library(tidyverse)
library(palmerpenguins) # 提供示例数据集
# library(ggtheme) # 提供ggplot2主题1 数据可视化
1.1 引言
绘制图形是数据分析最引人入胜的环节之一,图形也更容易让人产生兴趣。通过图形,我们可以快速了解数据的结构、发现异常值和模式,并传达我们的发现。所以,从可视化出发学习数据科学是一个很好的切入点。
ggplot2是R语言中最流行的数据可视化包之一。它基于“图形语法”(Grammar of Graphics)的理念,允许用户通过分层的方式构建复杂的图表。
我们从一个问题出发:penguins数据集中,企鹅的脚蹼长度和体重之前的关系是怎样的?这种关系是否因企鹅的种类而异?是否与地理位置有关?
在可视化之前,对数据的初步了解很重要,我更习惯使用glimpse()函数对数据集进行总体的了解。
glimpse(penguins)Rows: 344
Columns: 8
$ species <fct> Adelie, Adelie, Adelie, Adelie, Adelie, Adelie, Adel…
$ island <fct> Torgersen, Torgersen, Torgersen, Torgersen, Torgerse…
$ bill_length_mm <dbl> 39.1, 39.5, 40.3, NA, 36.7, 39.3, 38.9, 39.2, 34.1, …
$ bill_depth_mm <dbl> 18.7, 17.4, 18.0, NA, 19.3, 20.6, 17.8, 19.6, 18.1, …
$ flipper_length_mm <int> 181, 186, 195, NA, 193, 190, 181, 195, 193, 190, 186…
$ body_mass_g <int> 3750, 3800, 3250, NA, 3450, 3650, 3625, 4675, 3475, …
$ sex <fct> male, female, female, NA, female, male, female, male…
$ year <int> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007…penguins数据集共有344行,8列,针对提出的问题,我们关心的变量有以下4个:
-
species:企鹅的种类名称。 -
flipper_length_mm:企鹅的脚蹼长度。 -
body_mass:企鹅的体重(g)。 -
island:企鹅所生活的岛屿。
本章我们重点关注如果使用ggplot2绘制图形,即ggplot()函数两个最重要的参数data和mapping,以及根据变量类型的不同绘制一些常用图形(小节 1.2 和 小节 1.3)。 更多的其他方面的细节将在 章节 5 会对ggplot2的主要组成部分进行详细介绍,在 附录 C 会对ggplot2的主题风格设置进行详细介绍。
值得注意的是,虽然
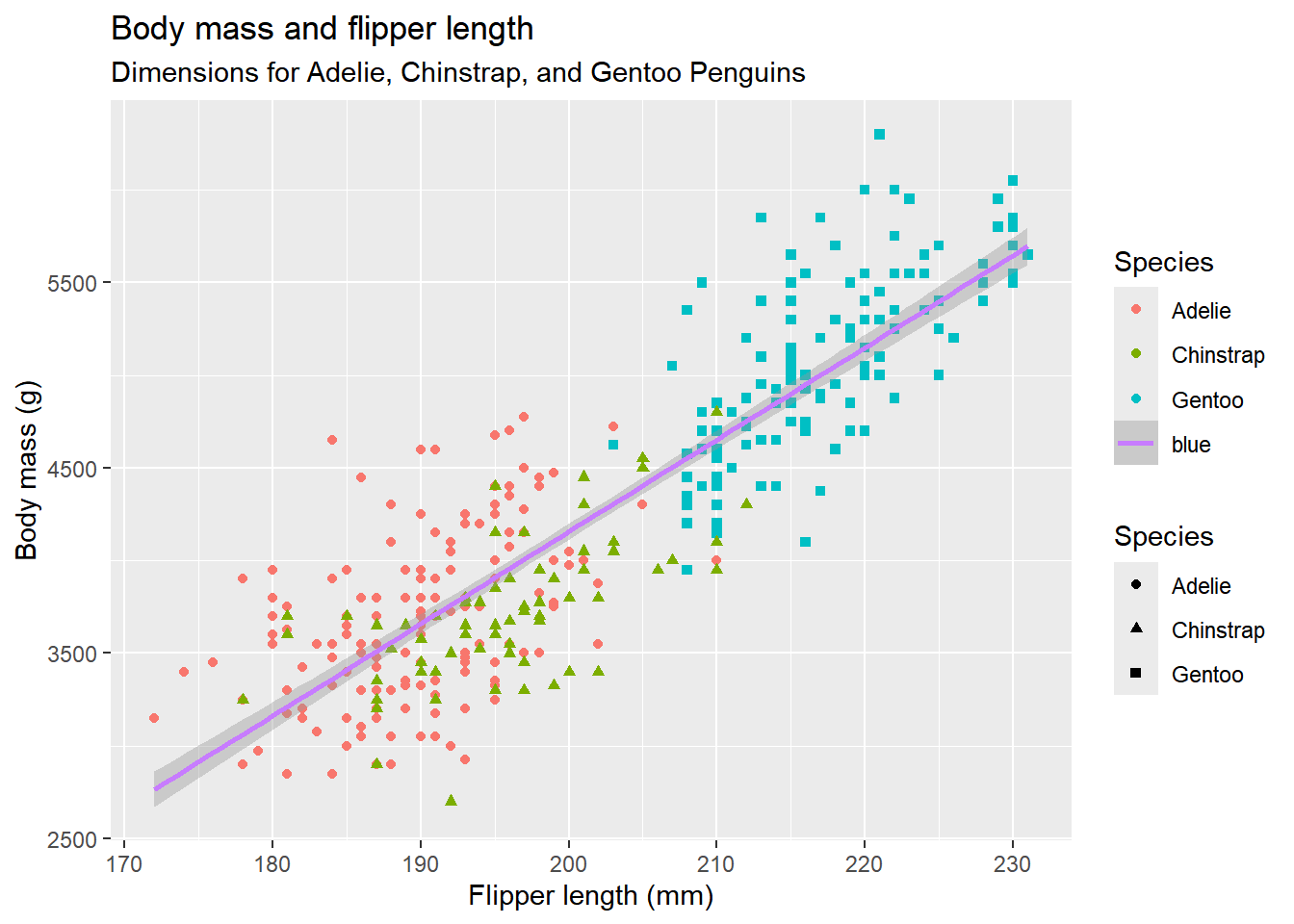
data和mapping是两个最重要的参数,但在调用ggplot()时候,它们是可以省略的。以下代码展示了如何使用ggplot2绘制企鹅脚蹼长度和体重之间关系的散点图,并根据企鹅的种类进行颜色区分。
ggplot(
# "data =" 以及 "mapping = `的部分可以省略
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g, color = "blue")
) +
geom_point(mapping = aes(color = species, shape = species)) +
geom_smooth(method = "lm") +
labs(
title = "Body mass and flipper length",
subtitle = "Dimensions for Adelie, Chinstrap, and Gentoo Penguins",
x = "Flipper length (mm)",
y = "Body mass (g)",
color = "Species",
shape = "Species"
)
1.2 变量分布的可视化
1.2.1 单个类别变量
检查单个类别变量的分布时,通常使用条形图(bar chart)。
针对类别变量的绘图,我们经常需要对类别变量按频率进行排序,从而使得条形图更具可读性。关于如何对类别变量(通常为因子类型)进行排序,可以参考 章节 11 中的内容。
ggplot(penguins, aes(x = fct_infreq(species))) + # 按频率排序
geom_bar()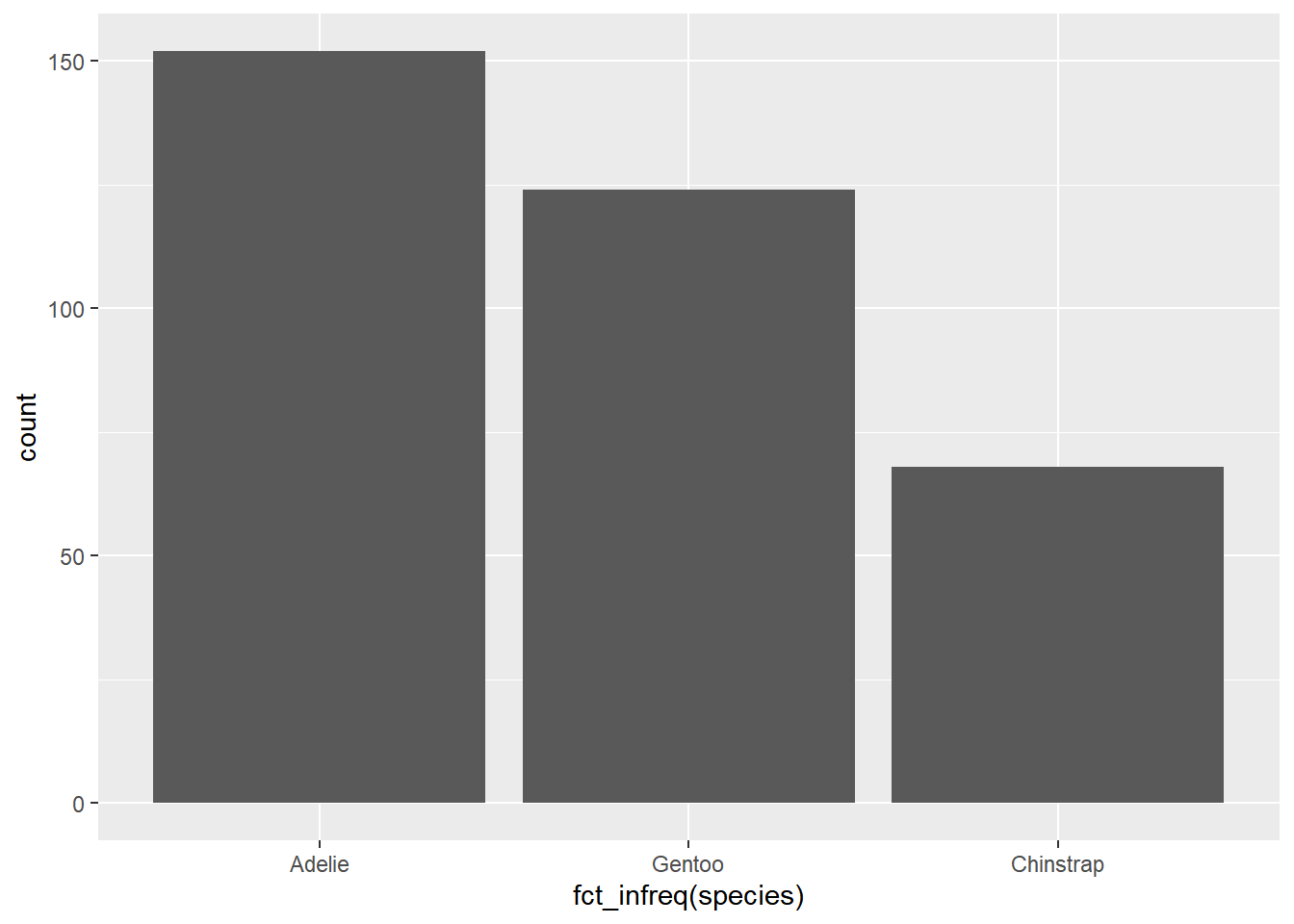
1.2.2 单个数值变量
检查单个数值变量的分布时,通常使用直方图(histogram)或密度图(density plot)。
- 直方图通过将数值变量划分为多个区间(bin),并统计每个区间内的观测值数量来展示分布情况。
- 下图中,我们使用直方图来展示企鹅体重的分布情况:最高的柱状显示有 39 个观测值的重量在 3,500 至 3,700 克之间,这是柱状图的左右边缘。
ggplot(penguins, aes(x = body_mass_g)) +
geom_histogram(bindwidth = 200)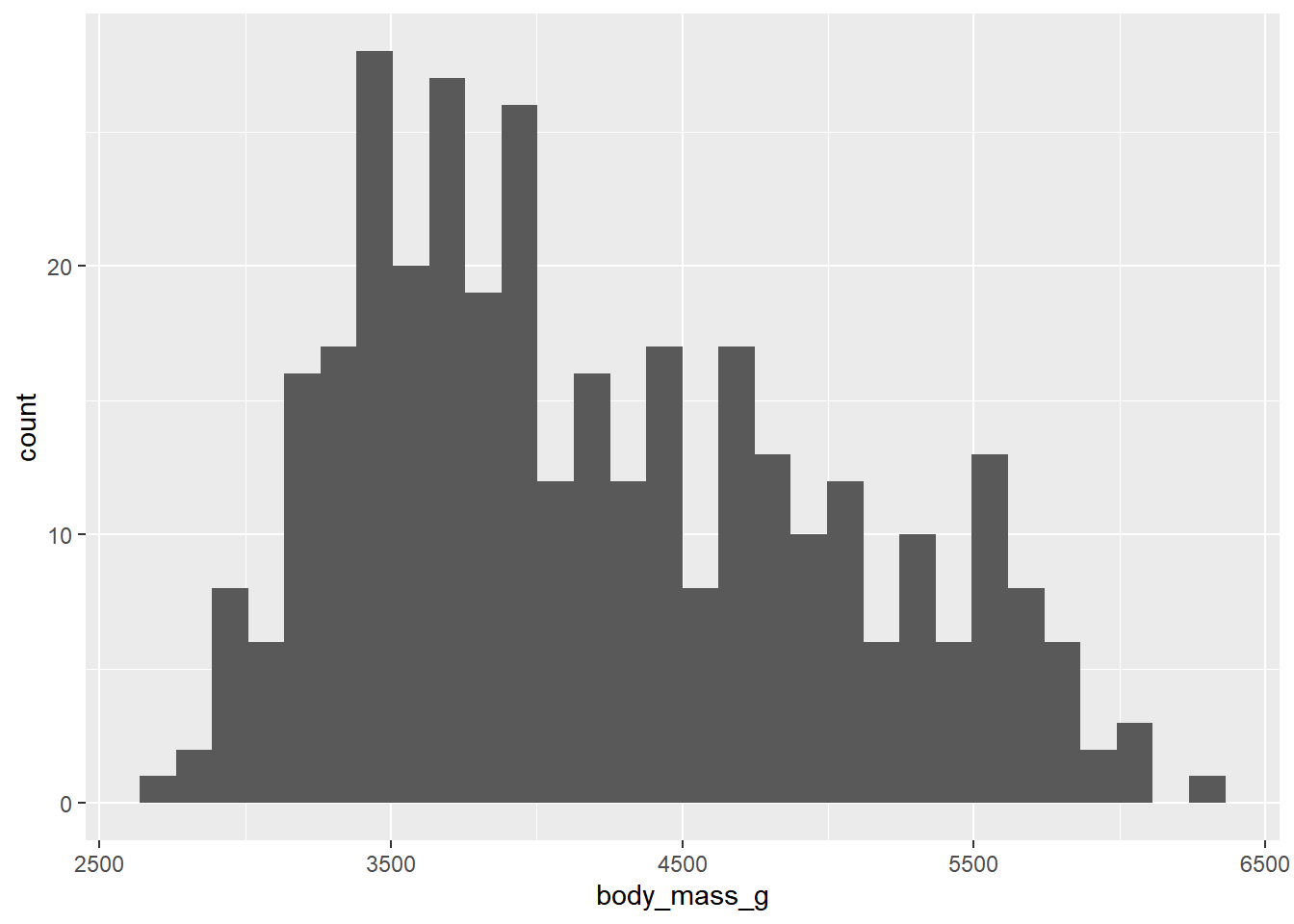
- 密度图则通过估计数值变量的概率密度函数来展示分布情况,密度图可理解为是直方图的平滑版本。
- 下图中,我们使用密度图来展示企鹅体重的分布情况:相比于直方图,密度图虽然展示的细节比直方图更少,但更适合展示数据的整体趋势。
ggplot(penguins, aes(x = body_mass_g)) +
geom_density()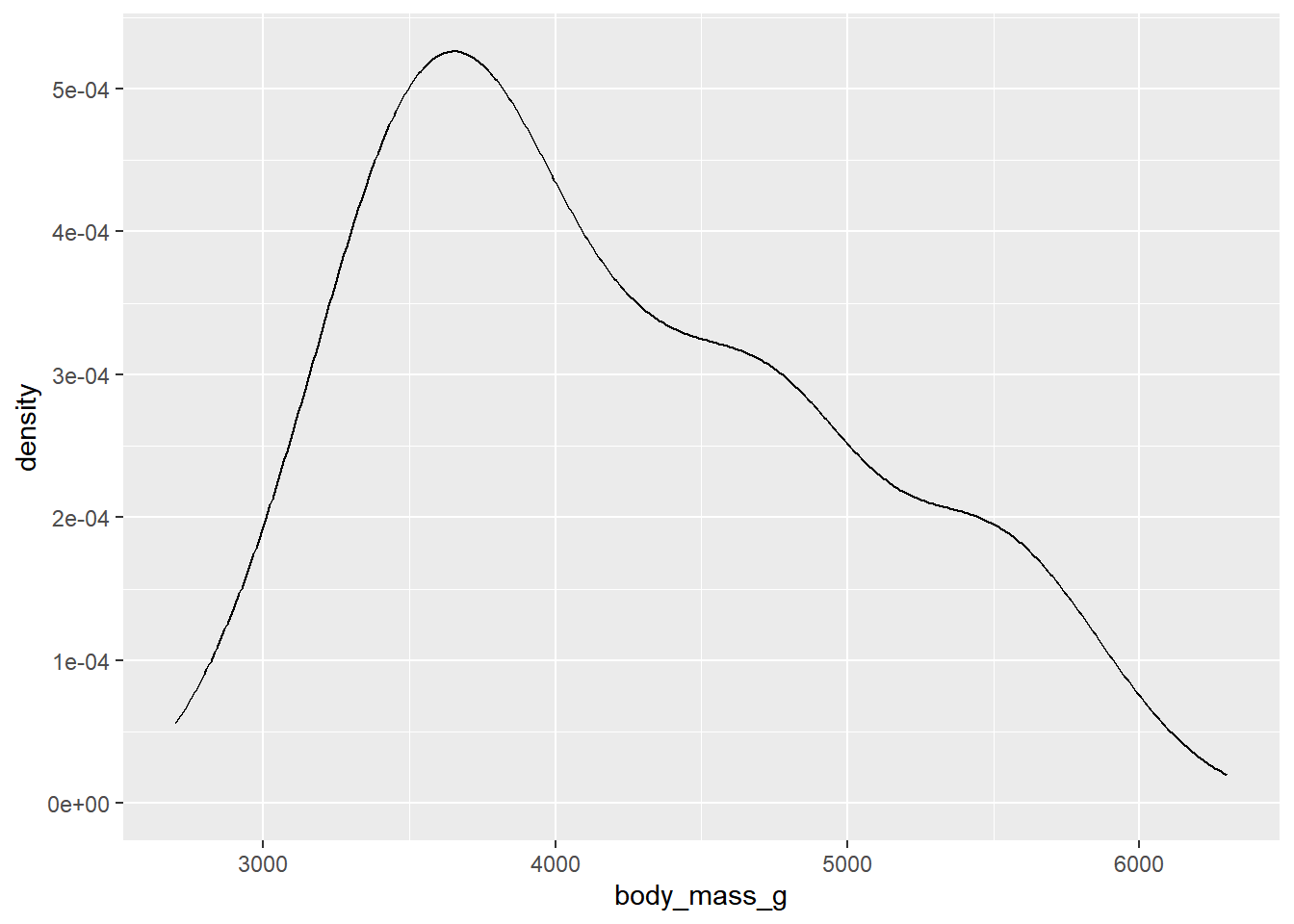
1.3 变量关系的可视化
1.3.1 一个数值变量 vs 一个类别变量
当我们想要展示一个数值变量在不同类别变量下的分布情况时,通常使用箱线图(box plot)或小提琴图(violin plot)。
箱线图通过显示数值变量的中位数、四分位数和异常值来展示分布情况。
下图中,我们使用箱线图来展示不同种类企鹅的体重分布情况:每个箱子显示了该种类企鹅体重的中位数和四分位数,每个箱子两端延伸出一条线,分别延伸至数据分布中最远的非异常点。
通常为1.5倍四分位距的距离
ggplot(penguins, aes(x = species, y = body_mass_g, fill = species)) +
geom_boxplot()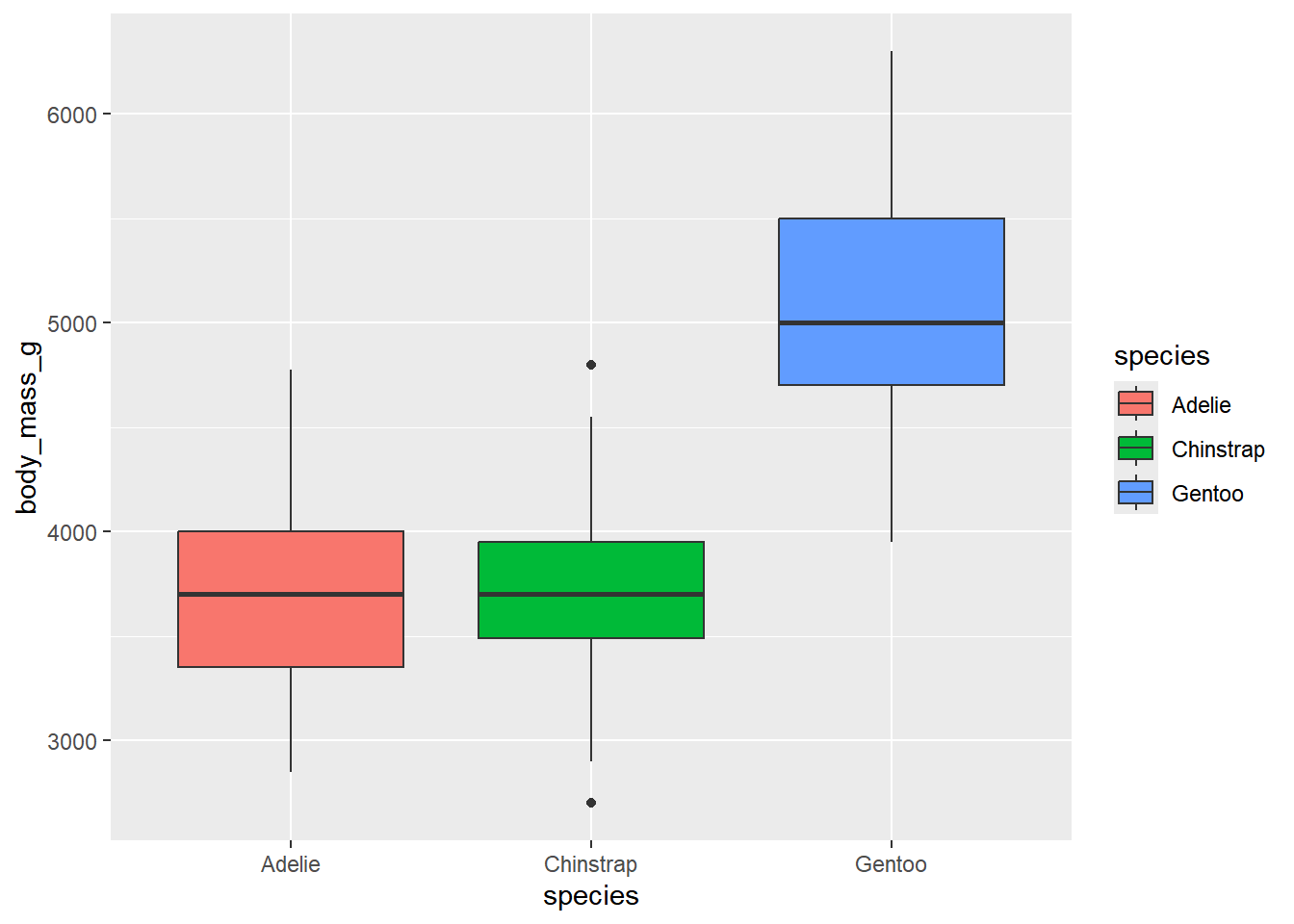
警告
我们将变量映射到美学上,如果我们希望该美学所表示的视觉属性根据该变量的值而变化。 例如,在上图中,我们将
species变量映射到fill美学上,使得不同种类的企鹅在箱线图中显示为不同的填充颜色。如果我们希望该视觉属性保持不变,则不应将变量映射到该美学上。 例如,如果我们希望所有箱线图都显示为蓝色填充,则应将
fill美学设置为常量值"blue",而不是映射到变量species上。
ggplot(penguins, aes(x = species, y = body_mass_g)) +
geom_boxplot(fill = "blue")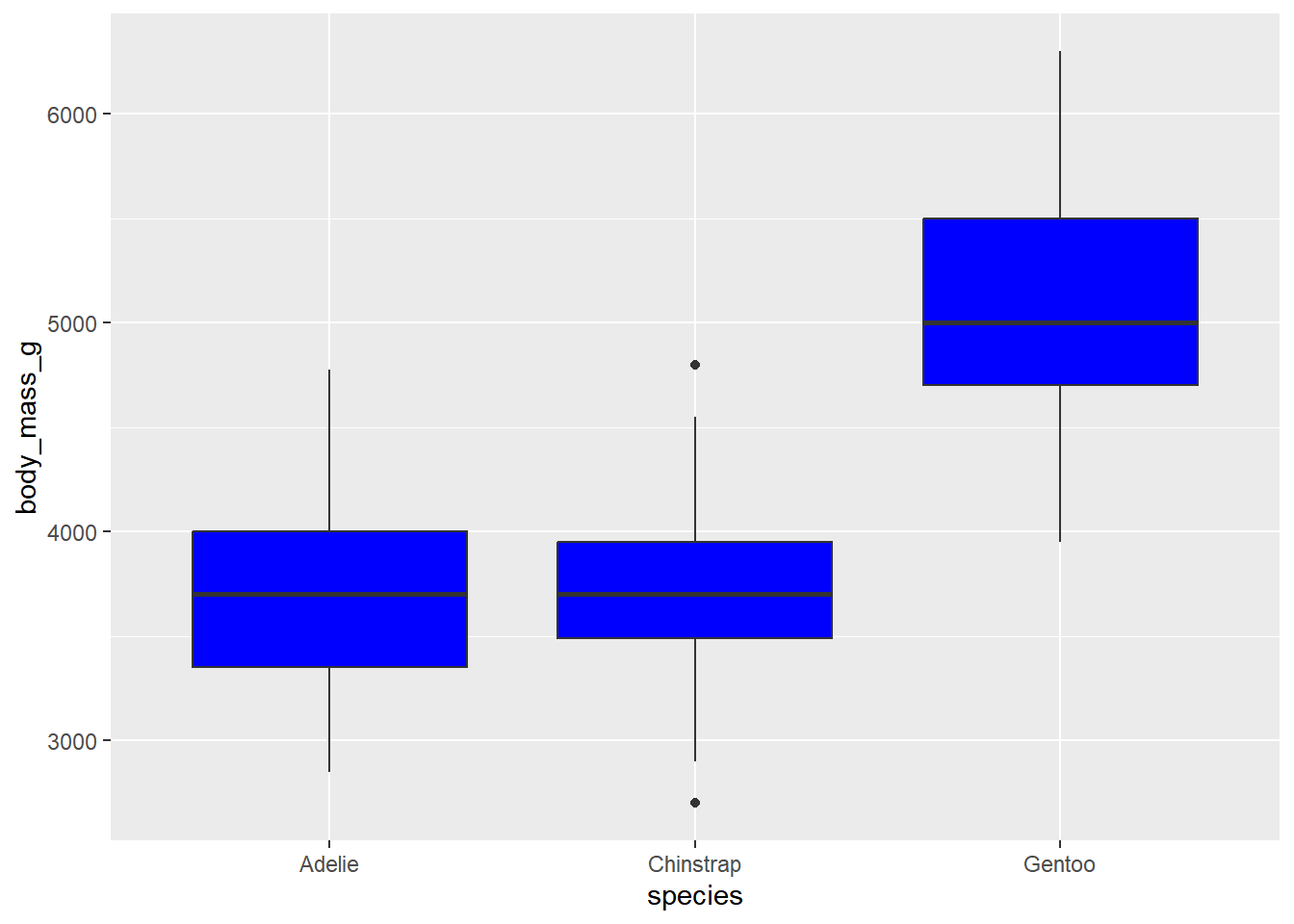
1.3.2 两个分类变量
- 当我们想要展示两个类别变量之间的关系时,通常使用堆积条形图(stacked bar chart)。
- 例如我们想要展示不同岛屿上不同种类企鹅的数量分布情况。
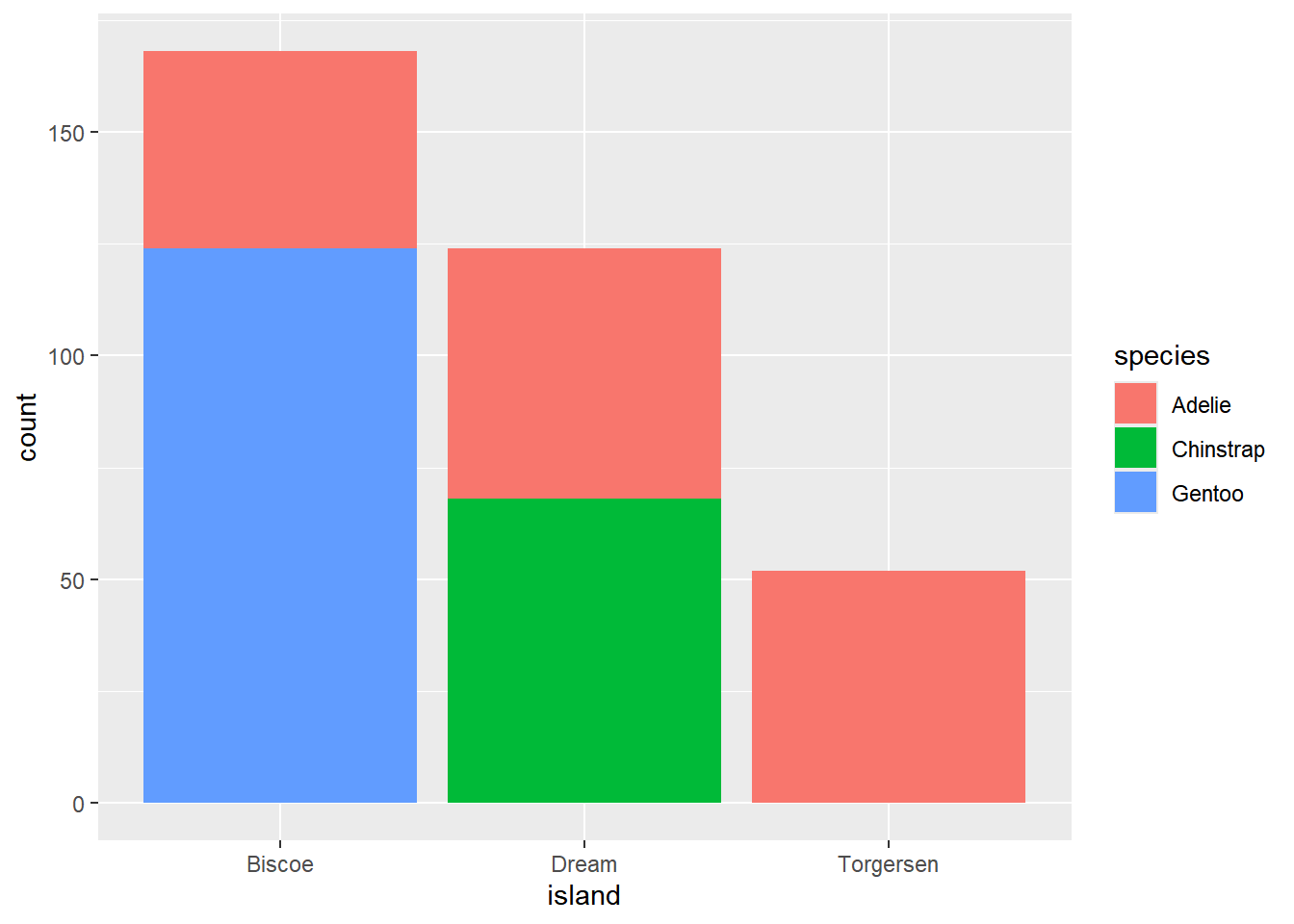
1.3.3 两个数值变量
散点图+光滑曲线(geom_smooth())是最常用的可视化两个数值变量关系的选择。
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point() +
geom_smooth(method = "lm")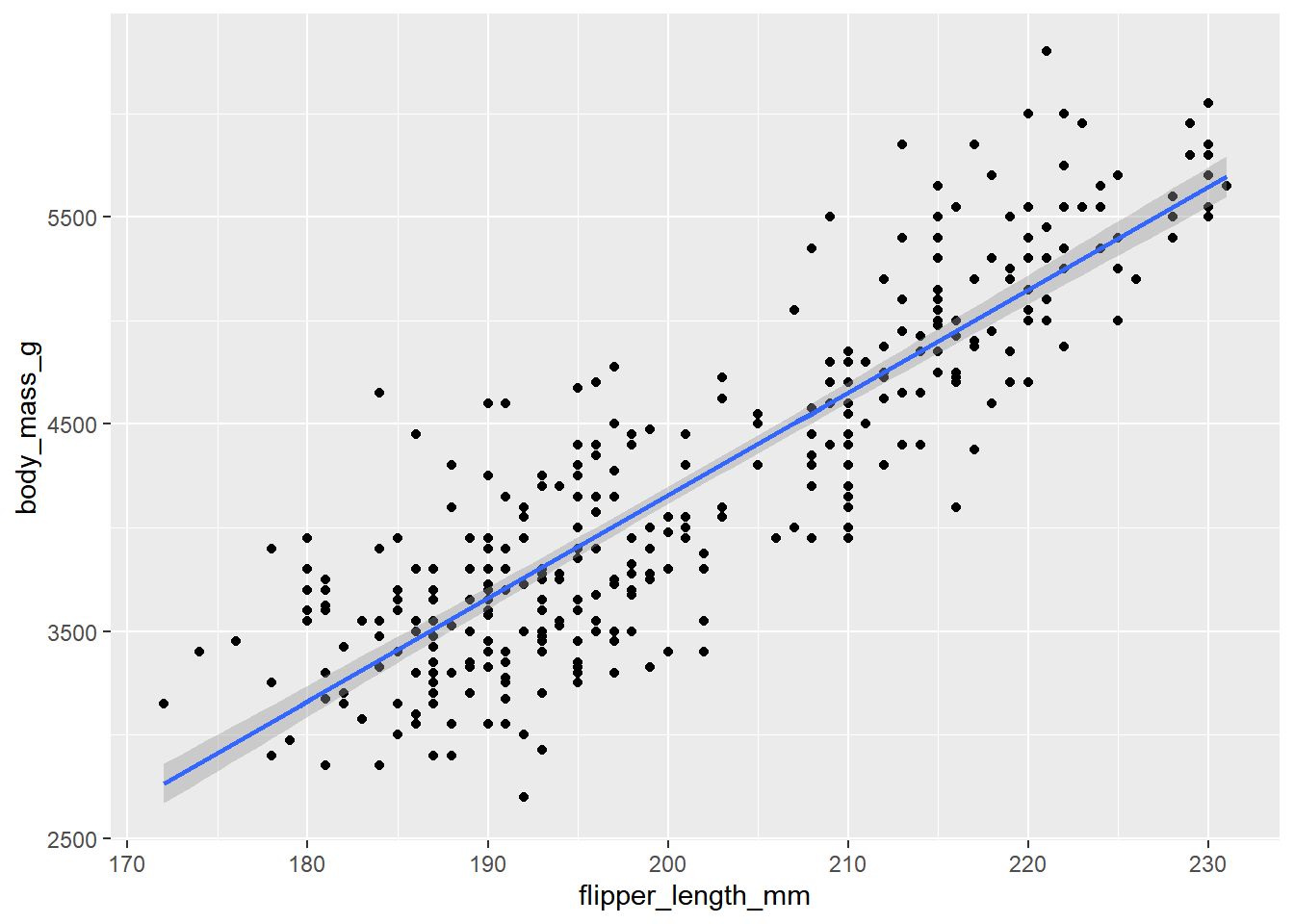
1.3.4 三个或更多变量
- 当我们想要展示三个或更多变量之间的关系时,可以通过映射额外的变量到不同的美学属性来实现,例如颜色(
color)、形状(shape)和大小(size)。 - 但过多变量映射可能会使图形变得复杂且难以解读,在我们特别需要展示多个变量间的关系时,分面(
facet)是一个更好的选择(见 小节 5.4)。
对于分类变量来说尤其有用。
ggplot(
penguins,
aes(x = flipper_length_mm, y = body_mass_g, color = species, shape = island)
) +
geom_point() +
facet_wrap(~island)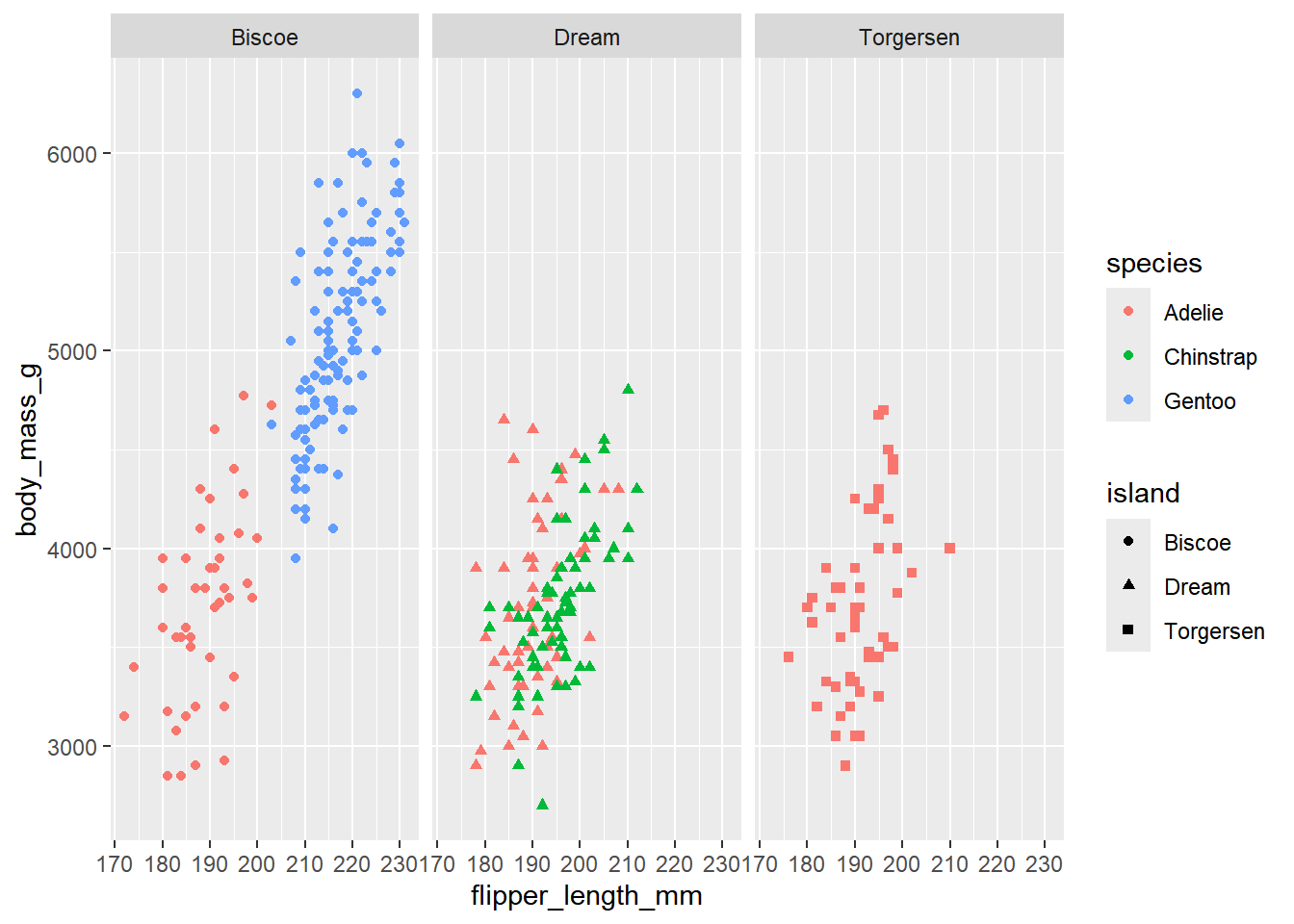
1.4 保存图标
- 通常我们需要对绘制的图形进行保存,以便后续使用或分享。
- 使用
ggsave()函数可以方便地将绘制的图形保存为文件。 - 该函数可以自动识别文件格式(如PNG、PDF、JPEG等),并允许用户指定图形的尺寸和分辨率。