6 EDA
可视化是探索性数据分析(Exploratory Data Analysis, EDA)的重要工具。在本章中,我们将继续学习如何使用ggplot2包进行数据可视化,以便更好地理解数据的分布和关系。
EDA是一个迭代的过程,通常包括以下步骤:
- 提出关于数据的问题。
- 通过可视化、数据转换和数据建模来寻找问题的答案。
- 运用所学知识来精炼问题,并/或提出新的问题。
值得注意的是,EDA并非遵循严格规则的形式化流程,它更是一种思维方式。在 EDA 的初始阶段,我们应当自由探索所有浮现的想法:有些会结出硕果,有些则可能走入死胡同。随着探索的深入,我们会逐渐聚焦于少数极具价值的发现,最终将这些成果整理成文并传达给他人。
6.1 提出问题
提出优质问题的关键不在于一蹴而就,而在于在EDA的初期提出大量的问题,每个新提出的问题都会让我们接触到数据的新维度,从而增加发现的可能性。如果我们能根据已有发现不断追问新问题,就能快速深入数据最有趣的部分,并形成一系列发人深省的问题链。
虽然如此,但有两类问题对于从数据中发现规律始终大有裨益:
- 变异(Variation)探索:变量是否存在变异,存在哪种变异?
- 变量之间存在何种类型的协变(covariation occurs)关系?
6.2 变异
变异是指变量的值在每次测量中发生变化的趋势。现实生活中很容易观察到变异现象:即使对同一连续变量进行两次测量,也会得到不同的结果。即便是测量恒定物理量(如光速)时也是如此——每次测量都会包含微小的误差,且每次误差值各不相同。当测量不同对象(如不同人的眼睛颜色)或在不同时间点测量(如电子在不同时刻的能量水平)时,变量也会呈现变异。每个变量都有其独特的变异模式,这种模式既能揭示同一观测对象多次测量间的变化规律,也能反映不同观测对象间的差异特征。
理解这种变异模式对于深入分析数据至关重要。通过可视化手段,我们可以更直观地观察变量的分布情况,从而识别出变异趋势、异常值以及其他有趣的特征。
我们以diamonds数据集为例,探索其中carat变量的变异模式:
ggplot(diamonds, aes(x = carat)) +
geom_histogram(binwidth = 0.5)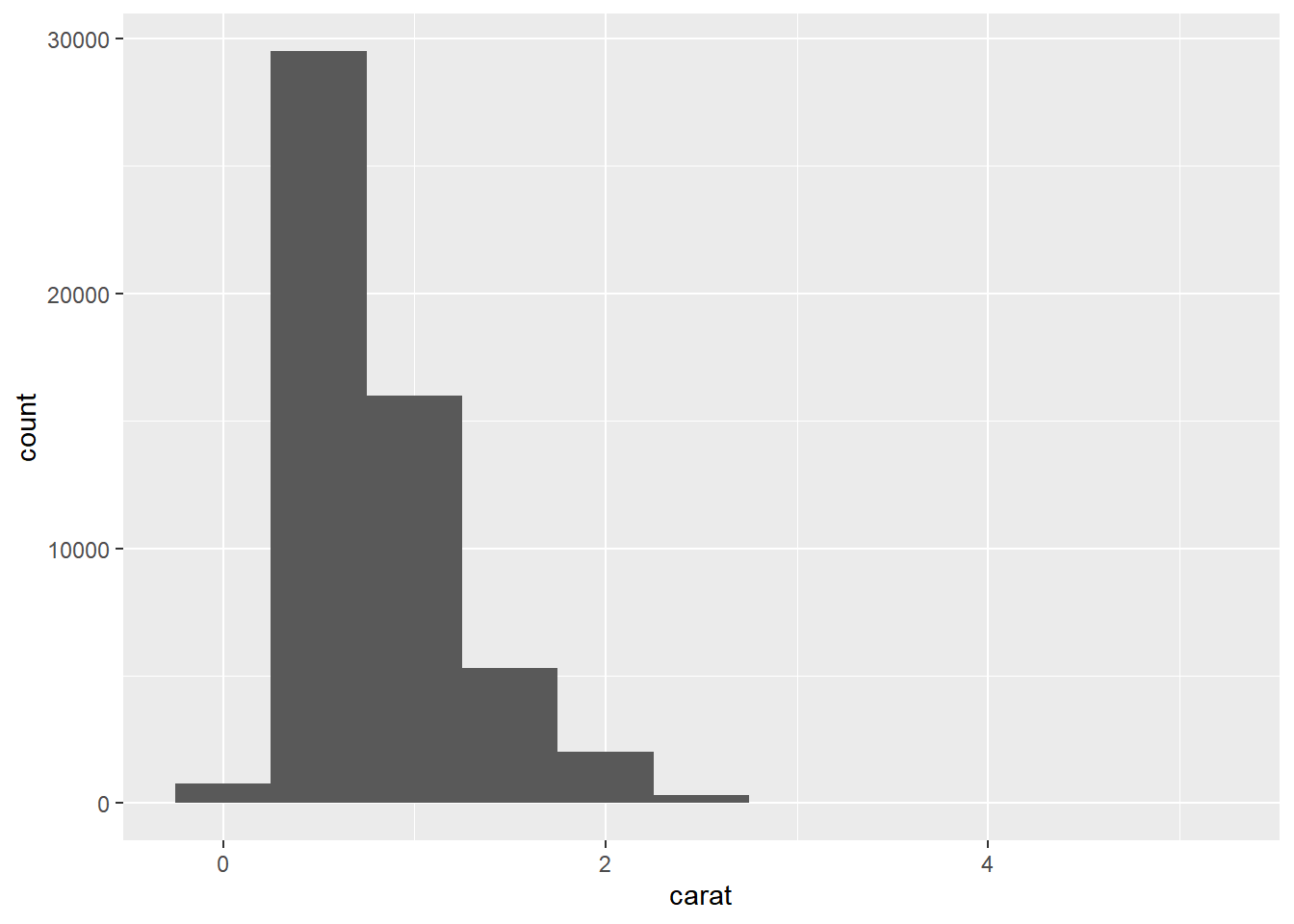
我们需要从图标中获得或寻找什么信息?又应该提出那些问题?接下来是一些图表中有用的信息和相关问题的清单。
6.2.1 典型值
在条形图和直方图中,较高的条形表示变量的常见值,较短的条形则表示较不常见的值,没有条形的位置揭示了数据中未出现的数值。
要将这些信息转化为有用的问题,我们需要关注一些极端的情况:
- 那些值最常见?为什么?
- 那些值最不常见?为什么?是否符合我们的预期?
- 数据中是否存在异常值或异常的模式?这些异常值可能是什么原因造成的?
smaller <- diamonds |>
filter(carat < 3)
ggplot(smaller, aes(x = carat)) +
geom_histogram(binwidth = 0.01)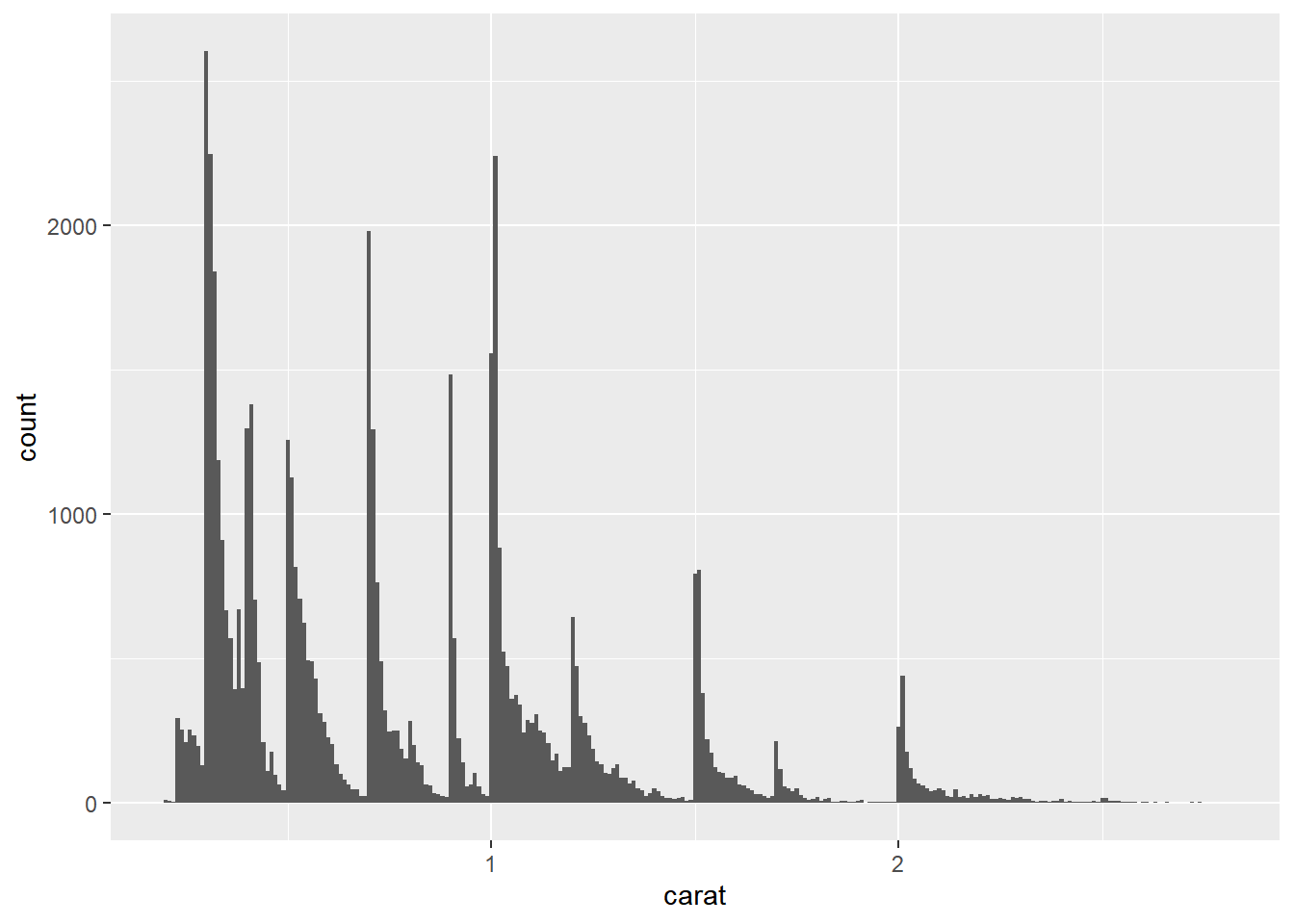
上图为carat小于3的钻石的分布情况,我们可以看到大部分钻石的克拉数集中在较小的范围内。基于此,我们可以提出以下问题:
- 为什么整数克拉数(如1克拉、2克拉)更常见?这是否与市场需求或定价策略有关?
- 为什么每座峰值右侧的钻石数量总是略多于左侧?
可视化还能揭示数据中的集群(clusters)现象,这表明数据中存在子群。要理解这些子群,可以思考:
每个子组内的观察结果彼此之间有何相似之处?
不同集群中的观测值之间有何差异?
如何解释或描述这些集群?
为什么集群的出现可能会误导人?
6.2.2 异常值
异常值是指那些与数据中大多数其他值显著不同的观测值。识别异常值对于理解数据的整体结构和潜在问题至关重要。
当遇到异常值时,通常我们有两种处理方式
- 直接剔除异常值所在的行。
- 将异常值替换为缺失值,最简单的方法是使用
mutate()函数创建一个修改后的变量副本。你可以利用ifelse()函数将异常值替换为NA。R中的大部分函数对NA都是敏感的(例如ggplot()在绘图时会剔除NA并给出提示),可以帮助我们很好的了解剔除异常值后对数据有什么影响。
nycflights13::flights |>
mutate(
cancelled = is.na(dep_time),
sched_hour = sched_dep_time %/% 100,
sched_min = sched_dep_time %% 100,
sched_dep_time = sched_hour + (sched_min / 60),
.before = dep_time
) |>
ggplot(aes(x = sched_dep_time, y = after_stat(density))) +
geom_freqpoly(
aes(color = cancelled),
binwidth = 0.25,
linewidth = 0.75
) +
facet_grid(cancelled ~.)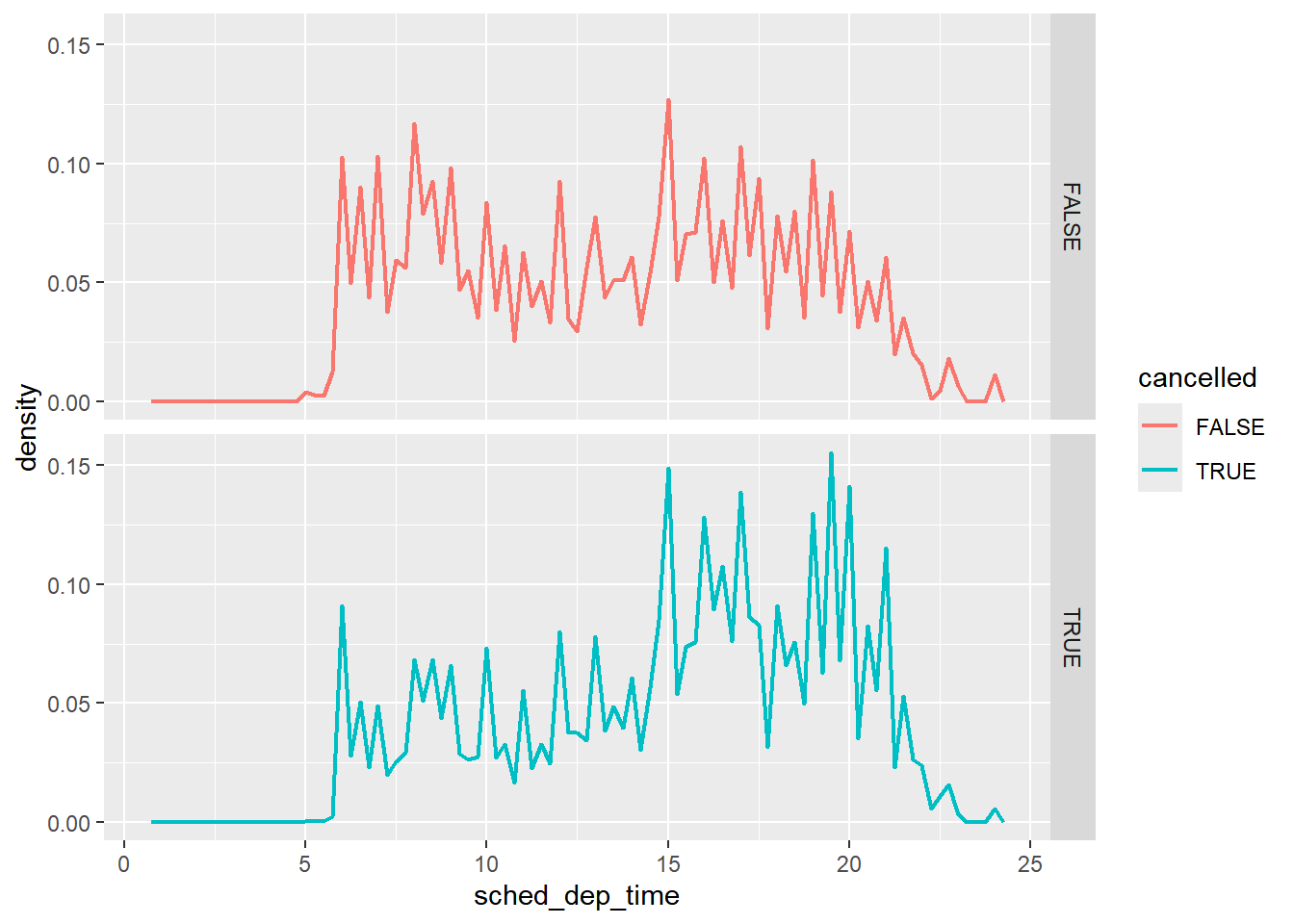
6.3 协变
变异是描述变量内部的行为,而协变是指两个或多个变量之间的关系或关联。理解变量之间的协变关系对于揭示数据中的潜在模式和趋势至关重要。在 小节 1.3 中我们已经学习了部分变量间关系的图形。
6.3.1 分类变量与数值变量的协变
分类变量与数值变量之间的协变关系可以通过箱线图(boxplot)可视化( 中有过介绍)。这些图表能够展示不同类别下数值变量的分布情况,从而揭示类别之间的差异。
值得注意的是,箱线图诞生于数据量较小的时代,图形中往往会显示出一连串的异常值。解决这个问题的一种方法是使用字母值图。安装 lvplot 包,尝试使用geom_lv() 展示价格与切工的分布情况。
ggplot(diamonds, aes(x = cut, y = price)) +
geom_boxplot()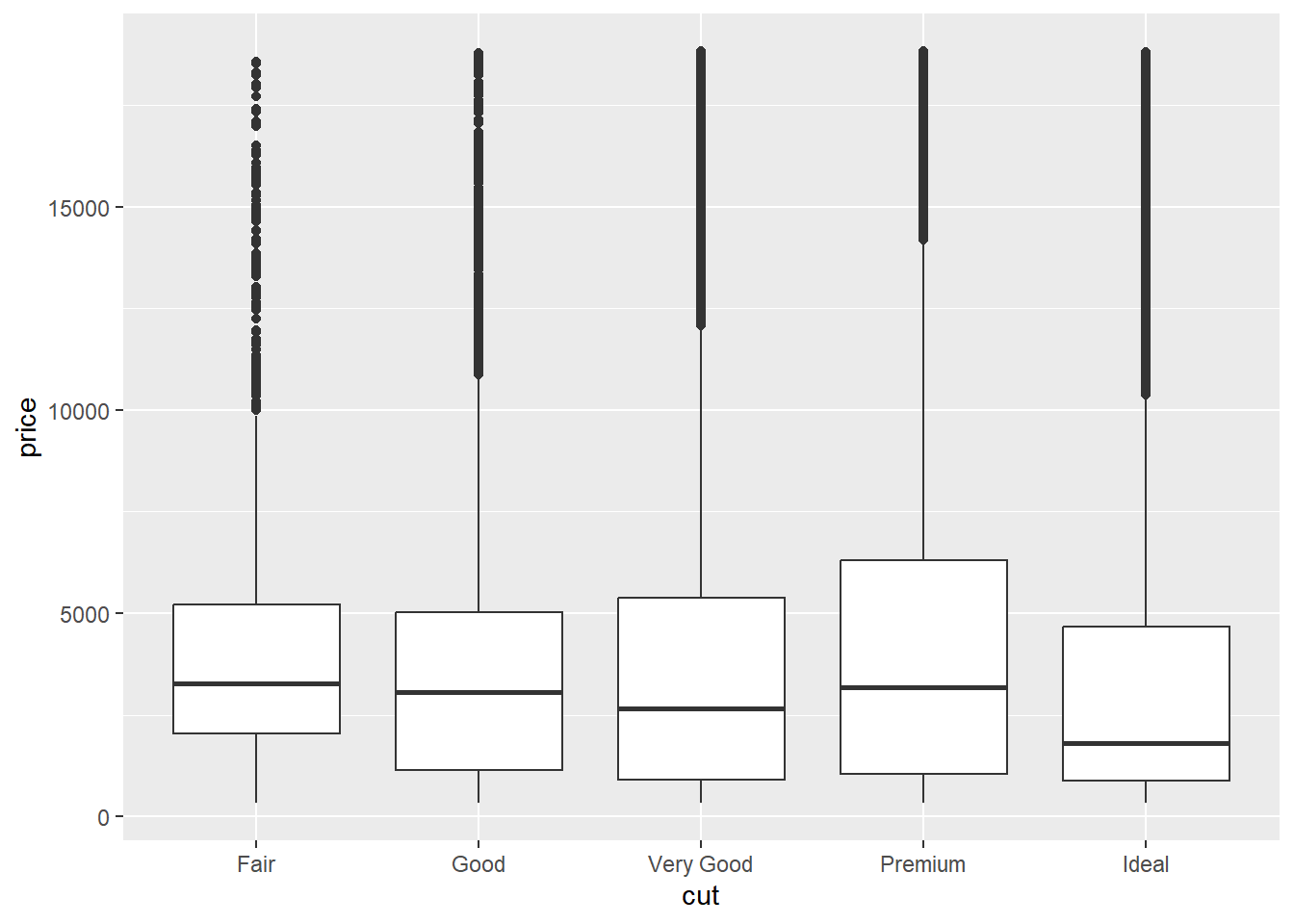
6.3.2 两个分类变量的协变
探索分类变量之间关系的另一种方法是使用dplyr计算计数,再使用geom_tile()绘制相关性填充图。
seriation 包来同时重新排列行和列,以便更清晰地揭示有趣的模式。对于更大的图表,你可以尝试使用 heatmaply 包,它能创建交互式图表。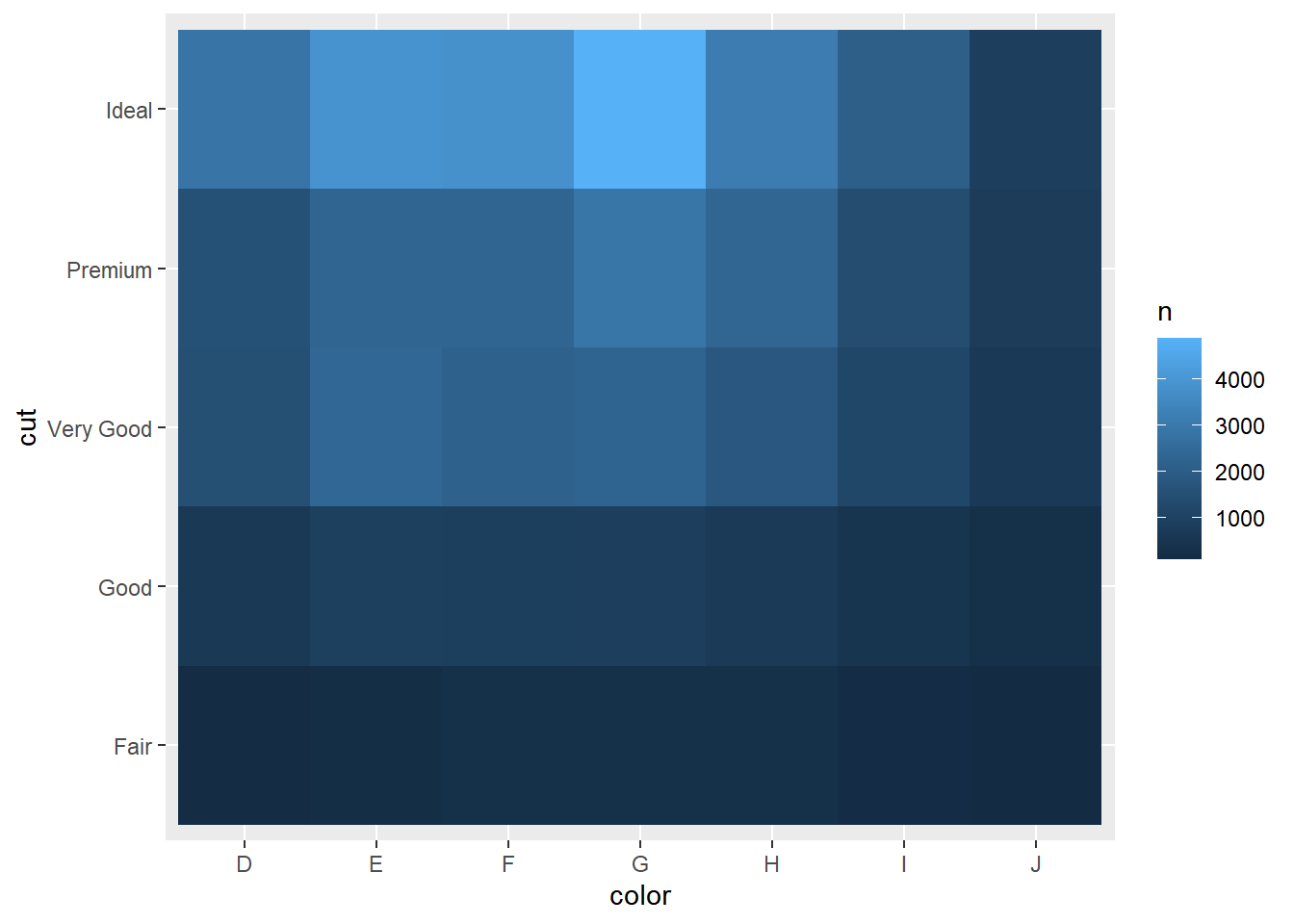
6.3.3 两个数值变量的协变
散点图是探索两个数值变量之间协变关系的常用工具。但随着数据量的增加,散点图可能会变得难以解读,因为点会重叠在一起。为了解决这个问题,可以使用透明度(alpha)来减少重叠的影响,或者使用二维分箱(geom_bin_2d())来展示数据的分布密度。
# 使用二维分箱展示carat与price的关系
ggplot(smaller, aes(x = carat, y = price)) +
geom_bin2d()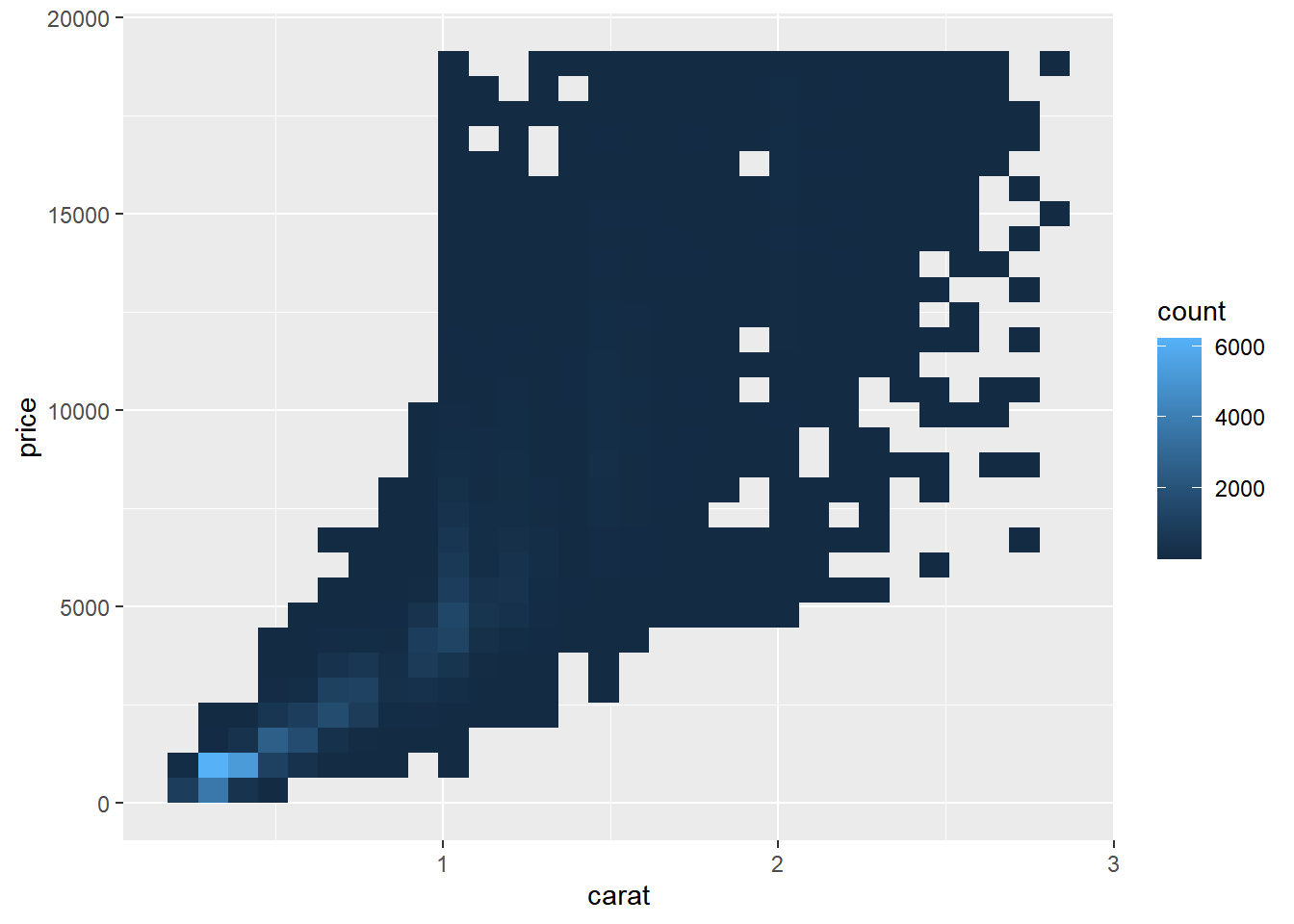
# 对cut进行分箱后绘制boxplot
ggplot(smaller, aes(x = carat, y = price)) +
geom_boxplot(aes(group = cut_width(carat, 0.1)), varwidth = T) # 每0.1克拉为一个分箱,varwidth = T表示箱体宽度与样本量成正比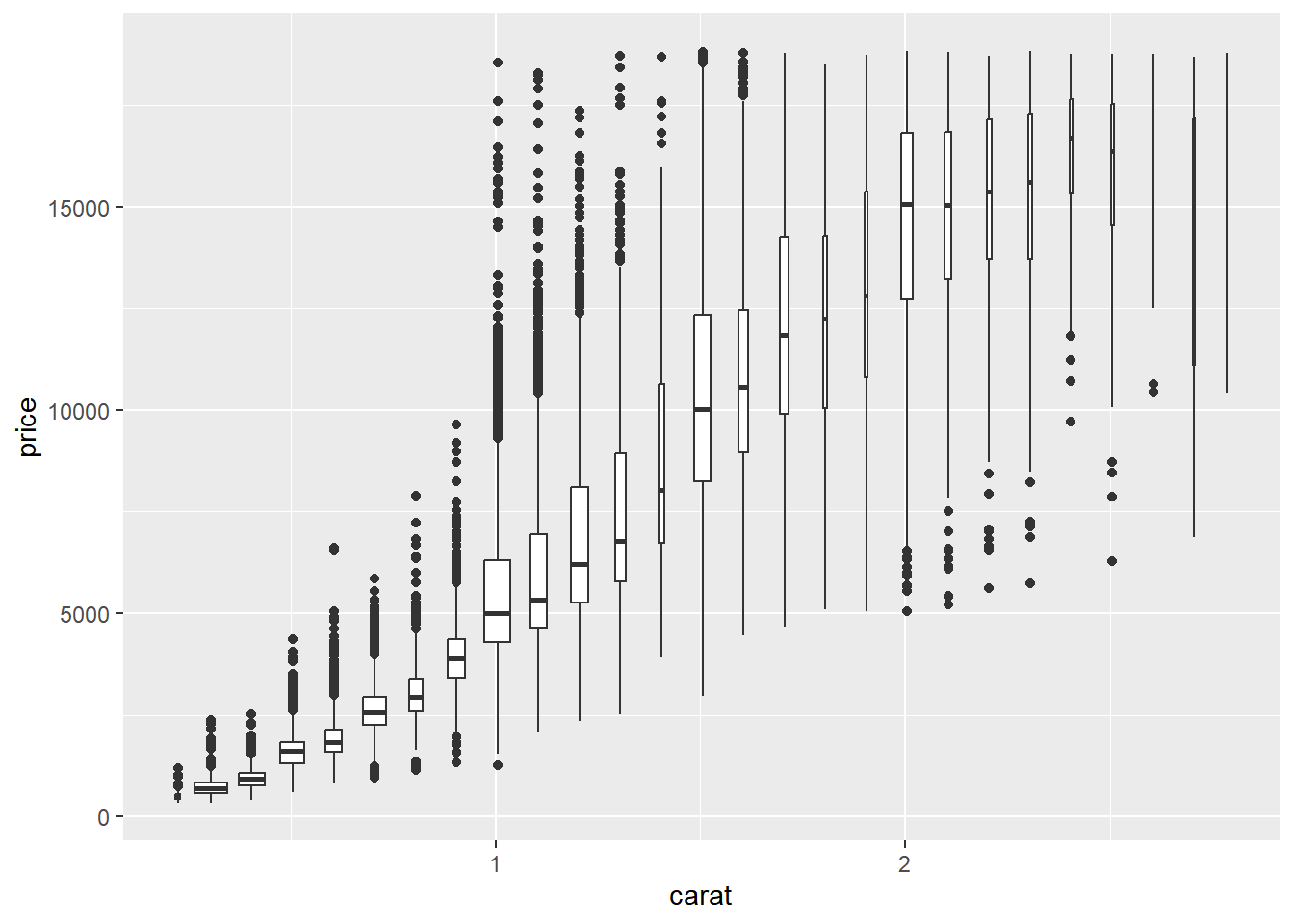
ggplot(smaller, aes(x = carat, y = price)) +
geom_boxplot(aes(fill= cut))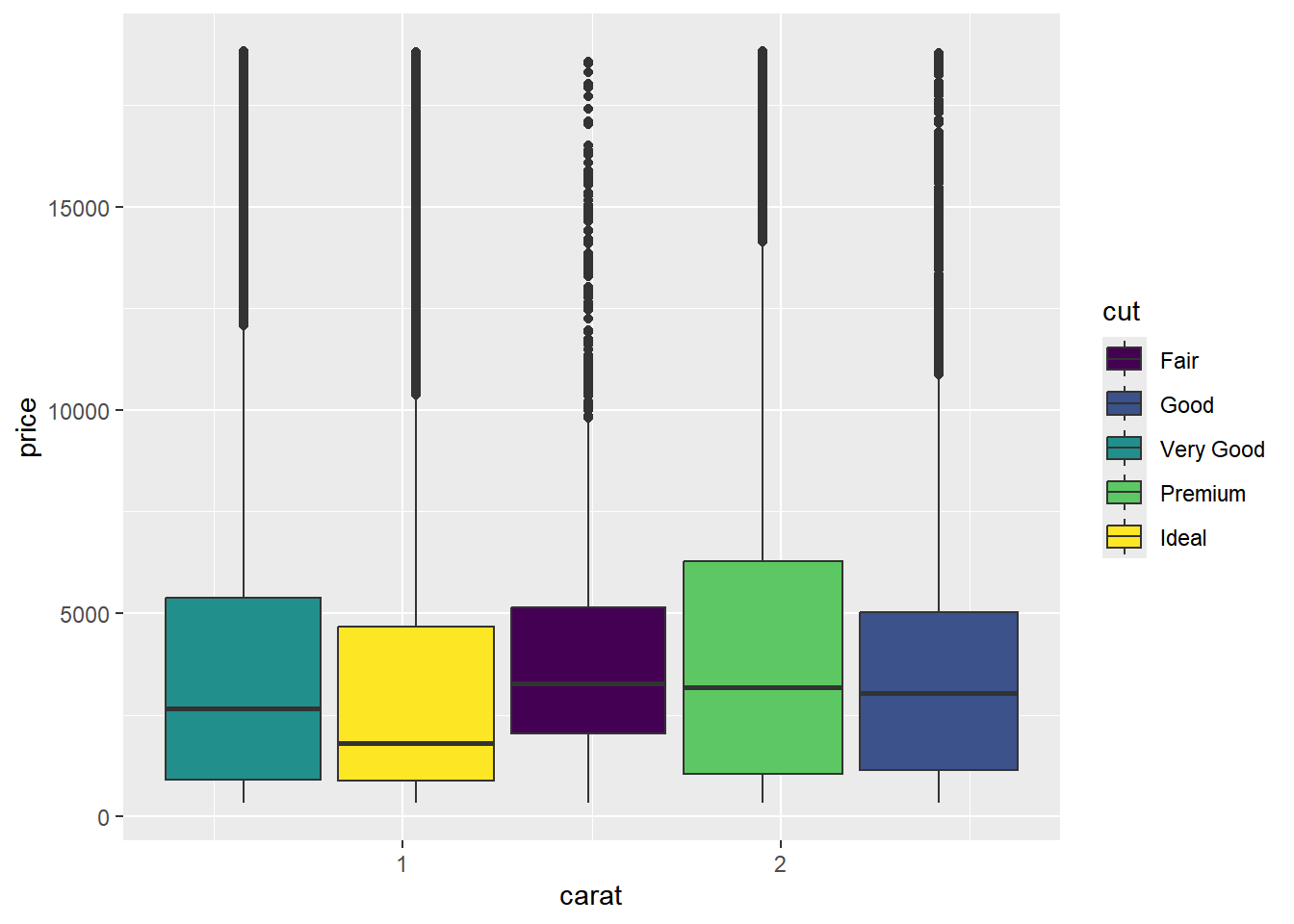
# 可视化cut、carat和price的组合分布
ggplot(smaller, )
6.4 模式与模型
在探索数据时,我们通常会发现一些有趣的模式。这些模式可能是变量之间的关系、数据的分布特征,或者是某些异常现象。识别这些模式后,我们可以尝试建立模型来解释这些现象。
这种模式可能是巧合(即随机概率)造成的吗?
如何描述这种模式所暗示的关系?
该模式所暗示的关系有多强?
其他哪些变量可能影响这种关系?
如果你查看数据的各个子组,这种关系是否会发生变化?
假设两个钻石的重量完全相同(比如都是 1 克拉),那么它们的重量预期价格 是一样的;此时两者的价格差异,完全来自重量之外的因素(切工、颜色、净度等),而这个差异就体现在残差上。
对模型:残差是 模型没解释清楚的部分,通过残差能诊断模型是否合理、拟合精度如何;
对变量:残差能剥离核心变量的干扰,看清其他变量对响应变量的真实影响(如剥离重量后,切工对钻石价格的影响)。
我们不在本部分中讨论建模,因为一旦你掌握了数据整理和编程工具,理解模型是什么以及它们如何运作就会变得最为容易。
在本书的第七、第八、第九部分,继续学习统计学习和建模的内容。