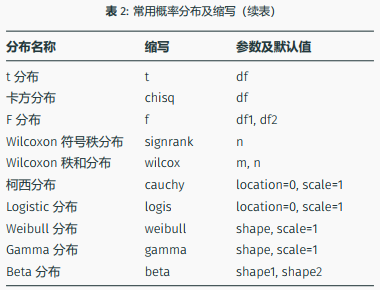
20 函数
20.1 向量函数
20.1.1 自定义函数把百分制分数转化为五分制分数的功能
第一步,分析输入和输出,设计函数外形
输入有几个,分别是什么,适合用什么数据类型存放?
输出有几个,分别是什么,适合用什么数据类型存放?
这个问题的输入有1个:百分制分数,数值型;输出有1个:五分制分数,字符串。在此基础设计自定义函数的外形。
Score_Conv <- function(score) {
# 实现将一个百分制分数转化为五级分数
# 输入参数:score为数值型,百分制分数
# 返回值:res为字符串型,五分制分数
...
}第二步,梳理功能实现的过程
分解问题+实例梳理+翻译及调试
拿一组本例的具体形参的值作为输入,如何将76分转换为五分制分数”良”,这依赖于对五级分数界限的选取,选定后可以使用分支判断实现。逐步调试,得到正确的返回值结果,这步很关键,是实现下一步复杂功能的基础。
[1] "中"第三步,将第二部的代码封装成为函数体
Score_Conv <- function(score) {
if (score >= 90) {
res <- "优"
} else if (score >= 80) {
res <- "良"
} else if (score >= 70) {
res <- "中"
} else if (score >= 60) {
res <- "及格"
} else {
res <- "不及格"
}
res
}在函数编制好后,我们可以尝试调用它
Score_Conv(76)[1] "中"20.1.2 改进函数-函数向量化
目前的函数仅能输入一个参数,在实际下通常需要输入多个参数。我们有两种方法实现
方法1:直接修改自定义函数
输入的参数为一个数值向量,对函数体进行修改。
Score_Conv2 <- function(score) {
n <- length(score)
res <- vector("character", n)
for (i in 1:n) {
if (score[i] >= 90) {
res[i] <- "优"
} else if (score[i] >= 80) {
res[i] <- "良"
} else if (score[i] >= 70) {
res[i] <- "中"
} else if (score[i] >= 60) {
res[i] <- "及格"
} else {
res[i] <- "不及格"
}
}
res
}
# 测试函数
Score_Conv2(c(35, 67, 100))[1] "不及格" "及格" "优" 方法2:直接使用map系列函数
得益于purrr中的map系列函数,我们可以将一个函数批量用在一些列元素中,从而达到不修改原函数而实现向量化操作。
20.1.3 返回多个处理值
如果需要返回多个处理值,则需要将多个值大包成一个列表(或数据框)再返回。
20.1.4 ...参数
一般函数参数只接受一个对象,比如对两个数加和的函数,给它 3 个数加和就会报错
...参数可以接受多个对象,并将其打包为一个列表传递给函数体
my_sum2 <- function(...){
sum(...)
}
my_sum2(1, 2, 3, 4, 5, 6)[1] 21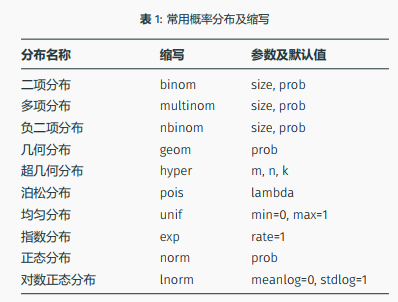
20.2 数据框函数
当我们需要重复使用dplyr函数时,就可以考虑编写一个数据框函数。它们以数据框作为第一个参数,后面跟着一些额外的参数用于说明如何处理,并输出一个数据框或向量。
20.2.1 简洁引用和整洁计算
dplyr 默认直接捕获函数参数中传入的变量名,而不是评估新传入的参数名,简单来讲就是将函数的参数作为变量引用了,这就是“间接引用”。它产生的原因是 dplyr 采取“整洁求值”(tidy evaluation)的规则,本意是方便我们在数据框中直接引用变量名而无需特别处理,但在封装成函数时却成了绊脚石。
针对这个问题,dplyr提供了解决方案,称为 embracing。embracing 将变量包裹在双层大括号中,例如 var 写成 {var},意为使用参数中的值,而不是把参数本身当作变量名。在使用以下几类函数时需要使用 embracing:
-
数据掩码(Data-masking):
arrange()、filter()、summarize()、group_by()等对变量计算的函数。 -
整洁选择(Tidy-selection):
select()、relocate()、rename()等选择变量的函数。 - 需要注意的是,在data-masking函数中使用tidy-selection,需要在对应的函数里套一个
pick()函数。
# A tibble: 1 × 2
group mean_value
<dbl> <dbl>
1 1 10# A tibble: 365 × 4
year month day n_miss
<int> <int> <int> <int>
1 2013 1 1 4
2 2013 1 2 8
3 2013 1 3 10
4 2013 1 4 6
5 2013 1 5 3
6 2013 1 6 1
7 2013 1 7 3
8 2013 1 8 4
9 2013 1 9 5
10 2013 1 10 3
# ℹ 355 more rows20.3 绘图函数
ggplot()函数中的aes() 同样是一个数据掩码函数(data-masking function),所以技巧大差不差。
20.3.1 与 tidyverse 结合
高效的绘图函数一般都将数据处理和 ggplot2 相结合。
在 R 语言中,:= 是 动态列名赋值运算符,核心用途是「在不提前明确列名(如用变量、表达式指定列名)的场景下,创建或修改数据框的列」。
20.3.2 绘图函数中的图表
如果在直方图中自动标注变量名和bin的宽度岂不美哉?要实现这个功能,我们需要使用rlang::englue(),此函数:
- 将
{}包裹的值插入字符串。 - 使用
{{}}识别并插入变量名。
histogram <- function(df, var, binwidth = NULL) {
label <- rlang::englue("变量{{var}}的直方图,bin宽度为{binwidth}")
df |>
ggplot(aes(x = {{ var }})) +
geom_histogram(binwidth = binwidth) +
labs(title = label)
}
diamonds |>
histogram(carat, 0.1)-1.png)
20.4 代码风格规范
虽然函数或参数命名的规范性不会影响R对其的执行,但恰当的命名对代码的可读性至关重要。理想的函数名应当简洁明了,能准确传达函数的功能。
通常而言,函数名宜采用动词,参数名宜采用名词。当然也有例外,比如某些约定成俗的名词,如均值函数mean()就比compute_mean()更合适。开发者应当灵活判断,大胆命名。此外,还有两点需格外注意: