R4DS-读书笔记
Introduction
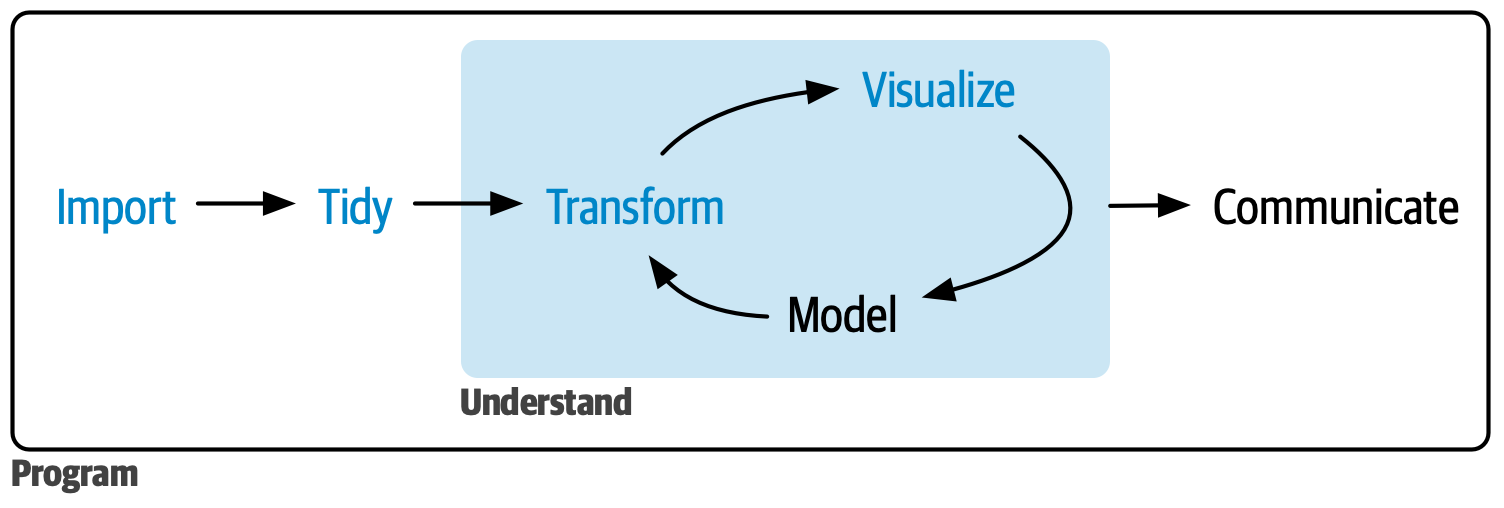
我希望把自己学习R语言和数据科学的过程记录和和整合一下。
这本读书笔记包括9个部分,分别对应使用R语言进行数据科学的个板块:
- 使用R语言进行数据科学:这个板块由
数据科学的whole game,可视化,变量类型和变量操作工具,数据导入,R语言编程5个部分构成,主要为R for Data Science 的读书笔记和心得。具体的章节组成如下:
数据科学的whole game 部分:从可视化入手,对数据科学的总体流程和工具的初步学习,包括四个章节:
可视化 部分,深入学习
ggplot2包的各个方面,包括3个章节:- 5 图层 学习图形的分层语法。
- 6 EDA 结合可视化技术与你的好奇心和怀疑精神,提出并解答有关数据的有趣问题。
- 7 ggplot2的其他元素-解释性图表 中 将学习如何将探索性图表进行提升,并将其转化为说明性图表,即帮助分析新手尽可能快速、轻松地理解图表所展示内容的图表。
变量类型和变量操作工具 部分,将学习在数据框中会遇到的最重要的变量类型,并掌握处理这些变量的工具。它们基本上是独立设计的。
- 8 逻辑变量 教你关于逻辑向量的知识。这些是最简单的向量类型,但它们却极其强大。我们将学习如何使用数值比较来创建它们,如何将它们与布尔代数相结合,如何在总结中使用它们,以及如何利用它们进行条件转换。
- 9 数值数字变量 深入探讨了用于数值向量的工具,这是数据科学的强大动力。我们将学到更多关于计数以及一系列重要的转换和汇总函数的知识。
- ?sec-strings 提供处理字符串的工具:我们可以对它们进行切片、切块,也可以将它们重新拼接在一起。本章主要关注
stringr包,但会涉及到一些更多专用于从字符串中提取数据的tidyr函数。 - ?sec-regular-expressions 介绍正则表达式,这是处理字符串的强大工具。本章将引导你从想象一只猫走过你的键盘,到阅读和编写复杂的字符串模式。
- 11 因子 引入了 因子变量:R 语言用于存储分类数据的数据类型。当变量具有一组固定的可能值时,或者当你想对字符串进行非字母顺序排序时,可以使用因子。
- 12 日期和时间 提供了处理日期和日期时间的关键工具。遗憾的是,你越了解日期时间,它们似乎就越复杂,但有了
lubridate包的帮助,你将学会如何克服最常见的挑战。 - 13 缺失值 深入讨论了缺失值问题,帮助我们理解隐式缺失值和显式缺失值之间的区别,以及如何在它们之间进行转换以及为什么要这样做。
- 14 数据连接 通过提供将两个(或更多)数据框连接在一起的工具,学习连接操作会促使你深入思考键的概念,并思考如何识别数据集中的每一行。
数据导入 部分,我们将学习如何将更多类型的数据导入R中,以及如何将其转换为对分析有用的形式。有时,这只需从相应的数据导入包中调用一个函数即可。 但在更复杂的情况下,可能需要同时进行整理和转换,才能得到你更愿意使用的整洁数据。
- 在 15 电子表格数据读取 中,你将学习如何从Excel电子表格和Google表格中导入数据。
- 在 16 数据库 中,你将学习如何从数据库中获取数据并将其导入R中(同时,你也会学到一些如何从R中获取数据并将其导入数据库的知识)。
- 在 17 箭头-Arrow 中,你将了解到Arrow,这是一个处理内存外数据的强大工具,尤其是当数据以parquet格式存储时。
- 在 18 分层数据-Hierarchical data 中,你将学习如何处理层级数据,包括处理以JSON格式存储的数据所生成的深度嵌套列表。
- 在 19 网络爬虫 中,你将学习网页“抓取”,即从网页中提取数据的艺术与科学。
R语言编程 部分,我们的目标是提升自己的编程技能。编程是所有数据科学工作中都不可或缺的跨领域技能:你必须使用计算机来进行数据科学工作;你无法仅凭头脑或纸笔来完成这项工作。
- 复制粘贴是一个强大的工具,但我们应该避免使用超过两次。 在代码中重复自己是很危险的,因为这很容易导致错误和不一致。 相反,在 20 函数 中,我们将学习如何编写函数,以提取提取出重复的
tidyverse代码,用于轻松复用。 - 函数可以提取出重复的代码,但往往需要对不同的输入重复执行相同的操作。 这时就需要使用迭代的工具,这些工具能让你一遍又一遍地做类似的事情。 这些工具包括for循环和函数式编程,我们将在 21 迭代 中学习到这些内容。
- 随着你阅读更多他人编写的代码,你会发现更多未使用
tidyverse的代码。 在 22 base R 简介 中,我们将学习一些在实际应用中会遇到的最重要的基础R函数。
- 复制粘贴是一个强大的工具,但我们应该避免使用超过两次。 在代码中重复自己是很危险的,因为这很容易导致错误和不一致。 相反,在 20 函数 中,我们将学习如何编写函数,以提取提取出重复的
- 统计学和机器学习基础:这个板块由
统计学基础和机器/统计学习基础2个部分构成,是统计学和机器学习的学习笔记和新的。具体的章节组成如下:
第一部分,统计学基础,包含4个章节:
- 23 统计学基础-描述性统计 描述性统计。
- 24 Bootstrapping算法和置信区间 自助法和置信区间。
- 25 假设检验 假设检验。
- 26 统计结果报告 统计结果报告的形式和规范。
第二部分,机器/统计学习基础,这部分主要为
tidymodels进行机器/统计学习的内容,包含13个章节:
- 模型构建和选择:这个板块进入具体的模型算法环节。具体的章节组成如下:
- 非集成算法部分:
- 39 预测数值型数据-回归方法 回归方法。
- 40 K-最邻近算法 Knn分类方法。
- 41 lasso回归 Lasso和Ridge回归。
- 42 非线性模型 非线性回归。
- 43 分而治之-应用决策树和规则进行分类 决策树和规则。
- 44 黑箱方法-神经网络和支持向量机 神经网络和支持向量机。
- 45 寻找数据的分组-k均值聚类 K均值聚类。
- 46 主成分分析 主成分分析。
- 集成算法部分:
- 47 集成算法简介 集成算法简介。
- 48 随机森林 随机森林。
- 49 梯度提升机-GBM 梯度提升机-GBM。
- 50 XGBoost XGBoost。
- 51 lightGBM lightGBM。
- 52 catboost catboost。
- 数据科学的其他主题:这个板块涉及了数据科学更广阔的内容,如大数据、地理信息数据等。具体的章节组成如下:
此外,有一些额外的附加内容在附录中:
- 附录 A — 算法思维 培养算法思维。
- 附录 B — 函数式编程 如何学习函数式编程的习惯。
- 附录 C — ggplot2 styling 设置 ggplot2的主题和风格设置。
- 附录 D — 假设检验实例 假设检验实例。
- 附录 G — 其它有趣的包 其他有趣和实用的包。
这本笔记的内容未来应该会不断扩充。