模型的变量的p值都较大时,停止。
- 模型对数据拟合的程度如何?(模型拟合)
- 常见的衡量模型拟合优劣的指标是\(RSE\)(残差标准误, 式 39.5) 和 \(R^2\)。
- 给定一组预测变量的值,响应值应预测为多少?预测的准确程度如何?(预测)
- 通过计算置信区间确定预测值和真实值的接近程度。如95%的置信区间可解释为,模型预测值有95%的概率包含了真实值。
39.3 其他潜在问题
39.3.1 数据非线性
线性回归模型假定预测与响应变量之间存在线性关系,但如果它们间的真实关系不是线性的,我们得出的结论就完全不可信了。残差2图是一种可以用于识别非线性的、十分有用的图形工具。
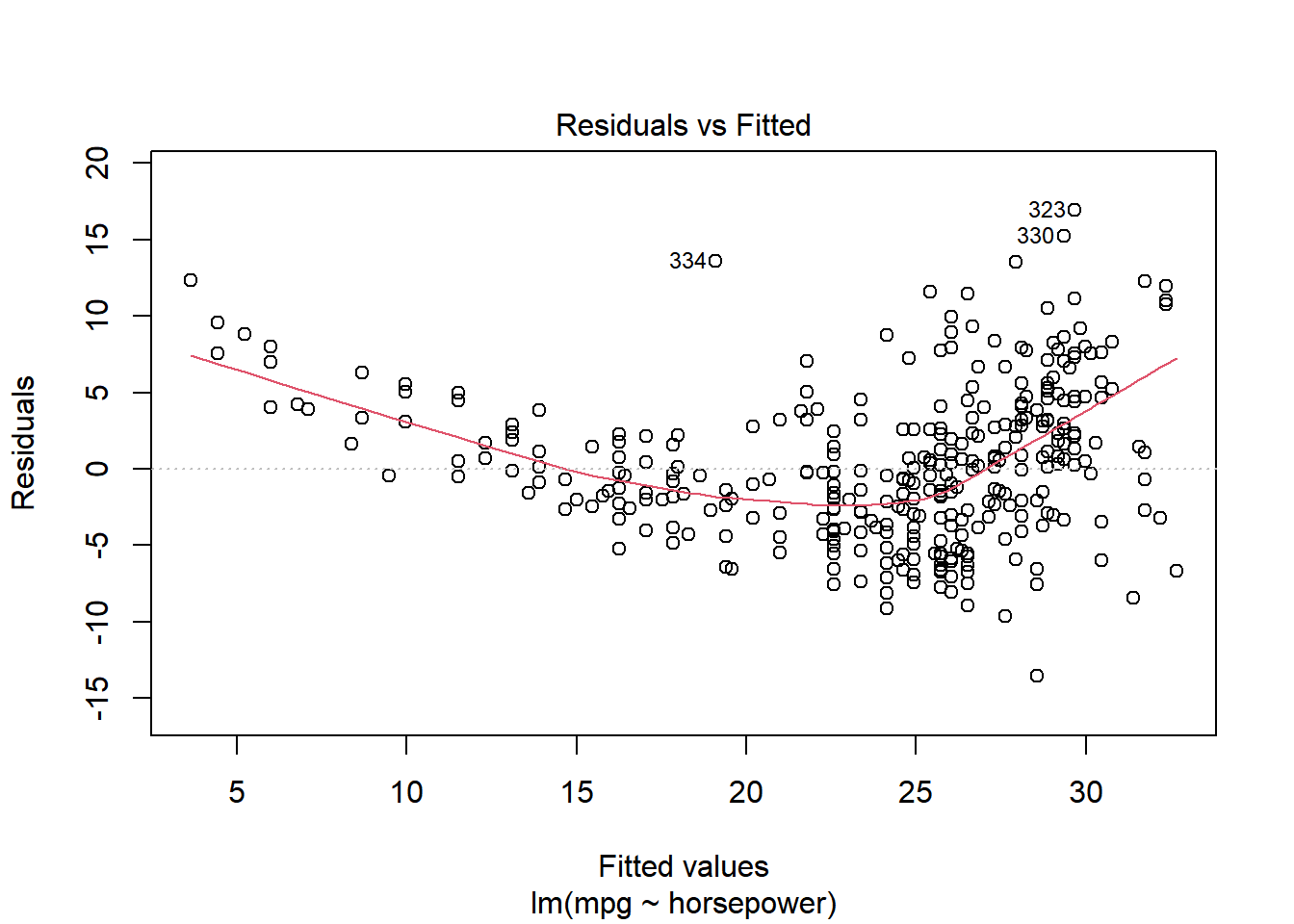
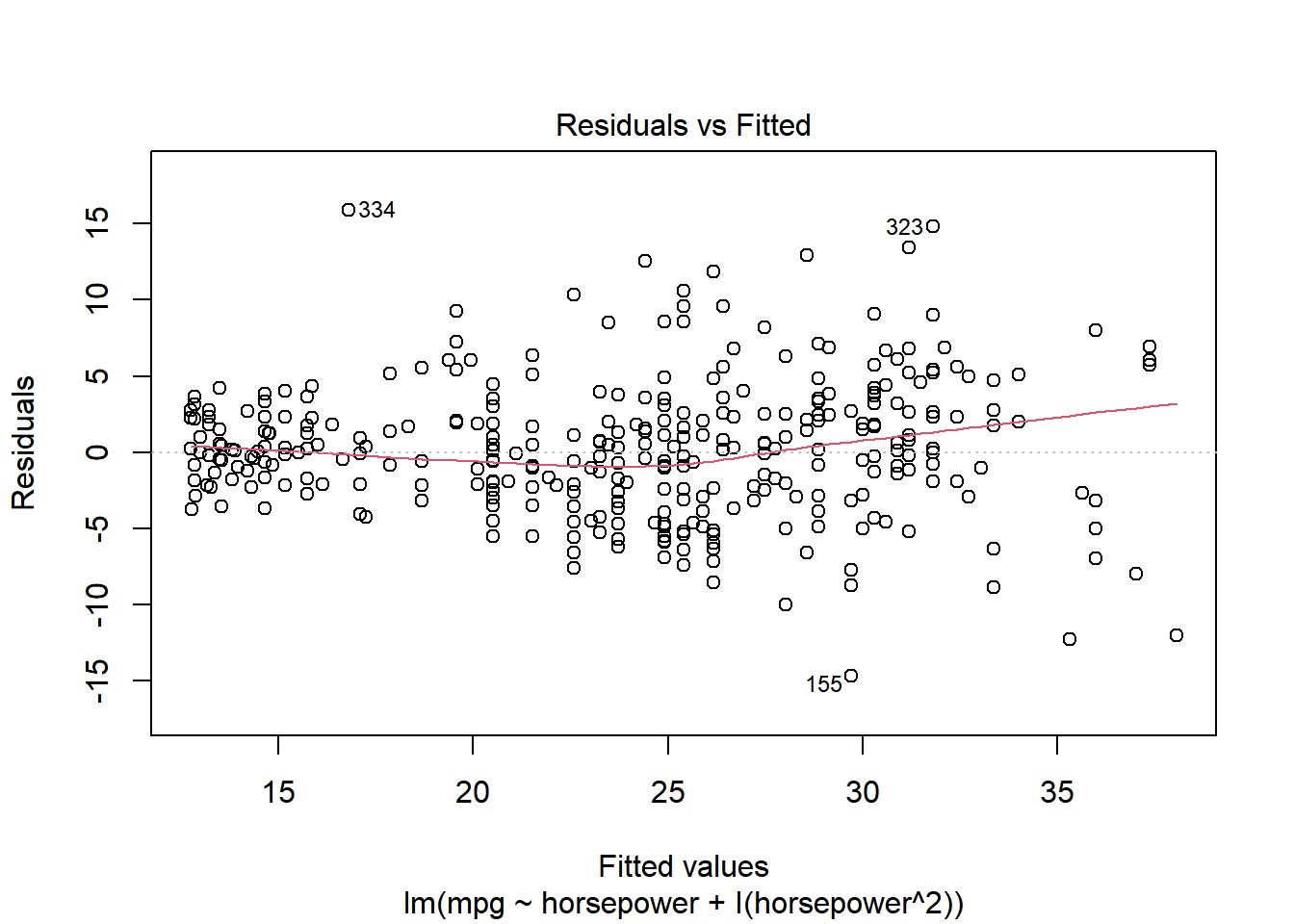
理想情况下,残差图不会显示出明显的规律,如果存在明显规律,则表示线性模型的某一方面可能存在问题。图 39.1 中, 图 39.1 (a) 为线性回归模型拟合后的残差图,可以看出明显呈现一个U字形的形状(存在规律),而 图 39.1 (b) 中加入了二次项,残差图则没有明显的规律,这表明在加入二次项后,模型的拟合度有了较好的提升。
在发现数据呈现非线性时,一种简单的操作就是加对预测变量进行非线性转化,比如 \(X^2\)、\(logX\)、\(\sqrt{X}\)等。之后我们会讨论更先进的非线性方法。
39.3.2 离群点和高杠杆点
离群点是因变量y的异常值,残差图可以识别离群点。
值得注意的是,离群点也可能在提醒我们所建立的模型存在缺陷,例如缺少预测变量等。
高杠杆点与离群点相反,是自变量x的异常值。
39.3.3 共线性
- 共线性是指两个或多个自变量之间存在高度相关性,导致回归方程的估计不准确。
- 多重共线性:指三个或多个自变量之间存在高度相关性,导致回归方程的估计不准确,且相关性随着自变量的增加而增大。
- 解决共线性的方法有多种,如:
- 变量筛选:删除高度相关的变量,保留相关性较低的变量。
- 变量变换:将高度相关的变量进行变换,如log变换、平方根变换等。
- 多元回归:在回归方程中加入更多的预测变量,以减少共线性的影响。、
39.3.4 回归诊断
判断数据是否满足多元线性回归的条件,也就是 4 个条件:
- 正态性
- 独立性
- 等方差性
- 线性
以上4个条件可以通过回归诊断图来判断。

上图就是一个典型的回归诊断图,我们分别来看:
- 左上图(残差拟合图):展示真实残差和拟合残差的关系,是判断是否满足线性这个条件,如果满足,残差拟合图应该呈现一条直线,本图中,残差拟合图呈现出了一条曲线,说明模型不满足线性这个条件,可能需要加入二次项对模型进行调整。
- 右上图(正态Q-Q图):判断是否满足正态性这个条件,如果点大致分布在一条直线上,说明残差近似服从正态分布,满足正态性假设。
- 左下图(位置尺度图):判断是否满足同(等)方差性,如果水平线两侧的点大致随机分布,则说明模型满足同方差性假设。
- 右下图(残差杠杆图):用于识别离群点。如果某个点的杠杆值很高并且对应的残差值也很大,那么这个点可能是异常值或者对模型的拟合结果有较大影响的点。
39.4 线性回归实验-传统方法
39.4.1 建立模型
数据一共 5 列,第 1 列是总胆固醇,第 2 列是甘油三酯,第 3 列是胰岛素,第 4 列是糖化血红蛋白,第 5 列是空腹血糖(因变量)。
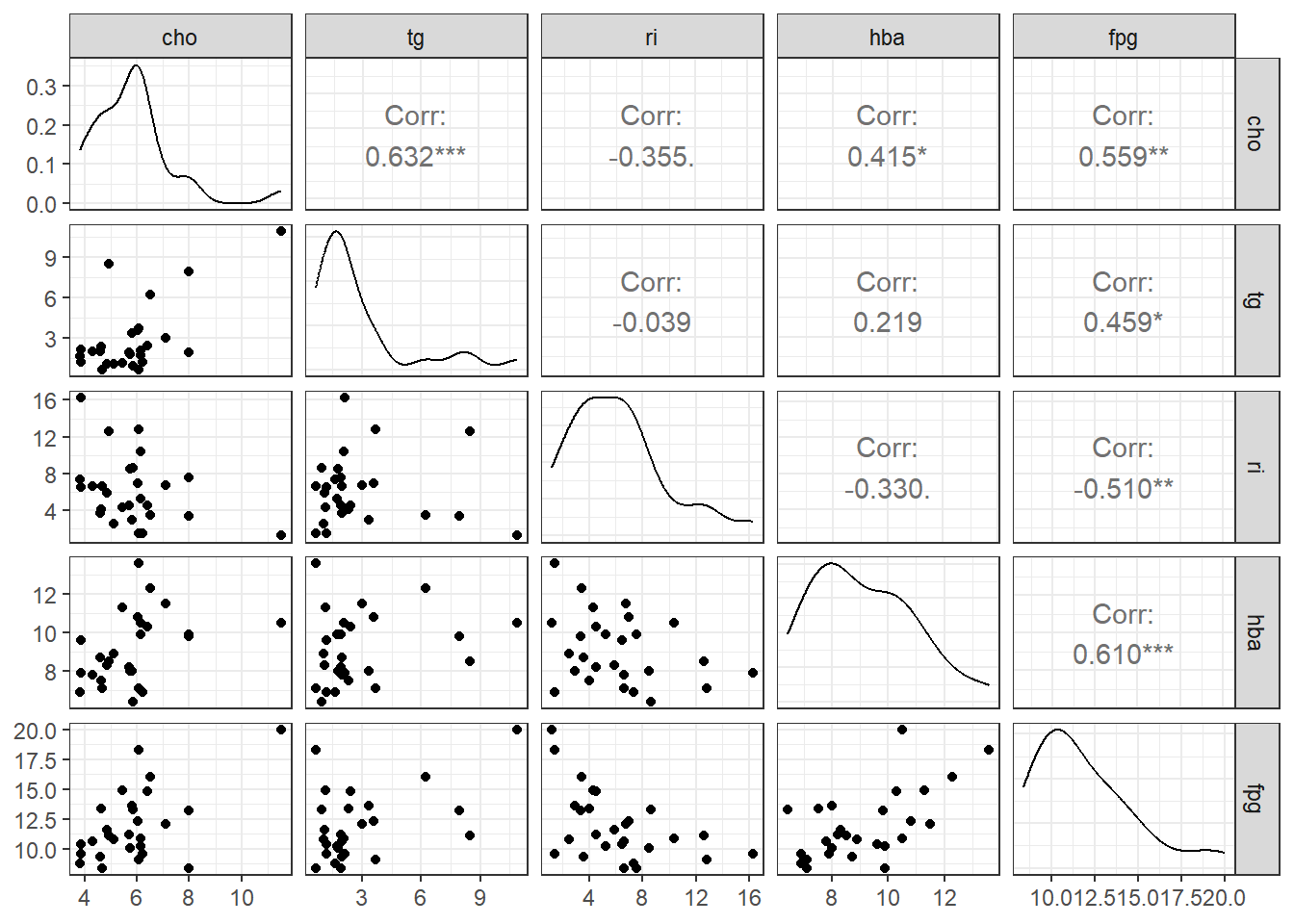
由图中可知,血糖和糖化血红蛋白相关性最大,和甘油三酯相关性最小。
Call:
lm(formula = fpg ~ cho + tg + ri + hba, data = df15_1)
Residuals:
Min 1Q Median 3Q Max
-3.6268 -1.2004 -0.2276 1.5389 4.4467
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.9433 2.8286 2.101 0.0473 *
cho 0.1424 0.3657 0.390 0.7006
tg 0.3515 0.2042 1.721 0.0993 .
ri -0.2706 0.1214 -2.229 0.0363 *
hba 0.6382 0.2433 2.623 0.0155 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.01 on 22 degrees of freedom
Multiple R-squared: 0.6008, Adjusted R-squared: 0.5282
F-statistic: 8.278 on 4 and 22 DF, p-value: 0.0003121输出的结果很丰富,包括截距,各自变量的系数及标准误、t统计量、p值,最下方给出了决定系数、调整后的决定系数,f统计量以及总体模型的p值。
39.4.2 模型评价
回归模型可以通过 \(R^2\)、AIC(衡量模型拟合有良性)、BIC(用于模型选择)、RMSE 等评价,\(R^2\) 范围在 0~1 之间,越接近 1 说明结果越好。AIC、BIC、RMSE 是越小越好。
BIC相比AIC在大数据量时对模型参数惩罚得更多,导致BIC更倾向于选择参数少的简单模型
library(performance)
model_performance(f) # 直接输出所有结果# Indices of model performance
AIC | AICc | BIC | R2 | R2 (adj.) | RMSE | Sigma
---------------------------------------------------------
120.8 | 125.0 | 128.6 | 0.601 | 0.528 | 1.814 | 2.01039.4.3 回归诊断
回归诊断图可以帮助我们更直观地判断模型是否满足假设。
- 传统上,可以直接使用
plot()函数绘制回归诊断图,图形较为简陋。 -
performance包提供了一些函数,可以直接输出回归诊断图。
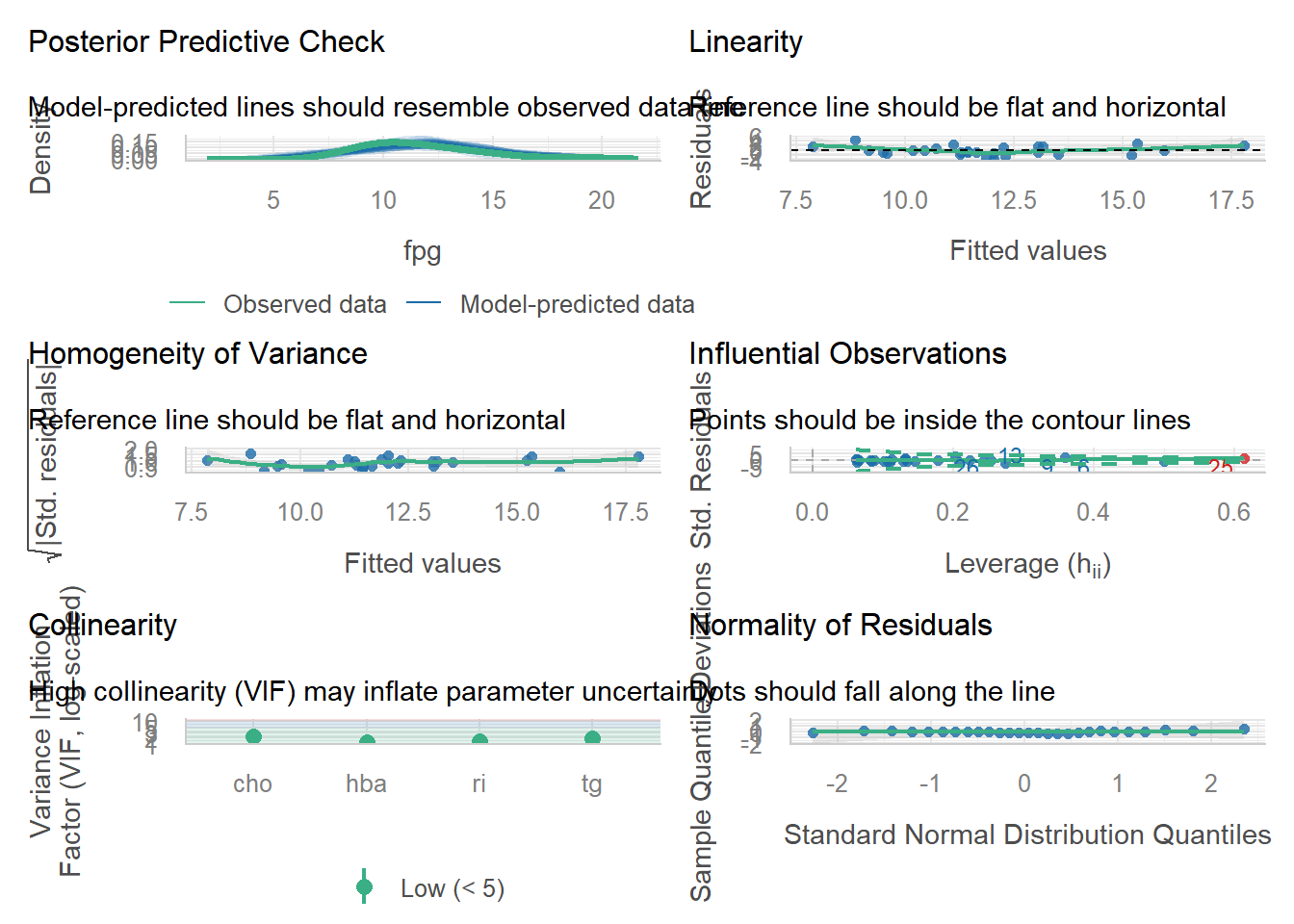
- 首先看第一个图。这个图是基于 check_predictions()函数的,属于事后检验,是检查 真实数据和模型数据的拟合情况的。下图中绿色粗线是真实的预测变量的分布情况,蓝色线条表示模拟的分布,理想的情况应该是完全重合的。从下图来看,其实是有些问题的,这说明我们用的模型可能不太合适。
- 第 2 张图。这张图是检查预测变量和结果变量是否符合线性关系的。合理的情 况是残差完全随机地分布在参考线两侧。从这张图来看我们的数据其实不太完美。
- 第 3 幅图,是用来检查方差齐性的,如果满足,参考线两侧的点应该随机分布,从此图来看基本满足。
- 第 4 幅图是用来观察强影响点或者离群值、异常值的。使用的是库克距离(cook’s distance)来计算的,图中在虚线(库克距离)外的点可被认为是异常值。
- 第 5 幅图是关于多重共线性的。是通过方差膨胀因子来评价的,下图中展示了 4 个变 量的 VIF (膨胀因子),基本都在 3 以下,可认为不存在多重共线性。
- 第 6 幅图是看正态性的。理想情况下数据点应该均匀的分布在横线上,最好是和横线重合(尤其是尾部)。从图中来看,数据点基本符合正态分布。
39.5 线性回归实验-tidymodels
39.5.1 简单线性回归
Boston数据集包含506个样本,每个样本有13个特征。我们将建立一个简单的线性回归模型,将业主自助房屋的中位数价格medv作为因变量,将表示属于较低社会地位的人口百分比lstat作为自变量。
重要
Boston数据集其实相当过时,其中包含了一些不太重要的特征,如tax、ptratio等,这些特征对预测房价没有太大影响。在实际应用中,我们通常会选择更加重要的特征进行建模。
- 使用
parsnip建立线性回归模型,注意,这一步并不产生任何计算,可以理解为定义了模型的操作框架。
Linear Regression Model Specification (regression)
Computational engine: lm - 使用公式或变量拟合模型。拟合的结果是一个
parsnip 模型对象,包含了拟合的结果和一些其他信息。
lm_fit <- lm_spec |>
fit(medv ~ lstat, data = Boston)
lm_fitparsnip model object
Call:
stats::lm(formula = medv ~ lstat, data = data)
Coefficients:
(Intercept) lstat
34.55 -0.95 - 查看模型拟合信息
Call:
stats::lm(formula = medv ~ lstat, data = data)
Coefficients:
(Intercept) lstat
34.55 -0.95
Call:
stats::lm(formula = medv ~ lstat, data = data)
Residuals:
Min 1Q Median 3Q Max
-15.168 -3.990 -1.318 2.034 24.500
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 34.55384 0.56263 61.41 <2e-16 ***
lstat -0.95005 0.03873 -24.53 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.216 on 504 degrees of freedom
Multiple R-squared: 0.5441, Adjusted R-squared: 0.5432
F-statistic: 601.6 on 1 and 504 DF, p-value: < 2.2e-16# 整洁格式输出模型结果-tidy()
lm_fit %>% tidy()# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 34.6 0.563 61.4 3.74e-236
2 lstat -0.950 0.0387 -24.5 5.08e- 88# 提取模型统计信息-glance()
lm_fit %>% glance()# A tibble: 1 × 12
r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.544 0.543 6.22 602. 5.08e-88 1 -1641. 3289. 3302.
# ℹ 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>- 预测
predict(lm_fit, new_data = Boston)# A tibble: 506 × 1
.pred
<dbl>
1 29.8
2 25.9
3 30.7
4 31.8
5 29.5
6 29.6
7 22.7
8 16.4
9 6.12
10 18.3
# ℹ 496 more rows# 通过指定type参数,可以指定预测值的类型,如预测值、置信区间、预测残差等。
predict(lm_fit, new_data = Boston, type = "conf_int") # 置信区间# A tibble: 506 × 2
.pred_lower .pred_upper
<dbl> <dbl>
1 29.0 30.6
2 25.3 26.5
3 29.9 31.6
4 30.8 32.7
5 28.7 30.3
6 28.8 30.4
7 22.2 23.3
8 15.6 17.1
9 4.70 7.54
10 17.7 18.9
# ℹ 496 more rows- 比较模型预测值和真实值
# A tibble: 506 × 2
medv .pred
<dbl> <dbl>
1 24 29.8
2 21.6 25.9
3 34.7 30.7
4 33.4 31.8
5 36.2 29.5
6 28.7 29.6
7 22.9 22.7
8 27.1 16.4
9 16.5 6.12
10 18.9 18.3
# ℹ 496 more rows# A tibble: 506 × 3
medv .pred .resid
<dbl> <dbl> <dbl>
1 24 29.8 -5.82
2 21.6 25.9 -4.27
3 34.7 30.7 3.97
4 33.4 31.8 1.64
5 36.2 29.5 6.71
6 28.7 29.6 -0.904
7 22.9 22.7 0.155
8 27.1 16.4 10.7
9 16.5 6.12 10.4
10 18.9 18.3 0.592
# ℹ 496 more rows39.5.2 多元线性回归
多元线性回归与简单线性回归一样,只是在指定变量时,需要指定多个自变量。
parsnip model object
Call:
stats::lm(formula = medv ~ ., data = data)
Coefficients:
(Intercept) crim zn indus chas nox
3.646e+01 -1.080e-01 4.642e-02 2.056e-02 2.687e+00 -1.777e+01
rm age dis rad tax ptratio
3.810e+00 6.922e-04 -1.476e+00 3.060e-01 -1.233e-02 -9.527e-01
black lstat
9.312e-03 -5.248e-01 # 提取模型参数
tidy(lm_fit2)# A tibble: 14 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 36.5 5.10 7.14 3.28e-12
2 crim -0.108 0.0329 -3.29 1.09e- 3
3 zn 0.0464 0.0137 3.38 7.78e- 4
4 indus 0.0206 0.0615 0.334 7.38e- 1
5 chas 2.69 0.862 3.12 1.93e- 3
6 nox -17.8 3.82 -4.65 4.25e- 6
7 rm 3.81 0.418 9.12 1.98e-18
8 age 0.000692 0.0132 0.0524 9.58e- 1
9 dis -1.48 0.199 -7.40 6.01e-13
10 rad 0.306 0.0663 4.61 5.07e- 6
11 tax -0.0123 0.00376 -3.28 1.11e- 3
12 ptratio -0.953 0.131 -7.28 1.31e-12
13 black 0.00931 0.00269 3.47 5.73e- 4
14 lstat -0.525 0.0507 -10.3 7.78e-23# 预测
predict(lm_fit2, new_data = Boston)# A tibble: 506 × 1
.pred
<dbl>
1 30.0
2 25.0
3 30.6
4 28.6
5 27.9
6 25.3
7 23.0
8 19.5
9 11.5
10 18.9
# ℹ 496 more rows39.5.3 交互项
交互项可以在拟合模型时直接指定,但有时我们交互项可以作为预处理步骤的一部分,tidymodels中,使用step_interact()函数来指定交互项。
══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
1 Recipe Step
• step_interact()
── Model ───────────────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm lm_wf_interact %>%
# 将交互项置入`recipe`对象中,可以在拟合模型时不再指定变量或公式。
fit(data = Boston)══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
1 Recipe Step
• step_interact()
── Model ───────────────────────────────────────────────────────────────────────
Call:
stats::lm(formula = ..y ~ ., data = data)
Coefficients:
(Intercept) lstat age lstat_x_age
36.0885359 -1.3921168 -0.0007209 0.0041560 39.5.4 更多的预处理步骤
使用recipe包中的step_log()、step_sqrt()等函数可以对预测变量进行非线性变换。具体可参看recipe中提供的预处理步骤函数。