24 Bootstrapping算法和置信区间
24.1 抽样
- 使用
moderndive::rep_sample_n()函数可以快速对数据集进行抽样。
bowl |>
rep_sample_n(size = 50)# A tibble: 50 × 3
# Groups: replicate [1]
replicate ball_ID color
<int> <int> <chr>
1 1 1182 white
2 1 1655 red
3 1 1152 white
4 1 891 red
5 1 672 white
6 1 1919 red
7 1 823 white
8 1 1596 red
9 1 1934 white
10 1 1413 white
# ℹ 40 more rowsstandard error:标准误差,量化了抽样变异对我们的估计值的影响。一般来说,样本量越大,标准误差越小,结果越准确。
中心极限定理:样本均值的分布应近似正态分布。中心极限定理意味着,即使数据的分布不是正态的,从中抽取的样本均值的分布也是正态的。均值正态分布的实际含义:
- 我们可以用均值的正态分布来分配置信区间。
- 我们可以进行T检验(即两个样本均值之间是否存在差异)
- 我们可以进行方差分析(即3个或更多样本的均值之间是否存在差异)
24.2 Pennies activity
我们从一个实际的例子出发。
24.2.1 2019年美国使用硬币上的平均年份(硬币上的铸造年)是多少?
2019年在美国使用的所有硬币是一个非常庞大的数量。假如现在我们对所有这些硬币的平均铸造年份感兴趣。我们可以收集所有使用的硬币,然后对年份进行统计计算,显然这个方法基本不可能实现。那么我应该使用抽样的方法,收集其中的50个硬币,并进行分析。假设moderndive包中的pennies_sample数据就是我们收集的这50个硬币的数据。
pennies_sample# A tibble: 50 × 2
ID year
<int> <dbl>
1 1 2002
2 2 1986
3 3 2017
4 4 1988
5 5 2008
6 6 1983
7 7 2008
8 8 1996
9 9 2004
10 10 2000
# ℹ 40 more rowsggplot(pennies_sample, aes(x = year)) +
geom_histogram(binwidth = 10, color = "white") +
scale_x_continuous(breaks = seq(1950, 2030, by = 10))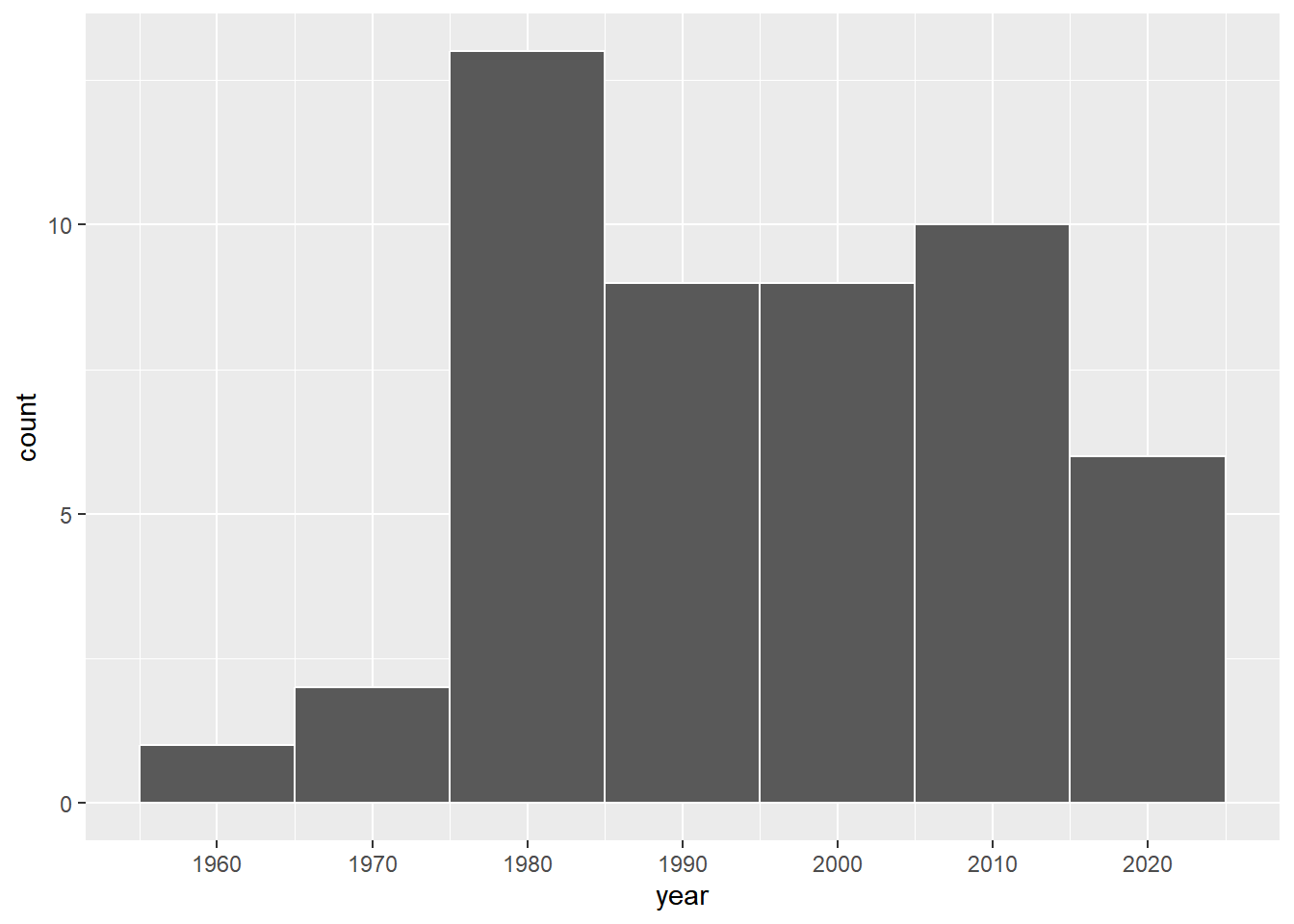
可以看出:
- 分布为左偏分布(分布图形的尾巴在左边)。
- 大部分硬币的铸造时间分布于1980-2010年间,年份早于1970年的硬币很少。
如果根据这50个硬币来推断所有的硬币的铸造平均年份就为他们的平均值。
这里带来一个问题,这50个硬币是否可以代表所有硬币呢?其实是不行的。。
24.2.2 重采样-bootstrap算法
24.2.2.1 一次重采样
Bootstrapping算法,指的就是利用有限的样本资料经由多次重复抽样,重新建立起足以代表母体样本分布的新样本。bootstrapping的运用基于很多统计学假设,因此采样的准确性会影响假设的成立与否。
Bootstrapping方法的实现很简单,假设抽取的样本大小为n: 在原样本中有放回的抽样,抽取n次。每抽一次形成一个新的样本,重复操作,形成很多新样本,通过这些样本就可以计算出样本的一个分布。新样本的数量通常是1000-10000。如果计算成本很小,或者对精度要求比较高,就增加新样本的数量。
- 优点:简单,易于操作。
- 缺点,算法基于统计学假设,因此假设的成立与否会影响抽样的准确性。
针对上述50个硬币样本,我们采用如下操作:
- 将50个硬币的年份分别写在纸条上,并放入箱中;
- 从箱子中随机抽取1个,记录其年份后将其放回箱子(为什么放回?避免抽样变异);
- 重复第二步,直到抽取50次。
这样我们就完成了一次重采样的操作。
如果我们多次重复这个重采样的的步骤会发生什么?
24.2.2.2 执行35次重抽样
每次重抽样的步骤与 小节 24.2.2.1 的步骤一致。
假设我们已经重复35次,就得到了 \(35 \times50=1750\) 个年份的数据pennies_resamples。表中的name列代表不同抽取人的姓名。
pennies_resamples# A tibble: 1,750 × 3
# Groups: name [35]
replicate name year
<int> <chr> <dbl>
1 1 Arianna 1988
2 1 Arianna 2002
3 1 Arianna 2015
4 1 Arianna 1998
5 1 Arianna 1979
6 1 Arianna 1971
7 1 Arianna 1971
8 1 Arianna 2015
9 1 Arianna 1988
10 1 Arianna 1979
# ℹ 1,740 more rows# A tibble: 35 × 2
name mean_year
<chr> <dbl>
1 Arianna 1992.
2 Artemis 1996.
3 Bea 1996.
4 Camryn 1997.
5 Cassandra 1991.
6 Cindy 1995.
7 Claire 1996.
8 Dahlia 1998.
9 Dan 1994.
10 Eindra 1994.
# ℹ 25 more rowsggplot(resamples_means, aes(x = mean_year)) +
geom_histogram(binwidth = 1, color = "white", boundary = 1990) +
labs(x = "Sampled mean year")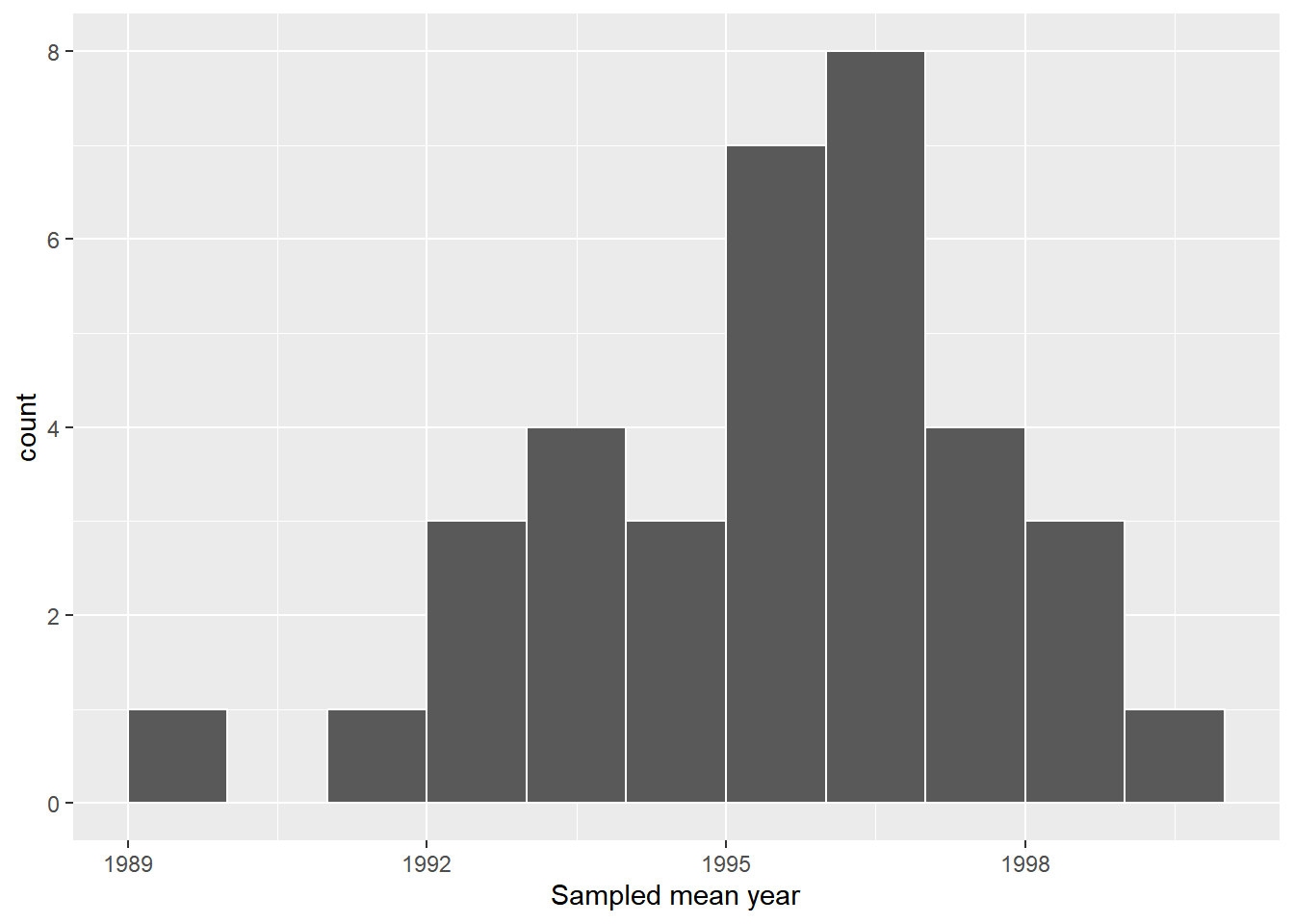
图 24.2 显示,分布大致正常,且与之前单次重采样的分布大体一致。此外,该分布大致与1995年为中心(接近原始样本平均值1995年,即来自银行的原始样本50便士的样本平均值)。
24.2.2.3 小结
使用bootstrap分布,我们可以研究抽样变异对模型估计值的影响,也就是通常意义上的标准误差(standard error)。
24.3 抽样变异-标准差和标准误
样本统计量因随机抽样而产生的差异成为抽样变异。
24.3.1 标准差
标准差是方差的平方根,是衡量原始数据离散程度的常用指标。R中使用sd()函数可以直接计算样本的标准差。
假如我们从一个装满红球和白球的碗中抽取红球的概率为 \(p\),标准差为 \(sd\),我们可以将标准差直观的理解为,如果从总体中有放回的多次抽取样本,可以预计抽到红球的比例将围绕 \(p\) 波动,波动的范围约为 \(sd\)
\[ SD = \sqrt{\frac{1}{n-1}\sum^n_{i-1}|x_i-\bar{x}|^2} \]
24.3.2 标准误
标准误是抽样分布的标准差,使用标准差除以样本量平方根计算 (式 25.1) ,是衡量样本均值的可靠性,也就是样本均值和总体真实均值之间的差异。
\[ SE = \frac{SD}{\sqrt{n}} \tag{24.1}\]
24.4 R语言模拟重抽样
24.4.1 执行一次重抽样
virtual_resample <- pennies_sample |>
rep_sample_n(size = 50, replace = TRUE)
virtual_resample# A tibble: 50 × 3
# Groups: replicate [1]
replicate ID year
<int> <int> <dbl>
1 1 19 1983
2 1 45 1997
3 1 42 1997
4 1 25 1979
5 1 21 1981
6 1 21 1981
7 1 27 1993
8 1 7 2008
9 1 15 1974
10 1 14 1978
# ℹ 40 more rows# A tibble: 1 × 2
replicate resample_mean
<int> <dbl>
1 1 1995.24.4.2 执行多(35)次重抽样
只需在rep_sample_n()函数中指定参数reps为想要重抽样的次数即可。
# 35次重抽样
virtual_resamples <- pennies_sample |>
rep_sample_n(size = 50, replace = TRUE, reps = 35)
virtual_resamples# A tibble: 1,750 × 3
# Groups: replicate [35]
replicate ID year
<int> <int> <dbl>
1 1 32 1976
2 1 6 1983
3 1 7 2008
4 1 23 1998
5 1 2 1986
6 1 5 2008
7 1 35 1985
8 1 31 2013
9 1 38 1999
10 1 6 1983
# ℹ 1,740 more rows# A tibble: 35 × 2
replicate mean_year
<int> <dbl>
1 1 1994.
2 2 1997.
3 3 1995.
4 4 1998.
5 5 1995.
6 6 1991.
7 7 1995.
8 8 1995.
9 9 1996.
10 10 1998
# ℹ 25 more rows# 可视化重抽样均值分布
ggplot(virtual_resampled_means, aes(x = mean_year)) +
geom_histogram(binwidth = 1, color = "white") +
labs(x = "Resample mean year")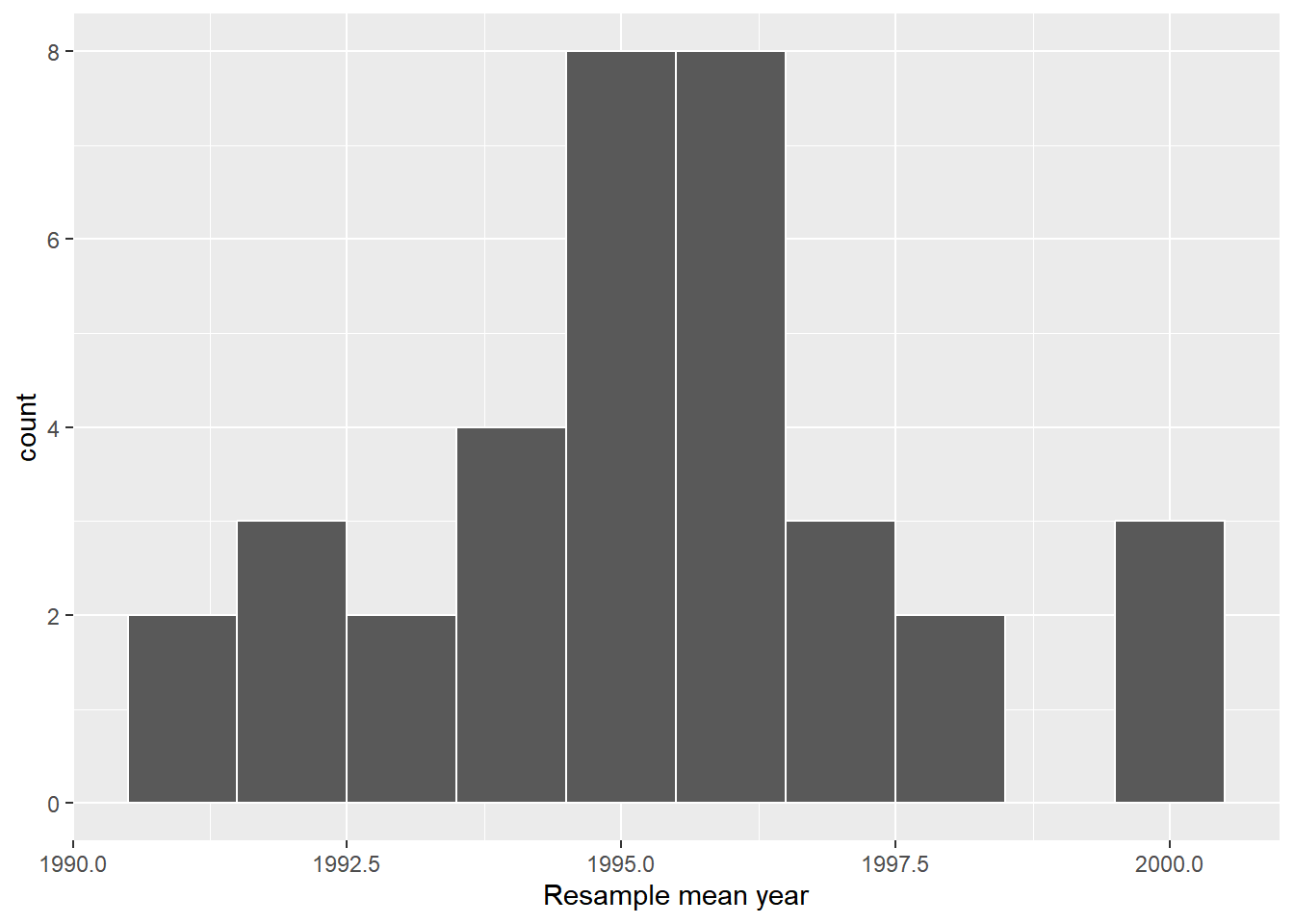
24.4.3 执行更多(1000)次重抽样
virtual_resamples <- pennies_sample |>
rep_sample_n(size = 50, replace = TRUE, reps = 1000)
virtual_resampled_means <- virtual_resamples |>
group_by(replicate) |>
summarise(mean_year = mean(year))
virtual_resampled_means# A tibble: 1,000 × 2
replicate mean_year
<int> <dbl>
1 1 1991.
2 2 1995.
3 3 1996.
4 4 1995.
5 5 1993.
6 6 1996.
7 7 1999.
8 8 1998.
9 9 1997.
10 10 1994.
# ℹ 990 more rowsggplot(virtual_resampled_means, aes(x = mean_year)) +
geom_histogram(binwidth = 1, color = "white", boundary = 1990) +
labs(x = "sample mean")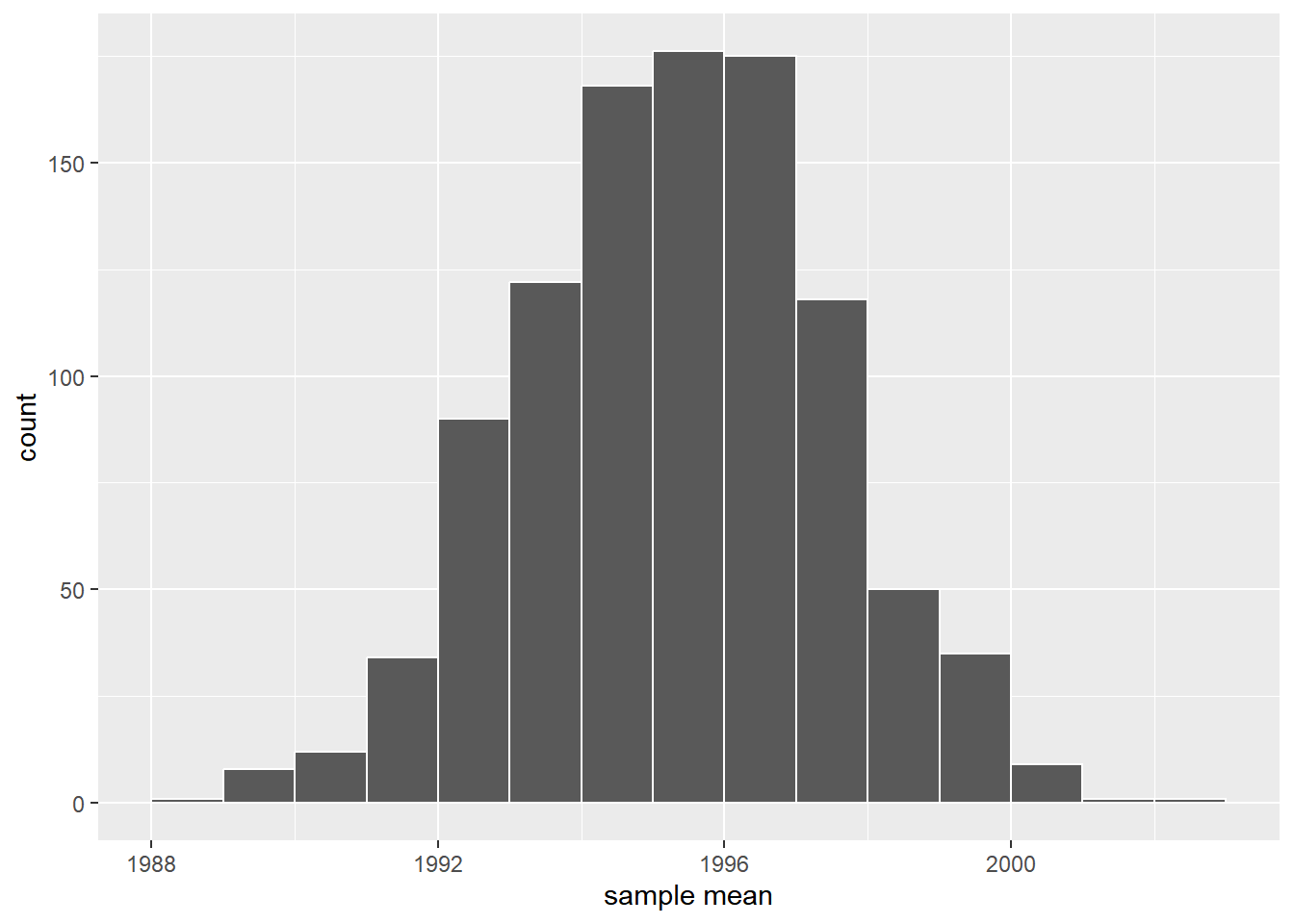
上图显示,随着重抽样次数的增加,bootstrap分布愈加趋近于正态分布(符合中心极限定理)。
至此,我们对样本均值的可能取值范围有了基本了解,那么下一步就需要使用此引导分布来构造置信区间 小节 24.5。
24.5 构造并理解置信区间
置信区间给出了一系列合理值的范围,用CI表示。
但是这个1900-2000的范围是我们通过肉眼大致识别出来的,取值过于主观,如何精确计算置信区间呢?通常有两种方法:百分位数法和标准误差法。
要使用这两种方法计算置信区间,需要预先执行两个步骤(或两个前提):
均是由
boostrap分布为前提构造的。需要明确指定置信水平(
confidence level)。常用的置信水平包括90%、95%和99%。在所有其他条件相同的情况下,较高的置信水平对应于较宽的置信区间,较低的置信水平对应于较窄的置信区间。95%的置信水平是最常用的。
24.5.1 百分数法
通过计算bootstrap分布的2.5%和97.5%处的值作为置信区间的范围,即为95%置信水平下的置信区间范围。
24.5.2 标准误差法
根据中心极限定理,bootstrap分布是服从正态分布的,标准误差法正是使用这个特性来计算置信区间的。
正态分布95%置信区间的置信区间的计算公式为 \(mean \pm 1.96sd\)。
计算
bootstrap分布的均值 \(\bar{x}\)(应与原始样本的均值基本一致)。计算
bootstrap分布的均值标准差SE,这个值可以认为是标准误差的近似值。根据公式,最终计算95%置信水平下的置信区间为 \(\bar{x} \pm 1.96SE\)
只有当bootstrap分布大体服从正态分布时,才可以使用标准误差法计算置信区间。这就必须保证重抽样的数量。
24.6 计算置信区间
此前的章节,我们使用rep_sample_n()函数进行重抽样,并进行后续的计算。本节,我们将使用infer包(整洁的、简便的统计推断包)构建CI。
24.6.1 infer包基本工作流程-生成抽样分布
Response: year (numeric)
# A tibble: 1 × 1
stat
<dbl>
1 1995.使用infer包的工作流程至少有以下三个主要优势:
infer包的参数名称可以更好的与构建置信区间和进行假设检验所需的整体重采样框架保持一致 章节 25。 具体流程图可参见 图 24.5。infer包允许我们在置信区间和假设检验间无缝切换,仅需修改非常少量的代码。infer包在对多于一个变量的统计推断有更简洁的工作流程。
下面,我们对infer包计算置信区间的流程及函数进行说明(仍旧使用美国2019使用硬币的数据集):
24.6.1.1 specify()-变量

如 图 24.3 显示,specify()是用来选择数据集中那个/那些变量是我们做统计推断的关注的焦点。函数中的response参数用来指定这些变量。
pennies_sample |>
specify(response = year)Response: year (numeric)
# A tibble: 50 × 1
year
<dbl>
1 2002
2 1986
3 2017
4 1988
5 2008
6 1983
7 2008
8 1996
9 2004
10 2000
# ℹ 40 more rowsresponse参数也可以指定为formula = y ~ x的形式,y为因变量,x为自变量。
在接下来的 小节 24.8 中,我们将对两个样本进行比较,到时就会在response中用到formula了。
24.6.1.1.1 generate()-复制
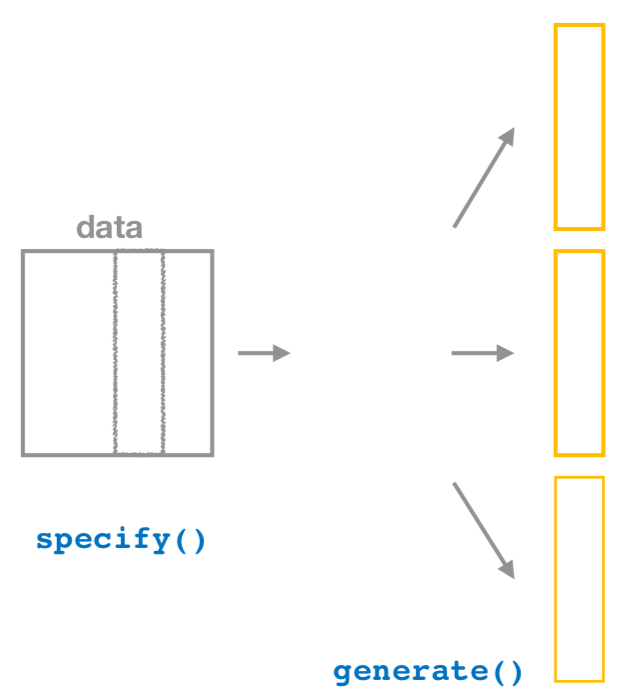
当我们通过specify()选定了变量后,就需要将其传入generate()函数中生成它的复制(即进行重抽样),有些类似rep_sample_n()函数的操作。图 24.4 显示了这一工作流程。基本用法如下:
generate(reps, type)参数reps指定生成复制的次数,参数type决定了我们要执行的计算机模拟的类型。type = "bootstrap"是默认设置,表示我们希望执行bootstrap重抽样。
在 章节 25 中,我们会学习更多的type类型。
Response: year (numeric)
# A tibble: 50,000 × 2
# Groups: replicate [1,000]
replicate year
<int> <dbl>
1 1 1998
2 1 1976
3 1 1996
4 1 1971
5 1 1988
6 1 1999
7 1 1982
8 1 2006
9 1 2017
10 1 2008
# ℹ 49,990 more rows
24.6.1.2 calculate()-汇总统计
calculate()函数的基本形式如下:
calculate(stat = ...)参数stat指定了要计算的统计量。让我们完整的使用以上的三个函数进行重抽样,并计算样本均值的平均值。
Response: year (numeric)
# A tibble: 1,000 × 2
replicate stat
<int> <dbl>
1 1 1996.
2 2 1996.
3 3 1991.
4 4 1991.
5 5 1994.
6 6 1996.
7 7 1993.
8 8 1995.
9 9 1996.
10 10 1998.
# ℹ 990 more rows
24.6.1.3 visualize()-结果及可视化
visualize()函数的用法十分简单:
visualize(bootstrap_dist)-1.png)
visualize()函数的其它参数主要的作用是美化图形,具体可查看帮助。

24.6.2 infer中的分位数法
get_confidence_interval()或简写的get_ci()函数,名字表示的很清楚,具体用法如下:
percentile_ci <- bootstrap_dist |>
get_confidence_interval(
level = 0.95, # 设定置信水平
type = "percentile"
)
percentile_ci# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 1991. 2000.同时,我们还可以与visualize()连用,将置信区间在图中显示:
visualise(bootstrap_dist) + # 与ggplot类似
# 可简写成shade_ci()
shade_confidence_interval(
endpoints = percentile_ci,
color = "blue",
fill = "steelblue"
)+shade_ci()-1.png)
24.6.3 infer中的标准误差法
与分位数法类似:
- 需要将
get_confidence_interval()函数中的type参数改为”se”即可。 - 必须指定
point_estimate参数,为原样本的平均值。
origin_mean <- pennies_sample |>
specify(response = year) |>
calculate(stat = "mean")
stander_error_ci <- bootstrap_dist |>
get_confidence_interval(
level = 0.95,
type = "se",
point_estimate = origin_mean
)
stander_error_ci# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 1991. 2000.24.7 置信区间的解释
为了证明置信区间的有效性,我们必须了解总体参数的值,只有这样才能知道置信区间是否可以包括这些值。
但在现实生活中,总体参数往往是不可知的,这就需要对估计。
这次我们使用bowl数据集。我们要看看从bowl中抽取球,其中是红球的概率是多少?
Response: color (factor)
# A tibble: 1 × 1
stat
<dbl>
1 0.375Response: color (factor)
# A tibble: 1,000 × 2
replicate stat
<int> <dbl>
1 1 0.38
2 2 0.44
3 3 0.28
4 4 0.48
5 5 0.32
6 6 0.44
7 7 0.42
8 8 0.52
9 9 0.38
10 10 0.34
# ℹ 990 more rows# 计算置信区间
percentile_ci_1 <- sample_1_bootstrap |>
get_ci(level = 0.95, type = "percentile")
percentile_ci_1# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 0.28 0.54# 可视化
## 计算原始样本平均值
orgin_pror <- bowl_sample_1 |>
specify(response = color, success = "red") |>
calculate(stat = "prop")
visualize(sample_1_bootstrap, bins = 15) +
shade_ci(endpoints = percentile_ci_1) +
geom_vline(xintercept = .42, linetype = "dashed")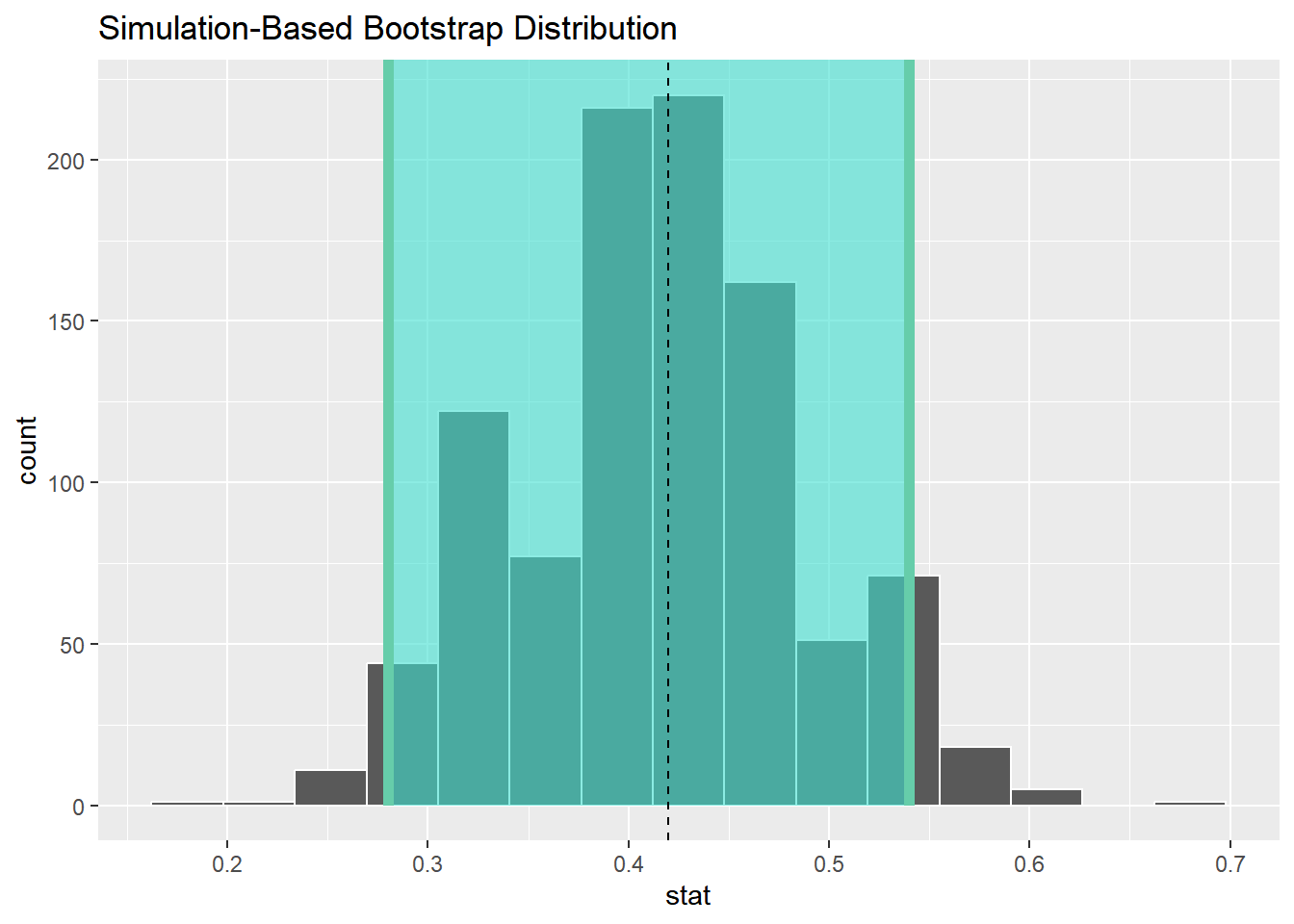
-
bowl总体参数(即总体取出红球的概率)为0.375。 - 0.375处在计算的置信区间(0.28, 0.56)范围内。即基于新样本的95%置信区间包含总体参数0.375。
95%置信水平下的置信区间,是指总体参数的真实值有95%的概率会落入该区间内。
注意:置信区间并不是包含了95%的总体参数真实值。
24.7.1 置信区间的宽度
置信水平越高,置信区间越宽(范围越大),置信区间包含总体平均值统计量的概率越大。
样本数量越大,置信区间越窄。
置信区间越宽,估计的精度越低。样本量逐渐增加,样本特征越来越接近总体特征,自然区间估计的精度也就越来越高,所以置信区间也就越来越窄。
24.8 实例操作:打哈欠会传染吗?
24.8.1 数据检视
我们探索打哈欠的数据集。
mythbusters_yawn# A tibble: 50 × 3
subj group yawn
<int> <chr> <chr>
1 1 seed yes
2 2 control yes
3 3 seed no
4 4 seed yes
5 5 seed no
6 6 control no
7 7 seed yes
8 8 control no
9 9 control no
10 10 seed no
# ℹ 40 more rows-
subj:参与调查人员编号。 -
group:参与人员是否暴露在打哈欠的环境中,seed表明暴露在打哈欠的环境中,control表明没有。 -
yawn:参与人员是否最终打了哈欠。
# A tibble: 4 × 3
# Groups: group [2]
group yawn count
<chr> <chr> <int>
1 control no 12
2 control yes 4
3 seed no 24
4 seed yes 10暴露在“哈欠”环境中的测试人员共有\(24+10=34\)人,最终打了哈欠的人有10个 ,概率为\(10/34=0.294=29.4\%\)。
未暴露在“哈欠”环境中的测试人员共有\(12+4=16\)人,最终打了哈欠的人有4个 ,概率为$ 4/16 = 0.25 = 25%$。
两组测试人员最终的打哈欠结果概率相差不大,需要进一步进行测试。
24.8.2 采样方案
由于该数据集只有由50个调查人员组成的数据集,我们要测算两组测试人员打哈欠的概率差在95%置信水平下的置信区间,必须使用boostrtap重抽样方法。
24.8.2.1 构建置信区间
- 与
pennies_sample不同,本例中的数据需要探索两个变量之间的关系,所以specify()中,我们需要指定一个公式,yawn ~ group:
- 响应变量为
yawn:最终要探索的结果。 - 解释变量为
group:不同的分组。 - 公式的解释即为:不同分组对响应变量的影响。
- 别忘记
success参数,指定我们关注的变量的结果。
- 构造置信区间-使用分位数法
myth_ci_percentile <- bootstrap_dist_yawing |>
get_confidence_interval(type = "percentile", level = 0.95)
myth_ci_percentile# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 -0.226 0.314- 构造置信区间-使用标准误差法:注意,我们需要计算原始样本的统计量(即不重抽样,直接计算所需统计量)
Response: yawn (factor)
Explanatory: group (factor)
# A tibble: 1 × 1
stat
<dbl>
1 0.0441# 构建置信区间
myth_ci_se <- bootstrap_dist_yawing |>
get_ci(type = "se", point_estimate = obs_diff_props)
myth_ci_se# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
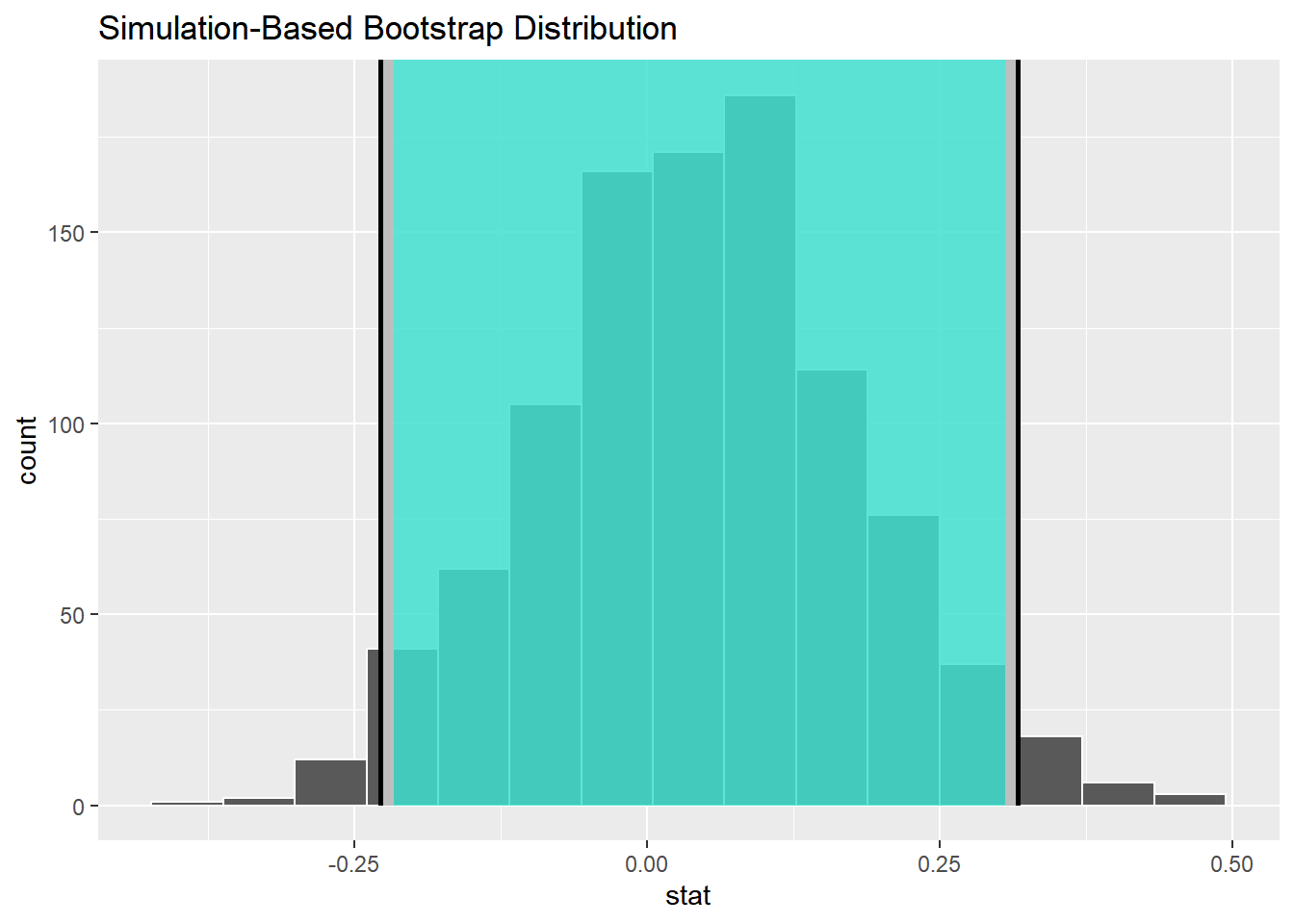
1 -0.221 0.309- 绘图
24.8.3 解释置信区间
由 图 24.6 可知,两种方法计算得出的置信区间基本一致,我们就聚焦其中一个方法-分位数法,即-0.2255053, 0.3140117。
我们有95%的“信心”,说明\(p_{seed}-p_{control}\)的真实差距在-0.2255053, 0.3140117之间。
在本例中,置信区间的值包含了0,所以我们无法最终确定哪一个分组所占的比例较大。
Say, on the other hand, the 95% confidence interval was entirely above zero. This would suggest that\(p_{seed}−p_{control}>0\), or, in other words\(p_{seed}>p_{control}\), and thus we’d have evidence suggesting those exposed to yawning do yawn more often.
24.9 结论
bootstrap分布与原始样本的分布的中心不一定相同,换言之,bootstrap重抽样并不能改进估计的准确率。bootstrap分布与原始样本的分布的形状及分布,换言之,bootstrap可以更好的估计标准误差。