tidyverse中处理缺失值的函数主要来自dplyr和tidyr。
数据在拿到手时,通常不会是很工整的,通常会存在缺失值、格式混乱、数据有错误等问题,我们不能直接进行分析,需要对其进行预处理,也就是所谓的数据清洗。这个步骤非常重要,通常要占据整个分析或建模过程的75%的工作量。
缺失值
R中的缺失值用符号NA表示,空值用NULL表示。在处理缺失值时,需要将表示缺失值的一些其他符号(如na,NaN等)替换成NA在进行处理。
值得注意的是,R中的NA带有“传染性”,即只要有NA参与的计算,结果也会变成NA,所以对缺失值的处理非常重要。本节我们主要关注naniar包对缺失值的处理和探索的过程。
探索缺失值
- 缺失值统计
# A tibble: 153 × 3
case n_miss pct_miss
<int> <int> <dbl>
1 5 2 33.3
2 27 2 33.3
3 6 1 16.7
4 10 1 16.7
5 11 1 16.7
6 25 1 16.7
7 26 1 16.7
8 32 1 16.7
9 33 1 16.7
10 34 1 16.7
# ℹ 143 more rows
# A tibble: 3 × 3
n_miss_in_case n_cases pct_cases
<int> <int> <dbl>
1 0 111 72.5
2 1 40 26.1
3 2 2 1.31
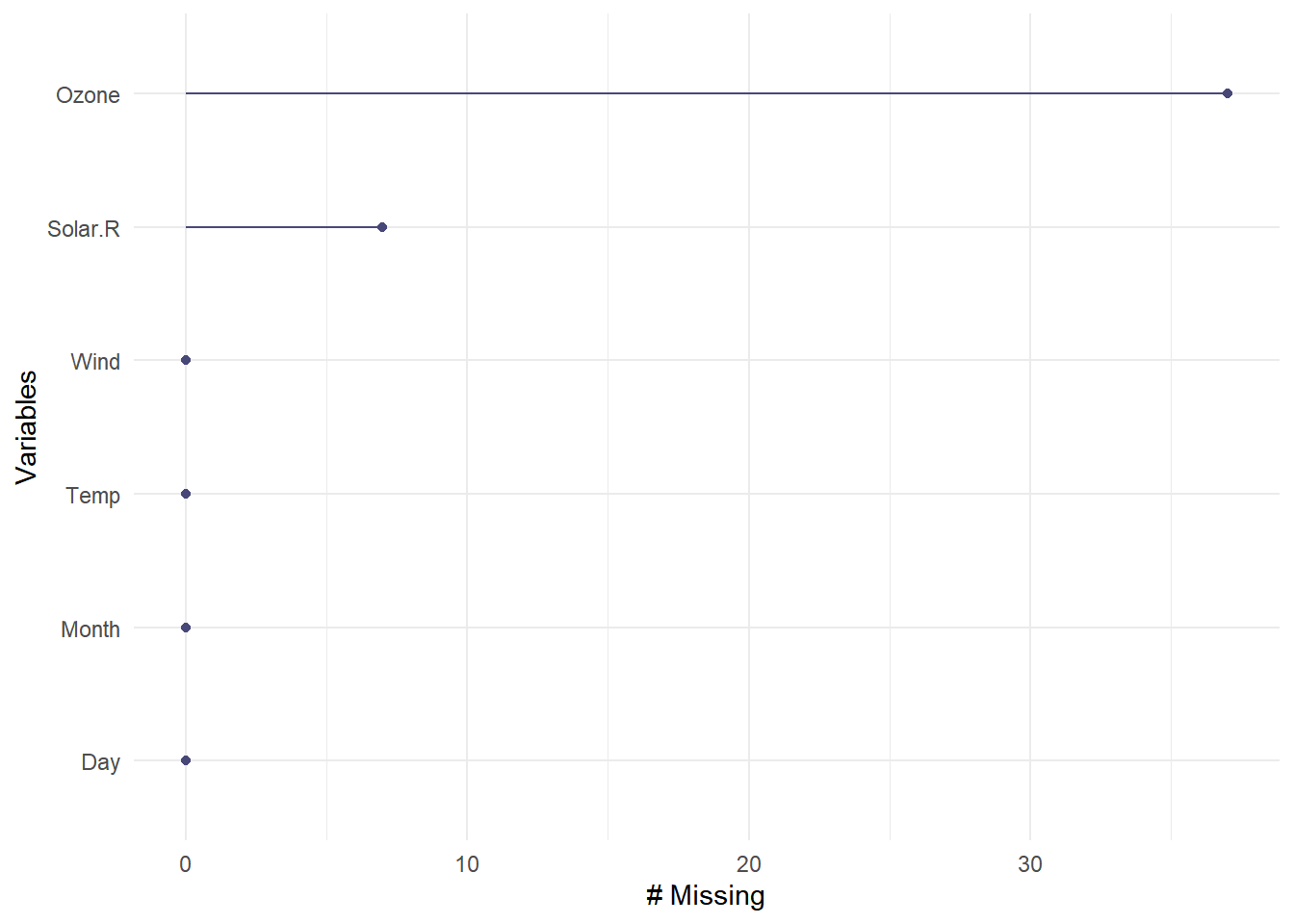
# A tibble: 6 × 3
variable n_miss pct_miss
<chr> <int> <num>
1 Ozone 37 24.2
2 Solar.R 7 4.58
3 Wind 0 0
4 Temp 0 0
5 Month 0 0
6 Day 0 0
# A tibble: 3 × 3
n_miss_in_var n_vars pct_vars
<int> <int> <dbl>
1 0 4 66.7
2 7 1 16.7
3 37 1 16.7
以上所有函数均可以与group_by()连用,进行缺失值的分组探索。
我们也可以对缺失值进行可视化的探索。
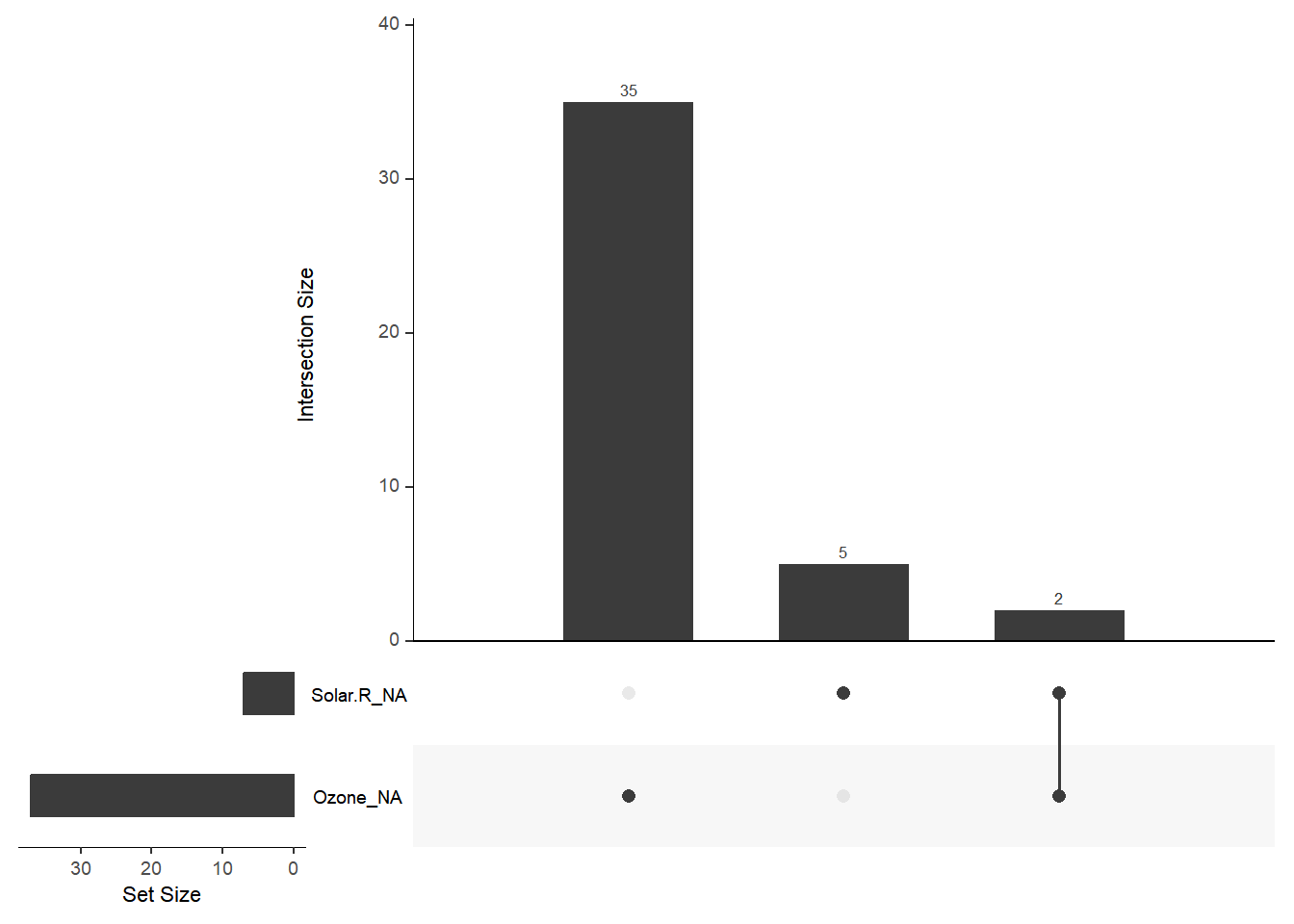
- 对比缺失与非缺失数据
借助影子矩阵进行对比。影子矩阵与数据集维度相同,用于标记各个数据是否缺失(缺失用NA表示,不缺失用!NA表示)。
使用bind_shadow()函数将影子矩阵与原数据按列合并,进而开展下一步分析。
# 生成影子矩阵
aq_shadow <- bind_shadow(airquality)
aq_shadow
# A tibble: 153 × 12
Ozone Solar.R Wind Temp Month Day Ozone_NA Solar.R_NA Wind_NA Temp_NA
<int> <int> <dbl> <int> <int> <int> <fct> <fct> <fct> <fct>
1 41 190 7.4 67 5 1 !NA !NA !NA !NA
2 36 118 8 72 5 2 !NA !NA !NA !NA
3 12 149 12.6 74 5 3 !NA !NA !NA !NA
4 18 313 11.5 62 5 4 !NA !NA !NA !NA
5 NA NA 14.3 56 5 5 NA NA !NA !NA
6 28 NA 14.9 66 5 6 !NA NA !NA !NA
7 23 299 8.6 65 5 7 !NA !NA !NA !NA
8 19 99 13.8 59 5 8 !NA !NA !NA !NA
9 8 19 20.1 61 5 9 !NA !NA !NA !NA
10 NA 194 8.6 69 5 10 NA !NA !NA !NA
# ℹ 143 more rows
# ℹ 2 more variables: Month_NA <fct>, Day_NA <fct>
# 根据Ozone是否缺失,计算Solar.R的几个常用统计量
library(tidyverse)
aq_shadow %>%
group_by(Ozone_NA) %>%
summarise(across(
Solar.R,
list(
\(x) mean(x, na.rm = T),
\(x) sd(x, na.rm = T),
\(x) var(x, na.rm = T),
\(x) min(x, na.rm = T),
\(x) max(x, na.rm = T)
)
))
# A tibble: 2 × 6
Ozone_NA Solar.R_1 Solar.R_2 Solar.R_3 Solar.R_4 Solar.R_5
<fct> <dbl> <dbl> <dbl> <int> <int>
1 !NA 185. 91.2 8309. 7 334
2 NA 190. 87.7 7690. 31 332
处理缺失值
如果样本数据足够,且缺失样本比较少,可以使用na.omit()函数直接剔除包含NA的样本。
如果只想剔除少部分包含NA的行,使用drop_na(df, <tidy-select>)直接删除。
如果想删除大部分(但不是全部的)包含NA的行,需要使用如下代码。
可以简单的使用tidy::fill()函数指定需要填补的变量(直接使用前值);或tidy::coalesce(x, default)(使x的缺失值用default取代)。
df_miss <- tibble(
A = c(1, NA, NA, 2, NA, NA),
B = c(1, 2, 3, 1, 2, 3),
n = c(12, 10, NA, 15, NA, 14)
)
df_miss
# A tibble: 6 × 3
A B n
<dbl> <dbl> <dbl>
1 1 1 12
2 NA 2 10
3 NA 3 NA
4 2 1 15
5 NA 2 NA
6 NA 3 14
# 填补A列缺失值
df_miss %>%
tidyr::fill(A)
# A tibble: 6 × 3
A B n
<dbl> <dbl> <dbl>
1 1 1 12
2 1 2 10
3 1 3 NA
4 2 1 15
5 2 2 NA
6 2 3 14
# A tibble: 6 × 4
A B n x
<dbl> <dbl> <dbl> <dbl>
1 1 1 12 12
2 NA 2 10 10
3 NA 3 NA 0
4 2 1 15 15
5 NA 2 NA 0
6 NA 3 14 14
有时,有可能缺失值被输入成了一个特殊数值,比如,x的值仅取正数,输入了-1就表示缺失值。在读入CSV文件时,如果所有缺失值都用-1表示,可以在read_csv()中加选项na = -1。如果不同列有不同的缺失值编码, 可以用na_if(x, na_value)将x中等于na_value的值改为缺失值,可以用在mutate()中,如mutate(x = na_if(x, -1))。