23 统计学基础-描述性统计
描述性统计,主要是通过计算汇总统计量、绘制统计图来描述数据。本章使用rstatix包、tidymodels::infer包实现描述性统计及其整洁化,同时关注easystats生态系列。
我的blog文章”统计学检知识点及梳理备忘录” 中的第一节有关于描述性统计知识点的梳理。
23.1 常用的样本统计量
23.1.1 数据位置的统计量
- 中位数:位于数据最中间的数据,比中位数大和小的数据各占观测值的一半。中位数具有稳健性的优点,不受极个别极端数据的影响。
正态分布的数据用均值描述,偏态分布的数据最好用中位数描述。例如,人均工资给人一种被平均的感觉,中位数工资才是更合适的中间收入。
- 分位数(quantile):
- 中位数是 0.5 分位数,位于 0.5 位置的数。
- 0.25 分位数,称为下四分位数 (Q1), 是位于 0.25 那个位置的数,即比它小的数占比是 0.25, 比它大的数占比是 0.75。
- 0.75 分位数,称为上四分位数 (Q3)。
- 更一般地,一个有\(n\)个样本的数据集,它的\(p\)分位数,是位于\(p\)位置的数,即比它小的数占比是 \(p\), 比它大的数占比是 \(1-p\)。 或者说 \[np\] 的数比它小, \(n(1-p)\)的数比它大。
- 众数(mode):是观测值中出现次数最多的数,对应了分布的最高峰。众数常用于分类数据,即出现频数最高的值。
计算数据位置的统计量的函数:
23.1.2 数据分散程度的统计量
极差(range):数据中最大值和最小值的差。
四分位距(interquatile range):上下四分位数之差。
样本方差:式中\(n-1\)即为自由度,是计算样本统计量时能够自由取值的数值的个数。
\[ s^2 = \frac{1}{n-1}\sum^n_{i-1}|x_i-\bar{x}|^2 \]
不同统计方法的自由度均不相同,但基本原则是每估计1个参数,就需要消耗一个自由度。
以回归分析为例,若有m个自变量,则需要估计\(m+1\)个参数(包括截距项/常数项),所以模型的F检验用到的自由度是\(n-(m+1)\)。这意味着,只剩下\(n-(m+1)\)个可以自由取值的数值来估计模型误差。
样本标准差(sd):样本的方差的平方根即为标准差s,量纲与原数据一致。
变异系数(coefficient of variation):标准差占均值的百分比,可用于比较不同量纲数据的分散性。
\[ c_v=\frac{s}{\bar{x}}(\%) \]
R中的实现:
23.1.3 数据分布形状的统计量
- 偏度(skewness),刻画数据是否对称的指标,其中,均值对称的数据偏度为0(不偏);右拖尾(即曲线波峰偏左)的数据偏度为正(右偏);左拖尾(即曲线波峰偏右)的数据偏度为负(左偏)。
\[ SK=\frac{n}{(n-1)(n-2)}\sum^n_{i=1}(\frac{x_i-\bar{x}}{s})^3 \]
- 丰度(kurtosis):刻画数据是否尖峰的指标。
\[ K=\frac{n(n+1)}{(n-1)(n-2)(n-3)}\sum^n_{n-1}(\frac{x_i-\bar{x}}{s})^4-\frac{3(n-1^2)}{(n-2)(n-1)} \]
峰度是以标准正态分布为基准,标准正态分布的峰度为 0; 尖峰薄尾的分布峰度为正;平峰厚尾的分布峰度为负
datawizard包提供了skewness()和kurtosis()函数,分别计算偏度和丰度。
很多包都提供了同时对多个变量(分组)描述汇总所有常见统计量的函数,其中tidy风格的是rstatix::get_summary_stats()和dlookr::describe()。
# A tibble: 12 × 14
Species variable n min max median q1 q3 iqr mad mean sd
<fct> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 setosa Sepal.L… 50 4.3 5.8 5 4.8 5.2 0.4 0.297 5.01 0.352
2 setosa Sepal.W… 50 2.3 4.4 3.4 3.2 3.68 0.475 0.371 3.43 0.379
3 setosa Petal.L… 50 1 1.9 1.5 1.4 1.58 0.175 0.148 1.46 0.174
4 setosa Petal.W… 50 0.1 0.6 0.2 0.2 0.3 0.1 0 0.246 0.105
5 versic… Sepal.L… 50 4.9 7 5.9 5.6 6.3 0.7 0.519 5.94 0.516
6 versic… Sepal.W… 50 2 3.4 2.8 2.52 3 0.475 0.297 2.77 0.314
7 versic… Petal.L… 50 3 5.1 4.35 4 4.6 0.6 0.519 4.26 0.47
8 versic… Petal.W… 50 1 1.8 1.3 1.2 1.5 0.3 0.222 1.33 0.198
9 virgin… Sepal.L… 50 4.9 7.9 6.5 6.22 6.9 0.675 0.593 6.59 0.636
10 virgin… Sepal.W… 50 2.2 3.8 3 2.8 3.18 0.375 0.297 2.97 0.322
11 virgin… Petal.L… 50 4.5 6.9 5.55 5.1 5.88 0.775 0.667 5.55 0.552
12 virgin… Petal.W… 50 1.4 2.5 2 1.8 2.3 0.5 0.297 2.03 0.275
# ℹ 2 more variables: se <dbl>, ci <dbl># A tibble: 12 × 27
described_variables Species n na mean sd se_mean IQR skewness
<chr> <fct> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Petal.Length setosa 50 0 1.46 0.174 0.0246 0.175 0.106
2 Petal.Length versicolor 50 0 4.26 0.470 0.0665 0.600 -0.607
3 Petal.Length virginica 50 0 5.55 0.552 0.0780 0.775 0.549
4 Petal.Width setosa 50 0 0.246 0.105 0.0149 0.1 1.25
5 Petal.Width versicolor 50 0 1.33 0.198 0.0280 0.3 -0.0312
6 Petal.Width virginica 50 0 2.03 0.275 0.0388 0.5 -0.129
7 Sepal.Length setosa 50 0 5.01 0.352 0.0498 0.400 0.120
8 Sepal.Length versicolor 50 0 5.94 0.516 0.0730 0.7 0.105
9 Sepal.Length virginica 50 0 6.59 0.636 0.0899 0.675 0.118
10 Sepal.Width setosa 50 0 3.43 0.379 0.0536 0.475 0.0412
11 Sepal.Width versicolor 50 0 2.77 0.314 0.0444 0.475 -0.363
12 Sepal.Width virginica 50 0 2.97 0.322 0.0456 0.375 0.366
# ℹ 18 more variables: kurtosis <dbl>, p00 <dbl>, p01 <dbl>, p05 <dbl>,
# p10 <dbl>, p20 <dbl>, p25 <dbl>, p30 <dbl>, p40 <dbl>, p50 <dbl>,
# p60 <dbl>, p70 <dbl>, p75 <dbl>, p80 <dbl>, p90 <dbl>, p95 <dbl>,
# p99 <dbl>, p100 <dbl>23.2 统计图
23.2.1 分类数据的统计图
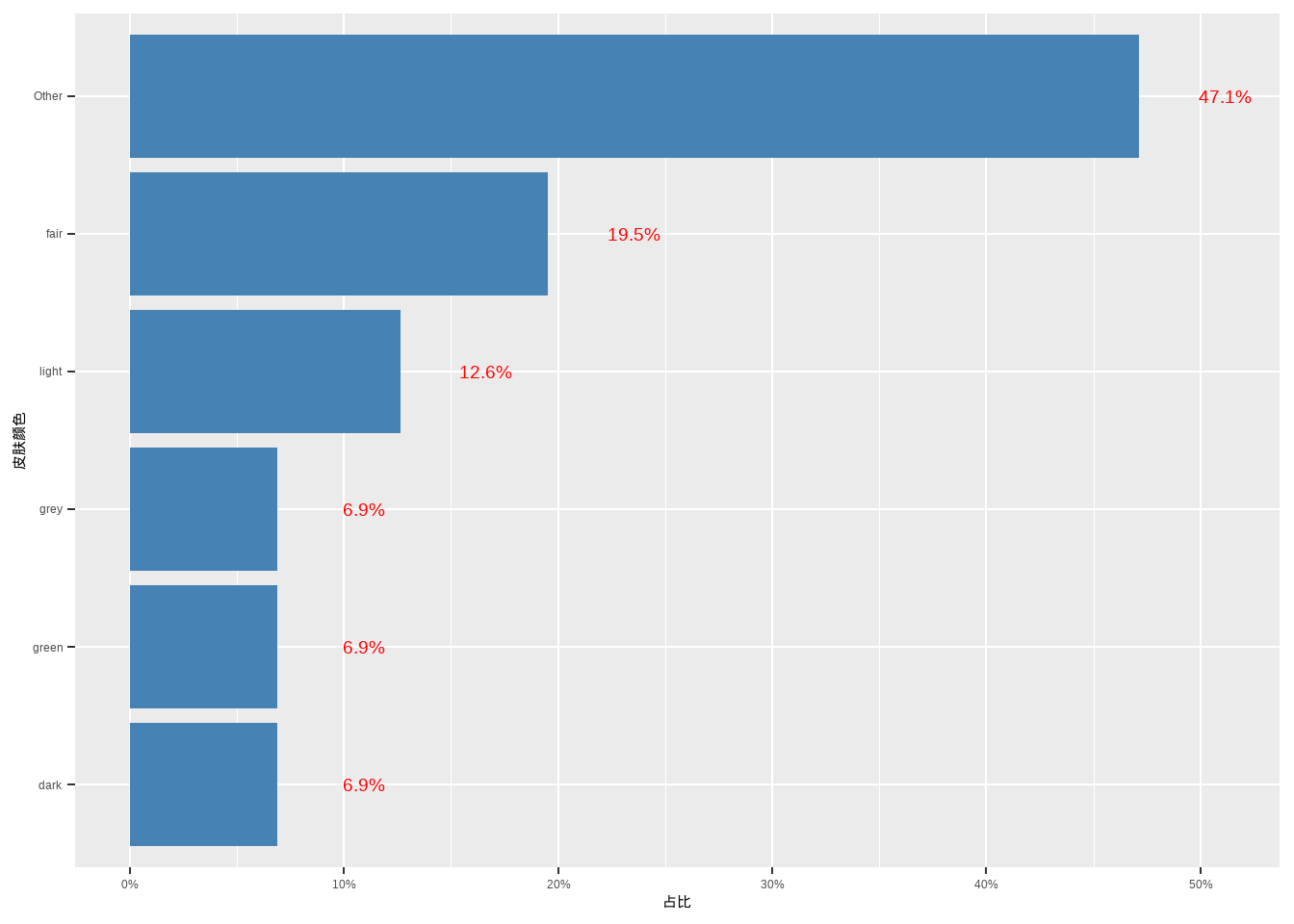
23.2.2 条形图
geom_bar():对原始数据绘制geom_col():对汇总频数/频率的数据绘制
library(tidyverse)
df <- starwars |>
# 合并频数<=5的类别
mutate(skin_color = fct_lump(skin_color, n = 5)) |>
count(skin_color, sort = TRUE) |>
mutate(p = n / sum(n))
ggplot(
df,
aes(
x = fct_reorder(skin_color, p),
y = p
)
) +
geom_col(fill = "steelblue") +
coord_flip() +
scale_y_continuous(labels = scales::percent) +
labs(x = "皮肤颜色", y = "占比") +
geom_text(
aes(
y = p + 0.04,
label = str_c(round(p * 100, 1), "%")
),
color = "red",
size = 5
)
23.2.2.1 克利夫兰点图
克利夫兰点图适合多类别之间比较的展示:x轴为分类变量,每一类对应一个类的均值或频数(y值),并画一个圆点;同时根据y值得大小对x轴类别进行排序。这类图形通常会进行一次坐标的翻转。
economics |>
group_by(year = lubridate::year(date)) |>
summarise(uempmed = mean(uempmed)) |>
filter(year >= 2000) |>
ggplot(aes(reorder(year, uempmed), uempmed)) +
geom_point(
size = 4,
shape = 21,
fill = "steelblue",
color = "black"
) +
geom_segment(aes(xend = ..x.., yend = 5)) + # 使用统计转换生成的变量,需在两边用..
coord_flip() +
labs(x = "year")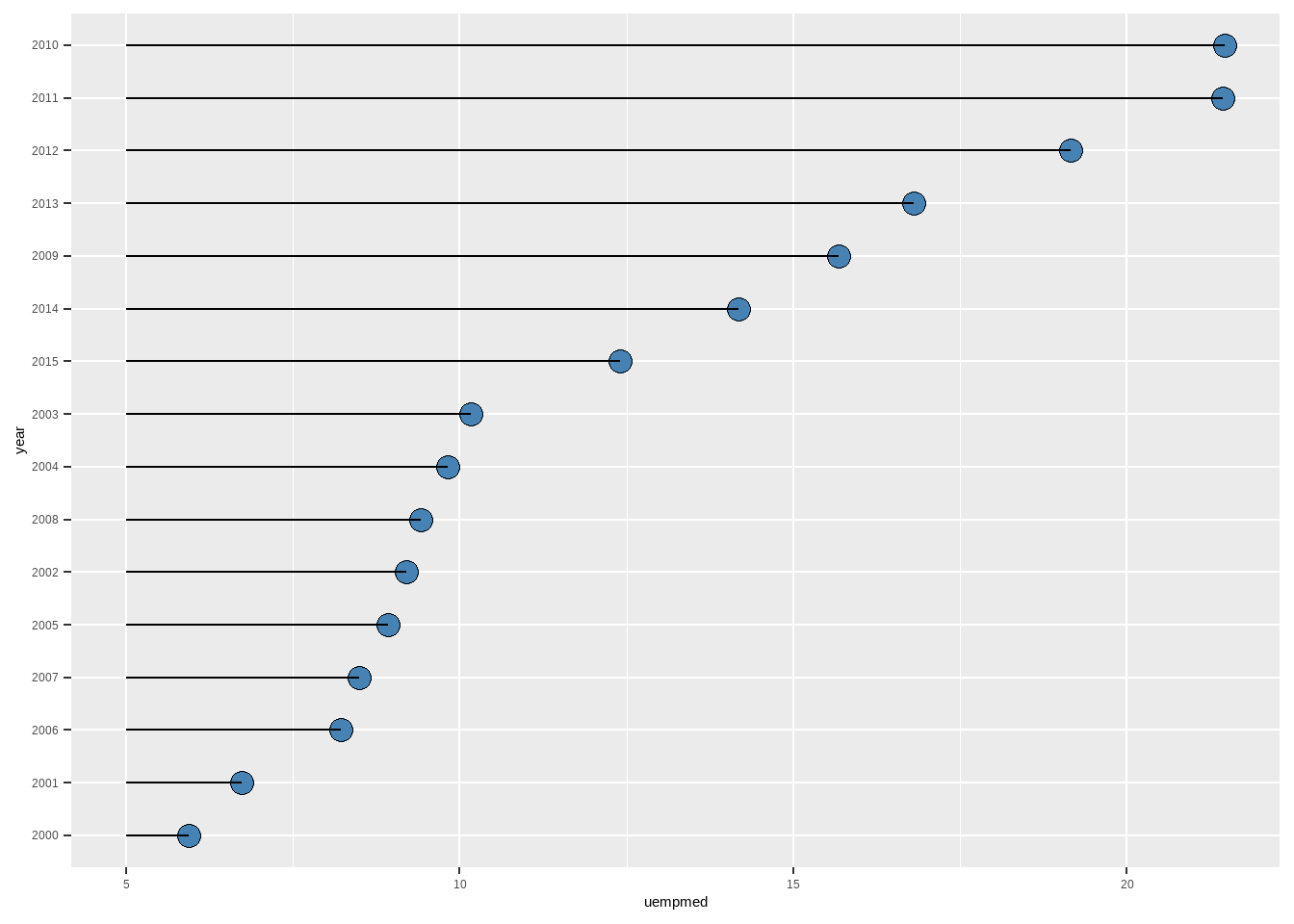
23.2.3 连续数据的统计图
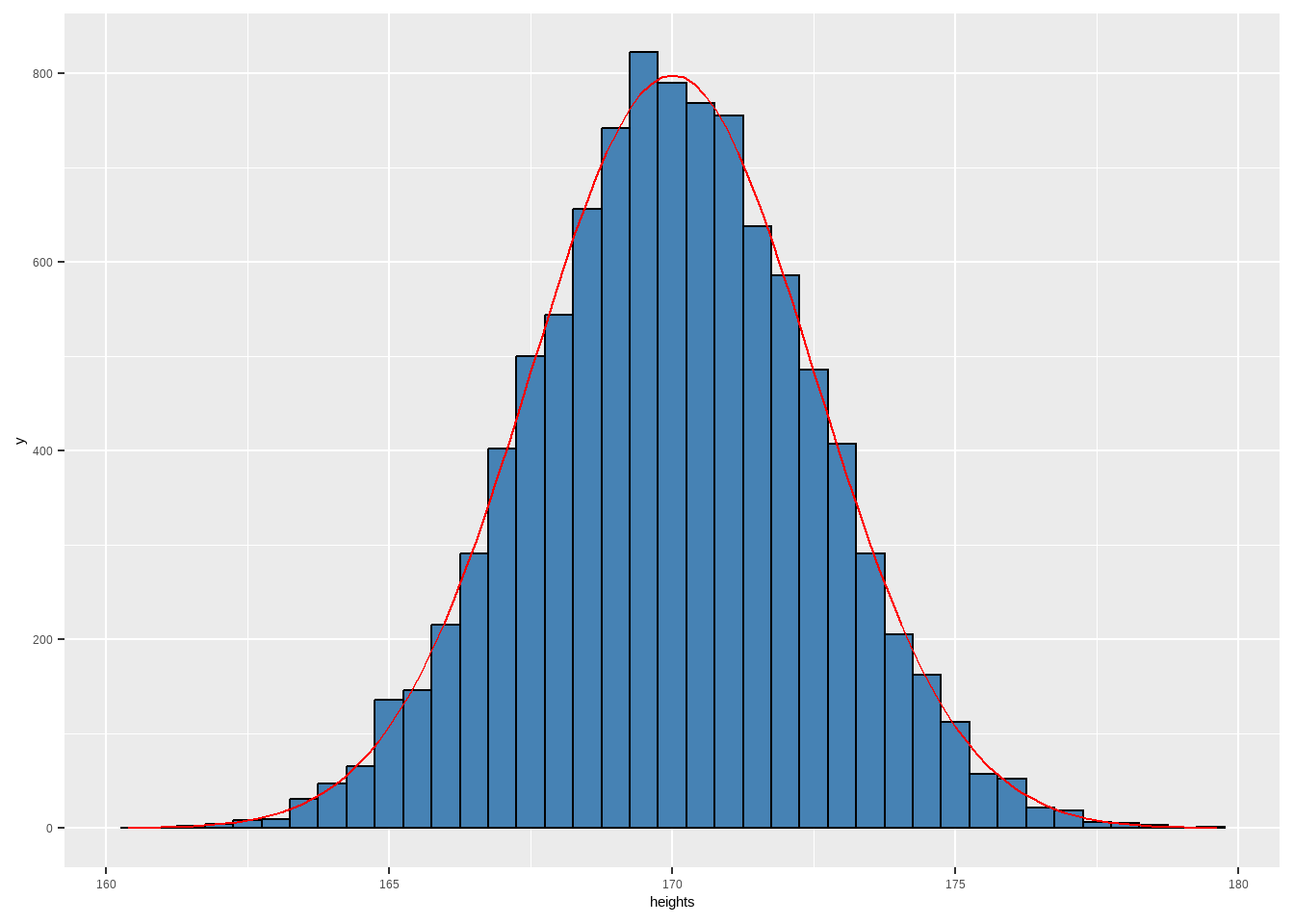
23.2.3.1 直方图
连续数据利用直方图估计总体的概率密度。
- 直方图是用面积而不是高度来表示数据。将变量的取值范围分成若干区间,区间总面积为100%,每个矩形的面积为落在该区间内数据的频率:
\[ 矩形的高=\frac{频率}{区间长度}=密度 \]
特别的,如果区间是等长的,则矩形的高是就是频率。
使用
geom_histogram()绘制直方图。频率直方图与概率密度曲线正好搭配,因为频率释放图的条形宽趋近于0,就是概率密度曲线。如果想绘制直方图 + 概率密度曲线,则需要对密度进行放大:\(条形宽度*样本数\)倍。
set.seed(123)
df <- tibble(heights = rnorm(10000, mean = 170, sd = 2.5))
ggplot(df, aes(x = heights)) +
geom_histogram(
fill = "steelblue",
color = "black",
binwidth = 0.5
) +
stat_function(
fun = ~ dnorm(.x, mean = 170, sd = 2.5) * 0.5 * 10000,
color = "red"
)
如果想在同一张图上叠加多个直方图,一对比分类变量不同水平的概率分布,更适合使用
geom_freqploy()绘制频率多边形图。geom_density()绘制核密度估计曲线。
23.2.3.2 箱线图
以数据的上下四分位数为界画一个矩形盒子(数据中处于中间的50%的数据落在盒内)。
在数据的中位数位置画一条线段作为中位线。
默认延长线为盒长的1.5倍,之外的点为异常值。
箱线图的的主要应用为:剔除数据异常值、判断数据的偏态和重尾、可视化组间差异。
ggplot(mpg, aes(drv, hwy)) +
geom_boxplot()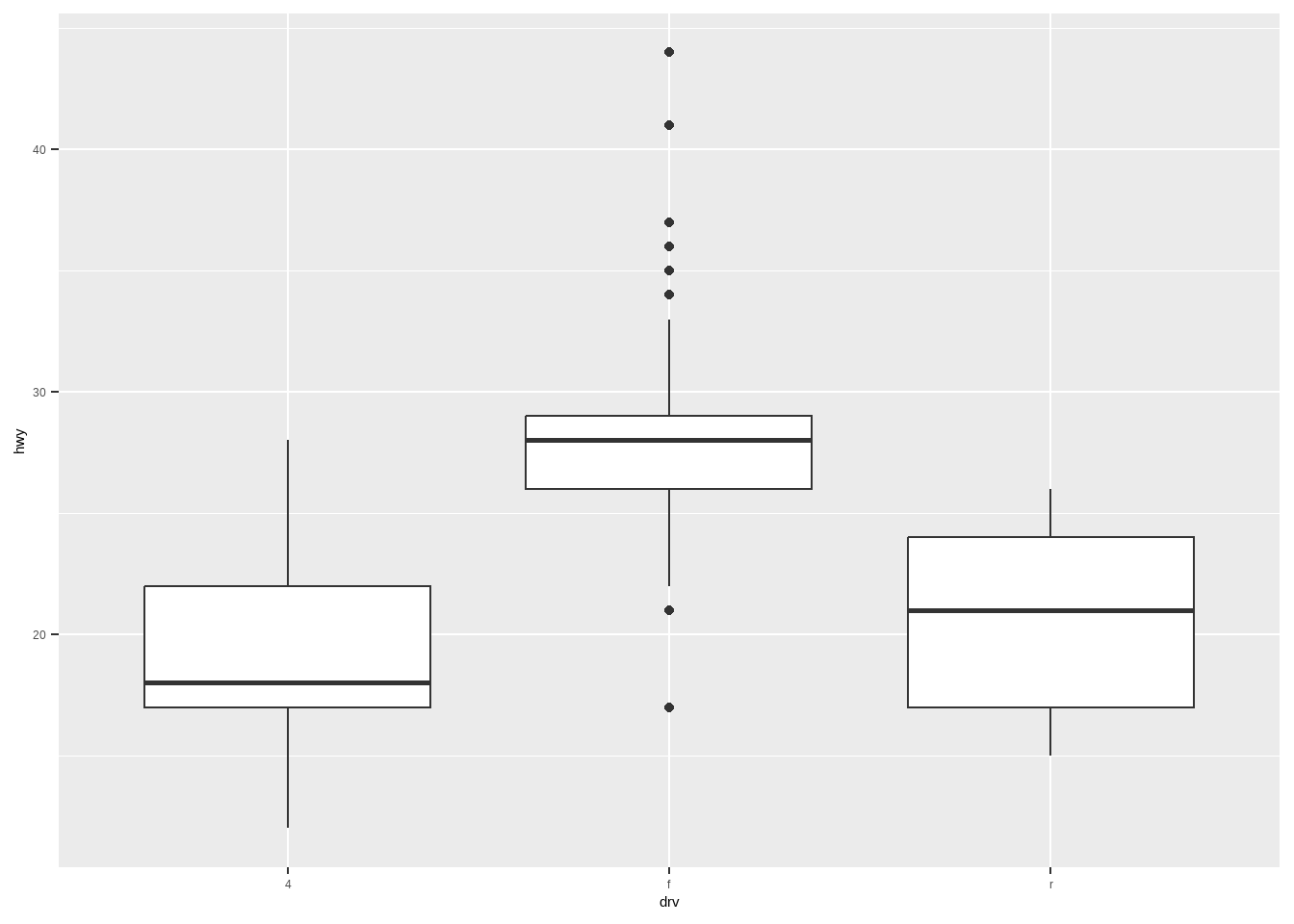
23.3 列联表
对分类变量做描述统计,通常是计算各水平值出现的频数和占比,得到列联表(交叉表)。传统方法可以使用table()函数实现,而janitor包中提供了更加tidy的方法。
列联表(contingency table)是观测数据按两个或更多属性(定性变量)分类时所列出的频数表。它是由两个以上的变量进行交叉分类的频数分布表。
列联表又称交互分类表,所谓交互分类,是指同时依据两个变量的值,将所研究的个案分类。交互分类的目的是将两变量分组,然后比较各组的分布状况,以寻找变量间的关系。
jantior::tabyl()函数可以生成一个、两个、三个变量的列联表,在结合adorn_*()系列函数,可以很方便的按照想要的格式添加行列合计、占比等。
library(janitor)
mpg |>
tabyl(drv) |>
adorn_totals("row") |> # 添加合计行
adorn_pct_formatting() # 设置百分比格式 drv n percent
4 103 44.0%
f 106 45.3%
r 25 10.7%
Total 234 100.0%二维列联表,添加列占比和频数。
mpg |>
tabyl(drv, cyl) |>
adorn_percentages("col") |> # 添加列占比
adorn_pct_formatting() |> # 设置百分比格式
adorn_ns() # 添加频数 drv 4 5 6 8
4 28.4% (23) 0.0% (0) 40.5% (32) 68.6% (48)
f 71.6% (58) 100.0% (4) 54.4% (43) 1.4% (1)
r 0.0% (0) 0.0% (0) 5.1% (4) 30.0% (21)此外,还有很多包能将描述性统计回归模型的结果变成规范的表格样式,代表性的是modelsummary包;表格设计、实验设计在科研、生产中的应用非常广泛,各种常用的实验设计,可以使用edibble包实现。