3 整洁数据
在数据分析过程中,数据清理和整理是非常重要的步骤。整洁数据(Tidy Data)是一种数据组织方式,使得数据更易于分析和可视化。在本章中,我们将介绍如何使用tidyr包来整理数据,使其符合整洁数据的原则。
3.1 整洁数据的原则
- 变量:是可以测量的数量、性质或属性。
- 值:是一个变量在被测量时的状态。多次测量变量时其值可能会发生变化。
- 观测:也称为数据点,在相似条件下进行的一组测量。一个观测包括了多个值,每个值与不同的变量关联。

如 图 3.1 , 整洁数据的基本原则包括:
- 每个变量形成一列,每一列代表一个变量。例如,温度、湿度等不同的测量指标应分别存储在不同的列中。
- 每个观测形成一行,每一行代表一个观测。例如,每个时间点或每个实验条件下的测量结果应存储在不同的行中。
- 每个值占一个单元格,每个单元格代表一个值。
- 每个类型的观测单位形成一个表格。
我们看3个例子来理解这些原则。
table1# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583table2# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583table3# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583在上面的例子中:
table1符合整洁数据的原则。table2和table3则不符合。table2中的cases和population变量被存储在同一列type中,而table3中将cases和population变量的计算结果储存在rate列中。
3.2 Lengthening data- 长格式化数据
遗憾的是,为了阅读方便,大多数时候我们并不能直接获得整洁的数据。我们需要对数据进行整理,使其符合整洁数据的原则。
tidyr 提供了两个用于数据转置的函数: pivot_longer() 和 pivot_wider() 。要进行这两个函数的操作,我们首选需要弄清楚哪些是变量,哪些是观测,这有时看起来会很复杂;然后将数据变换为整洁模式,变量位于列中,观测位于行中。
我们先从pivot_longer()函数开始,它用于将数据从宽格式转换为长格式。它将多个列合并为两列:一列用于存储变量名称,另一列用于存储变量值。
3.2.1 列名中包含单个变量
billboard# A tibble: 317 × 79
artist track date.entered wk1 wk2 wk3 wk4 wk5 wk6 wk7 wk8
<chr> <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2 Pac Baby… 2000-02-26 87 82 72 77 87 94 99 NA
2 2Ge+her The … 2000-09-02 91 87 92 NA NA NA NA NA
3 3 Doors D… Kryp… 2000-04-08 81 70 68 67 66 57 54 53
4 3 Doors D… Loser 2000-10-21 76 76 72 69 67 65 55 59
5 504 Boyz Wobb… 2000-04-15 57 34 25 17 17 31 36 49
6 98^0 Give… 2000-08-19 51 39 34 26 26 19 2 2
7 A*Teens Danc… 2000-07-08 97 97 96 95 100 NA NA NA
8 Aaliyah I Do… 2000-01-29 84 62 51 41 38 35 35 38
9 Aaliyah Try … 2000-03-18 59 53 38 28 21 18 16 14
10 Adams, Yo… Open… 2000-08-26 76 76 74 69 68 67 61 58
# ℹ 307 more rows
# ℹ 68 more variables: wk9 <dbl>, wk10 <dbl>, wk11 <dbl>, wk12 <dbl>,
# wk13 <dbl>, wk14 <dbl>, wk15 <dbl>, wk16 <dbl>, wk17 <dbl>, wk18 <dbl>,
# wk19 <dbl>, wk20 <dbl>, wk21 <dbl>, wk22 <dbl>, wk23 <dbl>, wk24 <dbl>,
# wk25 <dbl>, wk26 <dbl>, wk27 <dbl>, wk28 <dbl>, wk29 <dbl>, wk30 <dbl>,
# wk31 <dbl>, wk32 <dbl>, wk33 <dbl>, wk34 <dbl>, wk35 <dbl>, wk36 <dbl>,
# wk37 <dbl>, wk38 <dbl>, wk39 <dbl>, wk40 <dbl>, wk41 <dbl>, wk42 <dbl>, …billboard数据集包含了不同歌曲在不同时间点的排名信息。
- 前三列
artist,track和date.entered是描述歌曲信息的变量。 -
wk1到wk76列表示歌曲在不同周的排名。这些列的列名实际应该是一个变量week的不同取值,而列中的值则是另一个变量rank的取值。
理解了这些变量后,我们可以使用pivot_longer()函数将数据转换为tidy格式。
billboard |>
pivot_longer(
cols = starts_with("wk"), # 选择要转换的列
names_to = "week", # 新列用于存储变量名称
values_to = "rank", # 新列用于存储变量值
values_drop_na = TRUE # 删除缺失值
)# A tibble: 5,307 × 5
artist track date.entered week rank
<chr> <chr> <date> <chr> <dbl>
1 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk1 87
2 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk2 82
3 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk3 72
4 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk4 77
5 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk5 87
6 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk6 94
7 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk7 99
8 2Ge+her The Hardest Part Of ... 2000-09-02 wk1 91
9 2Ge+her The Hardest Part Of ... 2000-09-02 wk2 87
10 2Ge+her The Hardest Part Of ... 2000-09-02 wk3 92
# ℹ 5,297 more rows注意,在上面的代码中,“week” 和 “rank”,都用引号括起来了,这是因为我们在调用pivot_longer()函数时,“week” 和 “rank”在数据集中还不存在,是要新建的变量。
How does pivoting work 中有关于pivot_longer()函数工作原理的更详细解释。
3.2.2 列名中包含多个变量
who2# A tibble: 7,240 × 58
country year sp_m_014 sp_m_1524 sp_m_2534 sp_m_3544 sp_m_4554 sp_m_5564
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 1980 NA NA NA NA NA NA
2 Afghanistan 1981 NA NA NA NA NA NA
3 Afghanistan 1982 NA NA NA NA NA NA
4 Afghanistan 1983 NA NA NA NA NA NA
5 Afghanistan 1984 NA NA NA NA NA NA
6 Afghanistan 1985 NA NA NA NA NA NA
7 Afghanistan 1986 NA NA NA NA NA NA
8 Afghanistan 1987 NA NA NA NA NA NA
9 Afghanistan 1988 NA NA NA NA NA NA
10 Afghanistan 1989 NA NA NA NA NA NA
# ℹ 7,230 more rows
# ℹ 50 more variables: sp_m_65 <dbl>, sp_f_014 <dbl>, sp_f_1524 <dbl>,
# sp_f_2534 <dbl>, sp_f_3544 <dbl>, sp_f_4554 <dbl>, sp_f_5564 <dbl>,
# sp_f_65 <dbl>, sn_m_014 <dbl>, sn_m_1524 <dbl>, sn_m_2534 <dbl>,
# sn_m_3544 <dbl>, sn_m_4554 <dbl>, sn_m_5564 <dbl>, sn_m_65 <dbl>,
# sn_f_014 <dbl>, sn_f_1524 <dbl>, sn_f_2534 <dbl>, sn_f_3544 <dbl>,
# sn_f_4554 <dbl>, sn_f_5564 <dbl>, sn_f_65 <dbl>, ep_m_014 <dbl>, …有时,列名中可能包含多个变量的信息。例如,who2数据集中:
- 前2列
country,year已经是描述观察的变量。 - 其余的56列,例如
sp_m_014、ep_m_4554和rel_m_3544,它们均由3个部分组成,分别表示诊断疾病所用的方式(sp,ep,rel),性别(m,f)和年龄组(014,4554,3544),这些列名实际上包含了3个变量的信息,并用_连接符分割。
理解了这些变量后,我们发现who2数据集其实应该包含6个变量,分别为:
- 已经存在的
country和year。 - 需要从列名中提取的
diagnosis、sex和age,以及 - 这些列别中患者的数量
count。
who2 |>
pivot_longer(
cols = !(c(country, year)), # 选择要转换的列
names_to = c("diagnosis", "sex", "age"), # 新列用于存储变量名称
names_sep = "_", # 列名中的变量是用"_"分割的
values_to = "count", # 新列用于存储变量值
# values_drop_na = TRUE # 同样可以删除缺失值
)# A tibble: 405,440 × 6
country year diagnosis sex age count
<chr> <dbl> <chr> <chr> <chr> <dbl>
1 Afghanistan 1980 sp m 014 NA
2 Afghanistan 1980 sp m 1524 NA
3 Afghanistan 1980 sp m 2534 NA
4 Afghanistan 1980 sp m 3544 NA
5 Afghanistan 1980 sp m 4554 NA
6 Afghanistan 1980 sp m 5564 NA
7 Afghanistan 1980 sp m 65 NA
8 Afghanistan 1980 sp f 014 NA
9 Afghanistan 1980 sp f 1524 NA
10 Afghanistan 1980 sp f 2534 NA
# ℹ 405,430 more rows3.2.3 列名中包含变量和数据
household# A tibble: 5 × 5
family dob_child1 dob_child2 name_child1 name_child2
<int> <date> <date> <chr> <chr>
1 1 1998-11-26 2000-01-29 Susan Jose
2 2 1996-06-22 NA Mark <NA>
3 3 2002-07-11 2004-04-05 Sam Seth
4 4 2004-10-10 2009-08-27 Craig Khai
5 5 2000-12-05 2005-02-28 Parker Gracie 有时,列名中可能同时包含变量和数据的信息。例如household数据集中:
family列已经是描述观察的变量。后四列中,列名包含了两个变量(
dob和name),以及另一个变量的值(child,值为1或2)。-
理解了这些变量后,我们发现
household数据集其实应该包含4个变量,分别为:- 已经存在的
family。 - 需要从列名中提取的
dob和name,以及 - 这些列别中孩子的编号
child。
- 已经存在的
household |>
pivot_longer(
cols = -family,
names_to = c(".value", "child"),
names_sep = "_",
values_drop_na = TRUE
)# A tibble: 9 × 4
family child dob name
<int> <chr> <date> <chr>
1 1 child1 1998-11-26 Susan
2 1 child2 2000-01-29 Jose
3 2 child1 1996-06-22 Mark
4 3 child1 2002-07-11 Sam
5 3 child2 2004-04-05 Seth
6 4 child1 2004-10-10 Craig
7 4 child2 2009-08-27 Khai
8 5 child1 2000-12-05 Parker
9 5 child2 2005-02-28 Gracie以上代码在names_to参数中使用.value来指示哪些新列是变量名称,哪些是变量值。.value是一个特殊的占位符,它告诉pivot_longer()函数将.value所在位置的组件作为输出中变量名,而对应的值则作为输出中的值。简单的说,.value表示输入的列名中既包含了变量名称,也包含了变量值。
这块比较难以理解,我们深入看看:
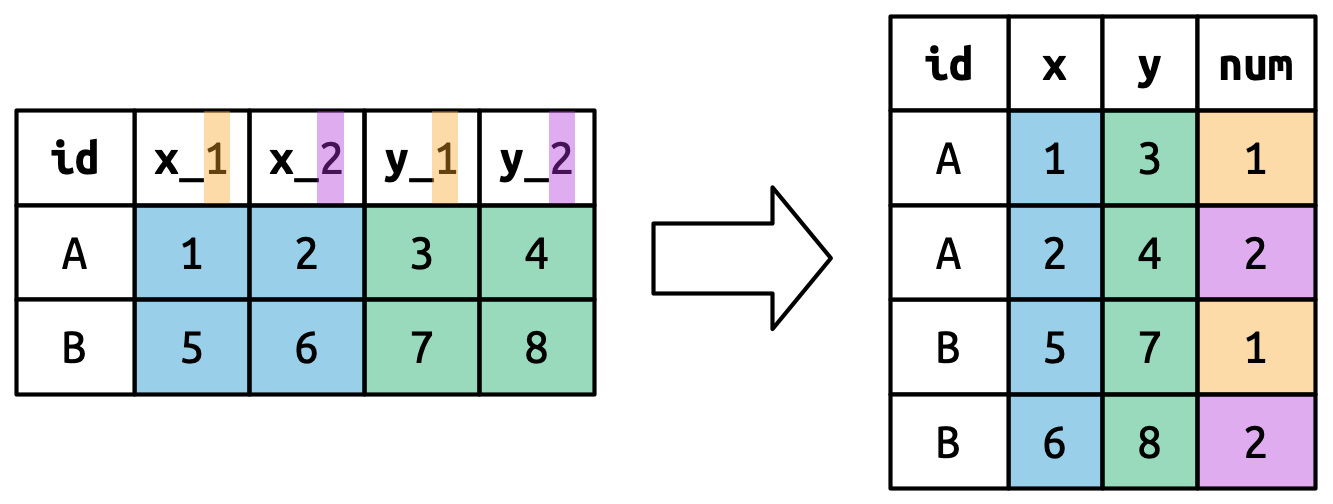
.value
如 图 3.2 所示:使用 names_to = c(".value", "num") 拆分列名成两部分:第一部分确定输出列名( x 或 y ),第二部分确定 num 列的值。在以上代码中,dob 或name 就对应 x 或 y, child_1或child_2就对应1或2。
3.3 Widening data-宽格式化数据
在开始pivot_wider()之前,我们需要明确那些内容作为新表的行,那些作为列。
cms_patient_experience# A tibble: 500 × 5
org_pac_id org_nm measure_cd measure_title prf_rate
<chr> <chr> <chr> <chr> <dbl>
1 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 63
2 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 87
3 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 86
4 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 57
5 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 85
6 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 24
7 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 59
8 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 85
9 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 83
10 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 63
# ℹ 490 more rowscms_patient_experience数据集包含了医疗保险和医疗补助服务中心在不同年份的患者满意度评分信息。
数据集中,每个组织(org)的数据分散在多行中,每一行对应某一机构的其中一项测量结果,但存在几个问题:
-
measure_cd列包含了不同的测量指标代码,这些代码实际上应该是变量measure的不同取值。 -
measure_title列包含了测量指标的描述信息,是一个包含了空格的长句子,这样的列名不利于数据分析。
实际展示时,我们希望每个测量指标都有自己的列,这样每个组织的数据就可以集中在一行中,即measure_cd列需要根据其不同的值进行扩展,即宽格式化。
org开头的列的同时,从measure_cd列获取扩展后的列名,从prf_rate列中获取对应的值cms_patient_experience |>
pivot_wider(
id_cols = starts_with("org"), # 指定不进行转换的列
names_from = measure_cd, # 新列的列名来自measure_cd列
values_from = prf_rate # 新列的值来自prf_rate列
)# A tibble: 95 × 8
org_pac_id org_nm CAHPS_GRP_1 CAHPS_GRP_2 CAHPS_GRP_3 CAHPS_GRP_5 CAHPS_GRP_8
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0446157747 USC C… 63 87 86 57 85
2 0446162697 ASSOC… 59 85 83 63 88
3 0547164295 BEAVE… 49 NA 75 44 73
4 0749333730 CAPE … 67 84 85 65 82
5 0840104360 ALLIA… 66 87 87 64 87
6 0840109864 REX H… 73 87 84 67 91
7 0840513552 SCL H… 58 83 76 58 78
8 0941545784 GRITM… 46 86 81 54 NA
9 1052612785 COMMU… 65 84 80 58 87
10 1254237779 OUR L… 61 NA NA 65 NA
# ℹ 85 more rows
# ℹ 1 more variable: CAHPS_GRP_12 <dbl>pivot_wider()函数可能会产生原先数据集中不存在的缺失值,我们将在 (sce-missing-values?) 章节中介绍如何处理缺失值。
3.4 总结
在本章中,我们介绍了整洁数据的基本原则以及如何使用tidyr包中的pivot_longer()和pivot_wider()函数来整理数据。通过这些工具,我们可以将数据转换为更适合分析和可视化的格式。理解和应用这些原则和工具,将有助于我们更高效地进行数据分析工作。
值得注意的是,对于某些特定的数据集,很难明确的界定”长格式”或”宽格式”哪种才是真正的”整洁数据”。这里Hadley的建议是只要有利于简化分析过程,任何数据组织形式都可以被视为变量。因此当你在计算过程中遇到瓶颈时,不妨尝试调整数据组织结构——大胆地进行非整洁化处理、转换格式,并根据需要重新整理数据!