11 因子
R提供了因子这一数据结构(容器),专门用来存放名义型和有序型的分类变量。因子本质上是一个带有水平(level)属性的整数向量,其中 “水平” 是指事前确定可能取值的有限集合。例如,性别有两个水平:男、女。
forcats包是处理因子的强大工具。forcats中的所有函数可参见forcats中的所有函数。
11.1 因子基础
-
使用
forcats::fct()函数将向量转换为因子。 使用
levels()函数查看或修改因子的水平。readr读取数据时,可以直接使用col_factor()函数将变量读入为因子。
[1] Dec Apr Jan Mar
Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Decsort(y1) # 按照因子水平排序[1] Jan Mar Apr Dec
Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec# 因子中有未包含在水平中的值
y2 <- factor(x2, levels = month_levels) # factor()不会报错,而使用NA填充未包含的值
y2[1] Dec Apr <NA> Mar
Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec# orcats::fct(x2, levels = month_levels) 会报错,并提示未包含的值11.2 修改因子顺序
在进行更复杂的数据变化时,建议将
fct_**()等操作移出aes(),而是在数据变形时直接进行变化.# fct_reorder()-按一个变量的顺序重新排列因子
relig_summary <- gss_cat |>
group_by(relig) |>
summarise(
tvhours = mean(tvhours, na.rm = TRUE),
n = n()
)
ggplot(relig_summary, aes(x = tvhours, y = fct_reorder(relig, tvhours))) +
geom_point()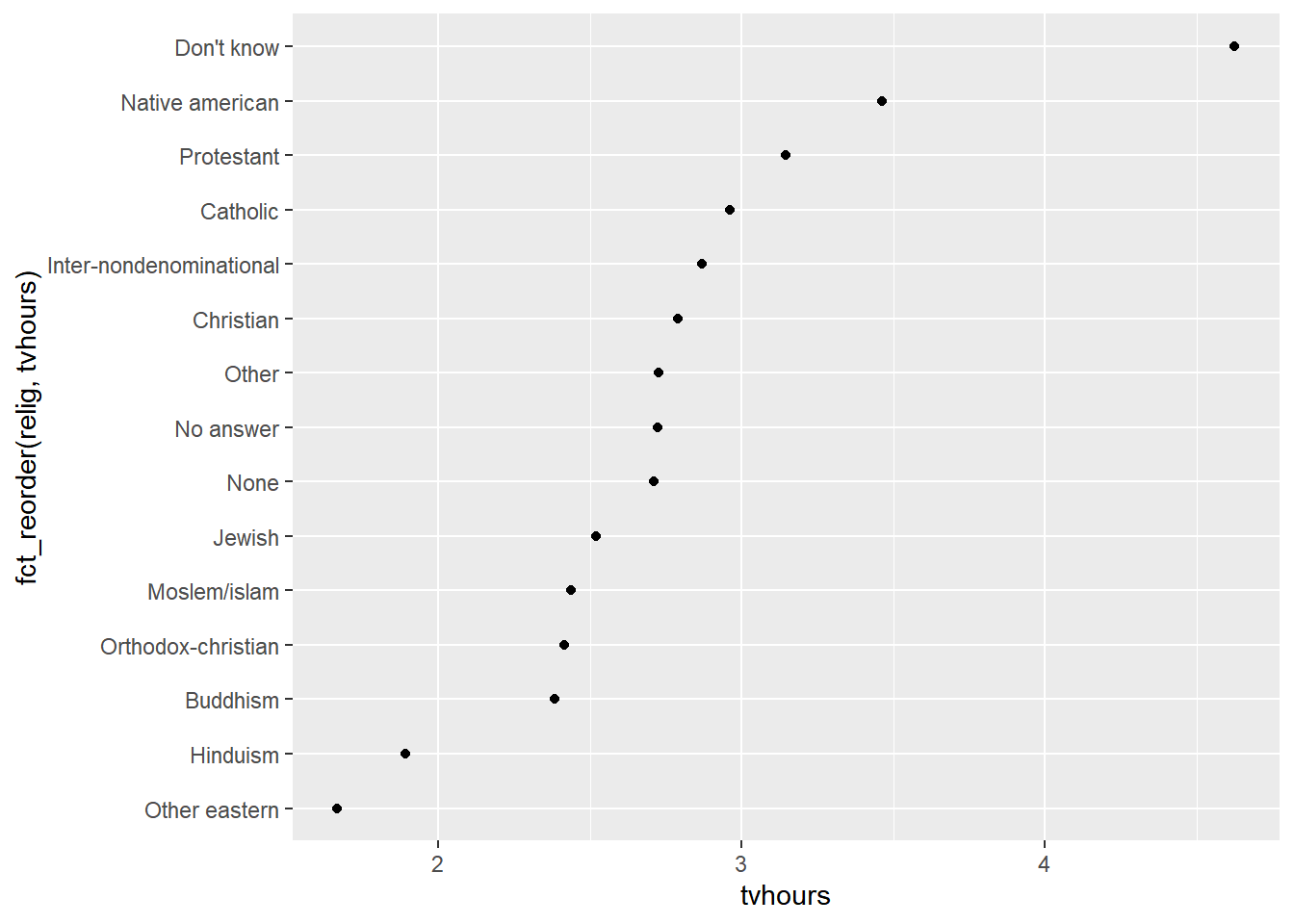
# fct_relevel()-手动调整因子水平的顺序-将任意数量的因子水平移动致指定位置.
rincome_summary <- gss_cat |>
group_by(rincome) |>
summarize(
age = mean(age, na.rm = TRUE),
n = n()
)
rincome_summary |>
mutate(rincome = fct_relevel(rincome, "Not applicable")) |>
ggplot(aes(x = age, y = rincome)) +
geom_point()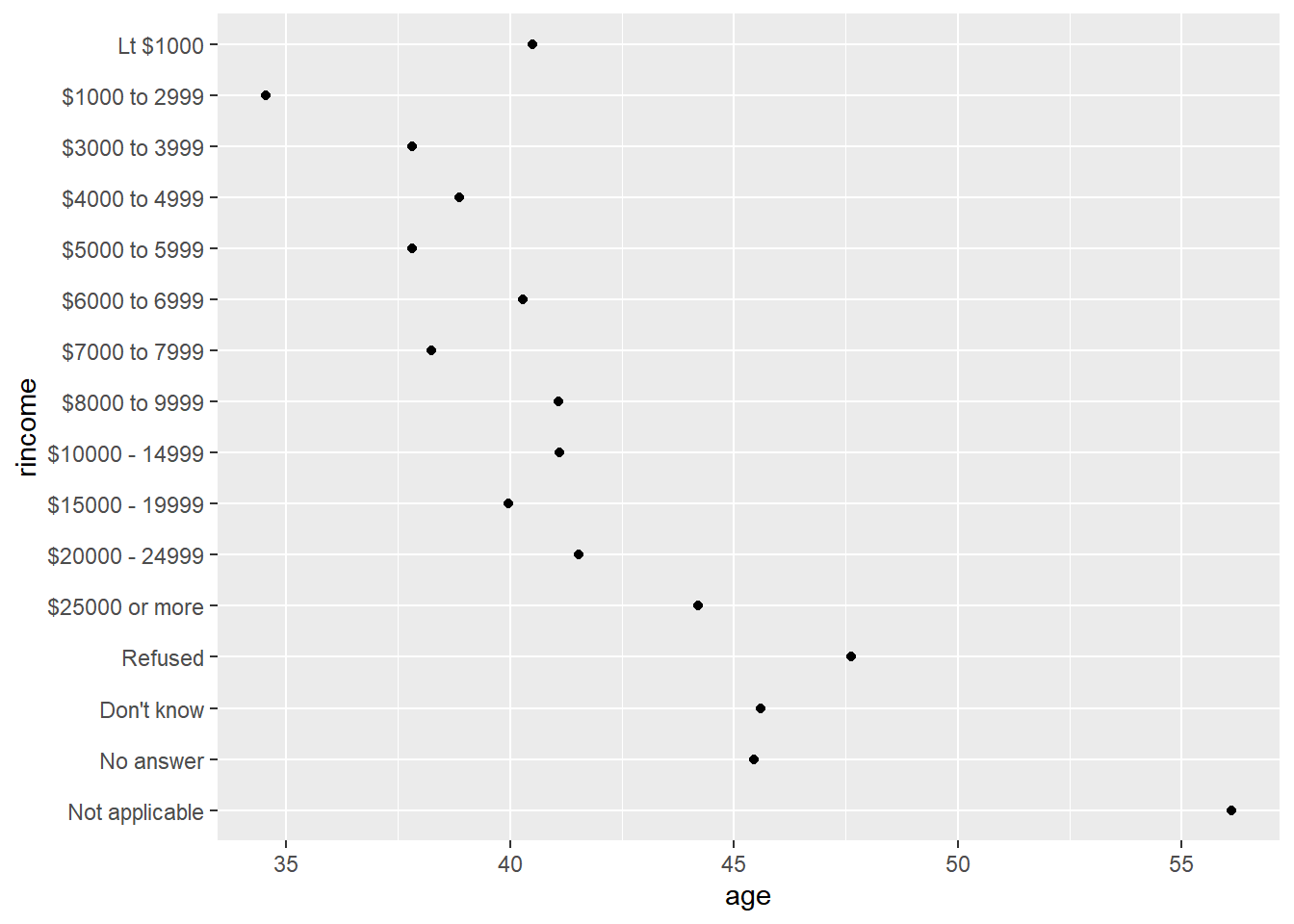
# fct_reorder2(.f, .x, .y)-根据与变量.x的最大值关联的变量.y值对因子.f进行重新排序.
by_age <- gss_cat |>
filter(!is.na(age)) |>
count(age, marital) |>
group_by(age) |>
mutate(prop = n / sum(n))
by_age |>
mutate(marital = fct_reorder2(marital, age, prop)) |>
ggplot(aes(x = age, y = prop, color = marital)) +
geom_line(linewidth = 1) +
scale_color_brewer(palette = "Set1") +
labs(color = "marital")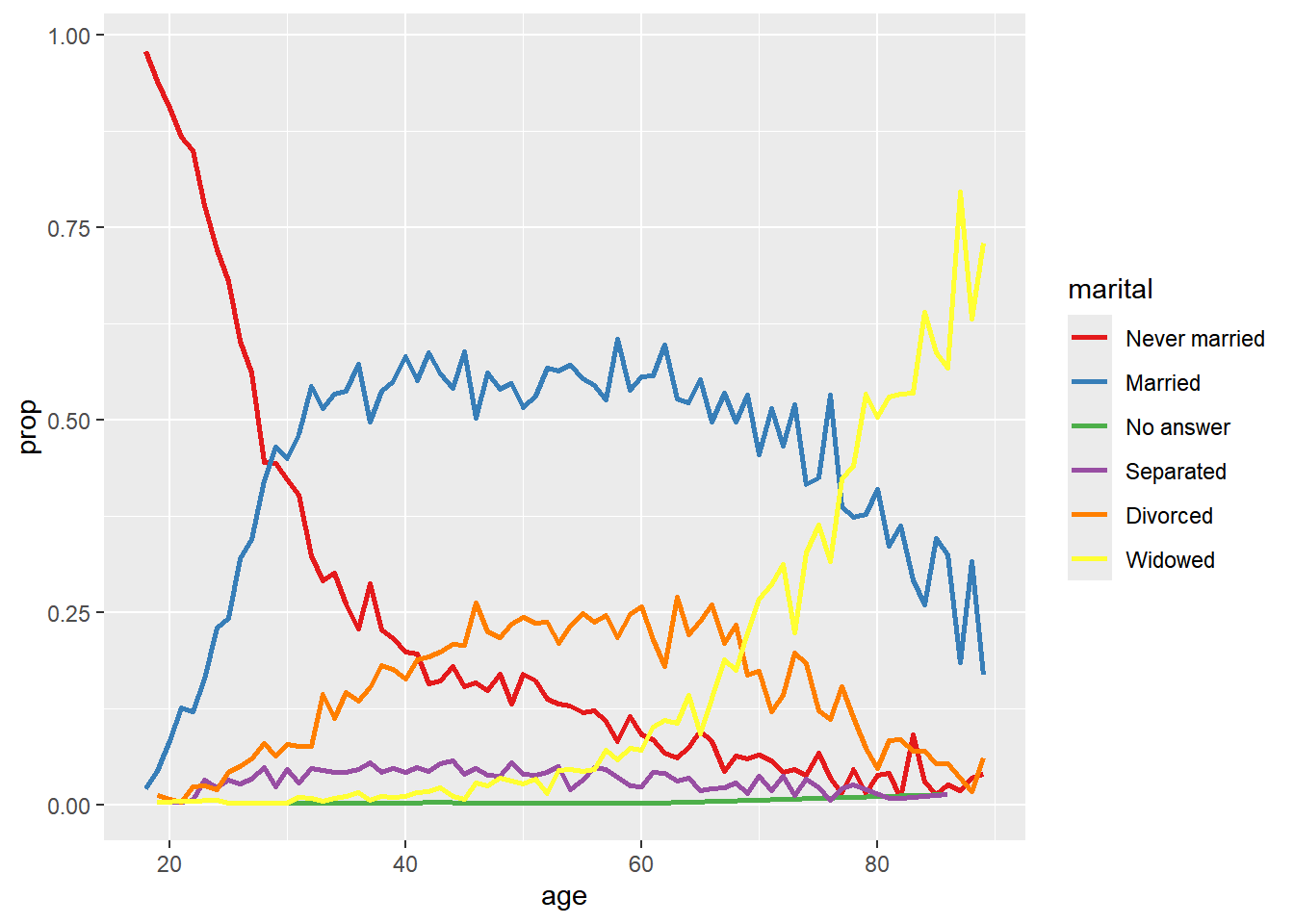
# fct_infreq()-按照频数递减的顺序重新排列因子;fct_rev()函数倒序排列因子.
gss_cat |>
mutate(marital = fct_infreq(marital)) |>
ggplot(aes(x = marital)) +
geom_bar()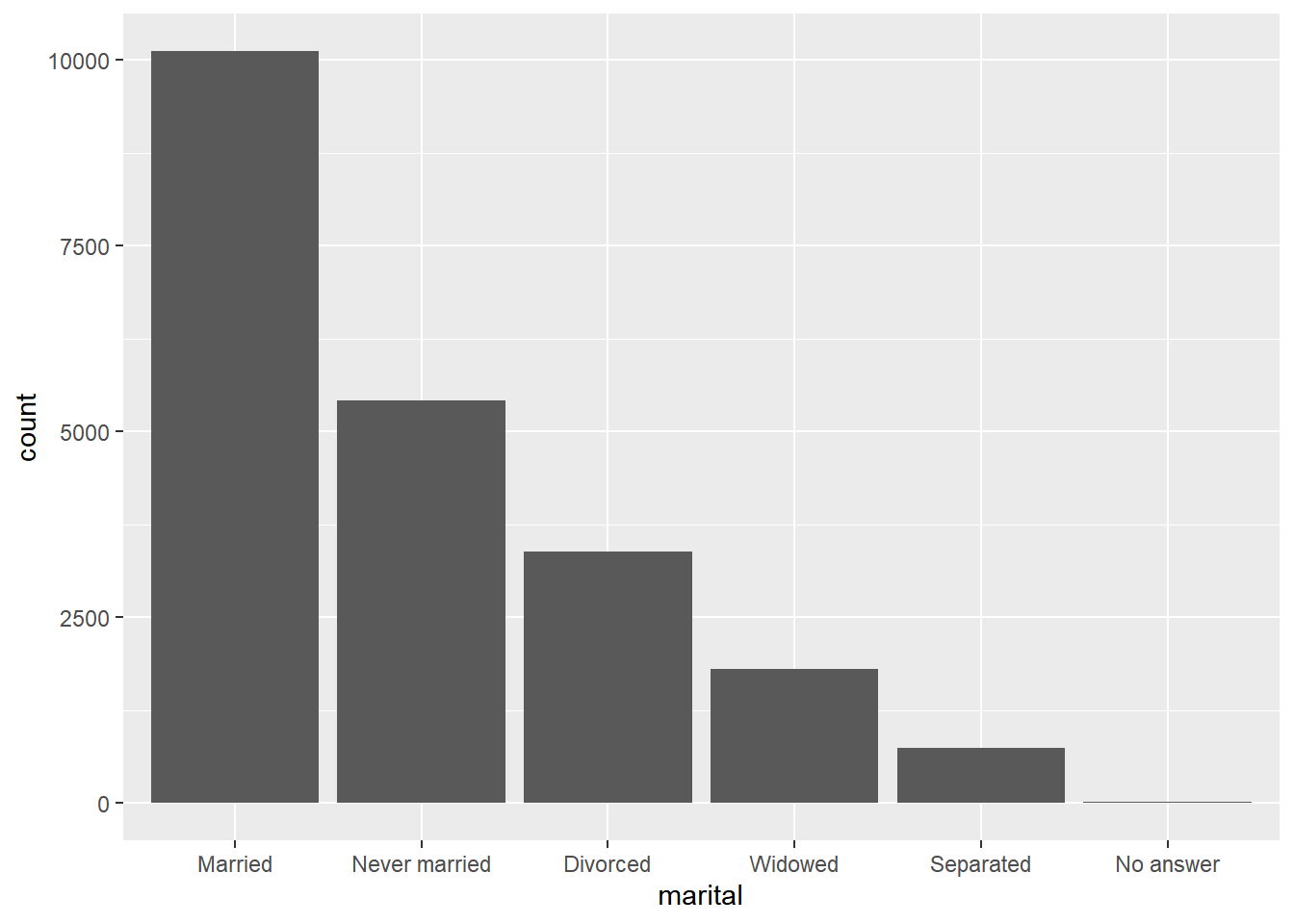
11.3 修改因子水平
# fct_recode()-手动修改因子水平的编码(名称),新值在左边,旧值在右边
gss_cat |>
mutate(
partyid = fct_recode(
partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat"
)
) |>
count(partyid)# A tibble: 10 × 2
partyid n
<fct> <int>
1 No answer 154
2 Don't know 1
3 Other party 393
4 Republican, strong 2314
5 Republican, weak 3032
6 Independent, near rep 1791
7 Independent 4119
8 Independent, near dem 2499
9 Democrat, weak 3690
10 Democrat, strong 3490# fct_code()-将多个因子分配致同一新级别
gss_cat |>
mutate(
partyid = fct_recode(
partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat",
"Other" = "No answer",
"Other" = "Don't know",
"Other" = "Other party"
)
) |>
count(partyid)# A tibble: 8 × 2
partyid n
<fct> <int>
1 Other 548
2 Republican, strong 2314
3 Republican, weak 3032
4 Independent, near rep 1791
5 Independent 4119
6 Independent, near dem 2499
7 Democrat, weak 3690
8 Democrat, strong 3490# fct_collapse()-将多个因子合并为一个水平-折叠大量因子水平
# 比fct_recode()更清晰易读
gss_cat |>
mutate(
partyid = fct_collapse(
partyid,
"other" = c("No answer", "Don't know", "Other party"),
"rep" = c("Strong republican", "Not str republican"),
"ind" = c("Ind,near rep", "Independent", "Ind,near dem"),
"dem" = c("Not str democrat", "Strong democrat")
)
) |>
count(partyid)# A tibble: 4 × 2
partyid n
<fct> <int>
1 other 548
2 rep 5346
3 ind 8409
4 dem 7180# A tibble: 10 × 2
relig n
<fct> <int>
1 Protestant 10846
2 Catholic 5124
3 None 3523
4 Christian 689
5 Other 458
6 Jewish 388
7 Buddhism 147
8 Inter-nondenominational 109
9 Moslem/islam 104
10 Orthodox-christian 9511.4 有序因子
有序因子是一类特殊的因子:
- 使用
ordered()函数创建,表示因子水平之间存在严格的顺序关系,但并不根据具体数值进行界定。 - 有序因子的顺序可以通过
<符号进行识别。