14 数据连接
14.1 数据连接基础
- 主键:数据框中每个观测只的唯一标识。如果需要一个以上的变量进行标识,被称为复合键。
- 外键:数据框中与另一表中的主键相对应的一个(或一组)变量。
- 一般来说,仅从数据中无法准确得知某一变量组合是否是一个好的主键组合。在实际操作中,我们可以引入一个简单的数字向量作为代理键。
以flights系列数据为例,下图可以很直观的概括每个数据表之间的关联关系:
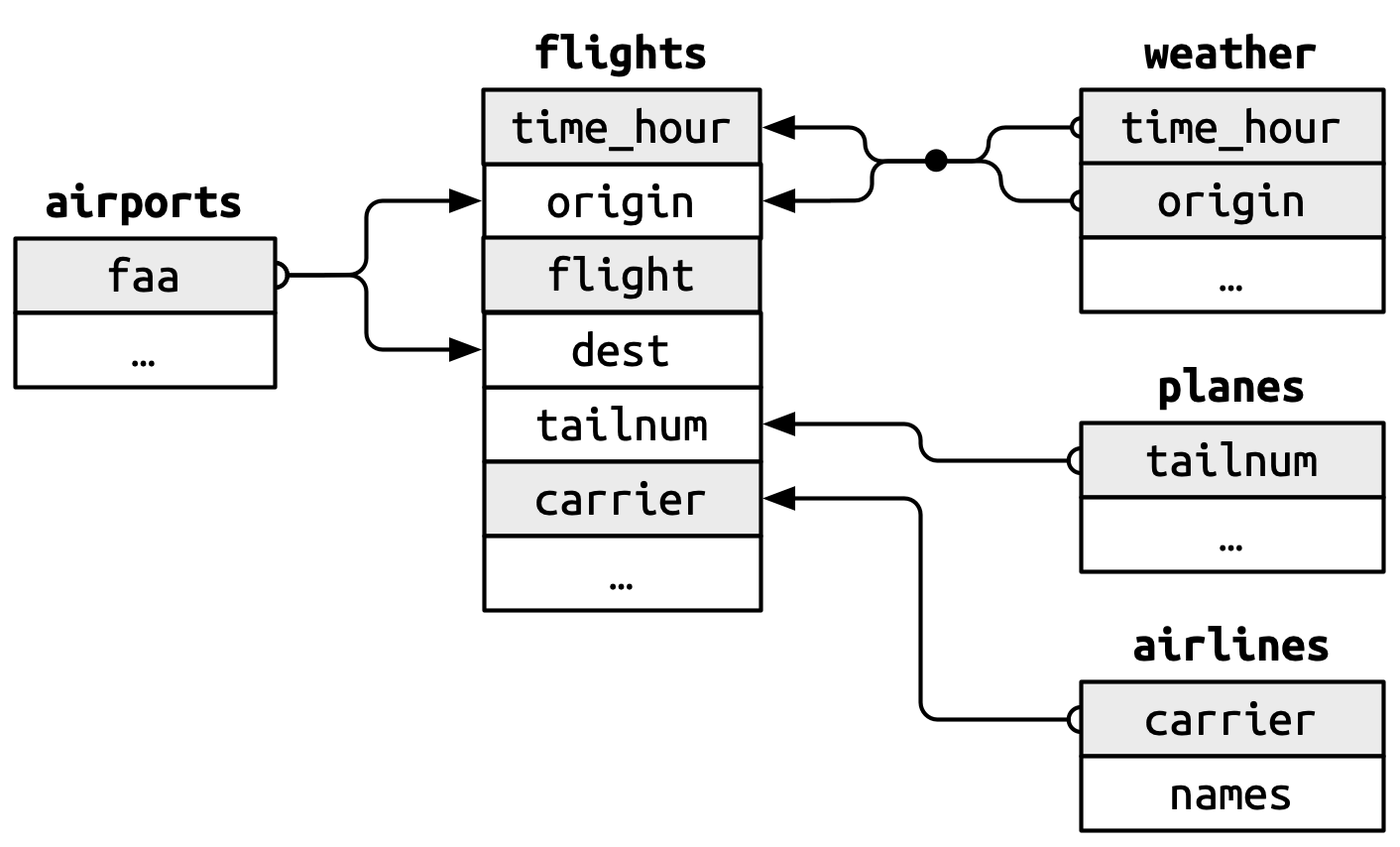
例如:
-
airports表中,每家航空公司由其两位字母的代码carrier唯一标识,因此carrier是主键。 -
weather表中,每条记录由origin(机场)和time_hour(时间)联合标识,是复合主键。 -
flight表中,则存在许多外键,例如:-
tailnum对应planes的主键。 -
origin和dest都对应airports的主键。 -
origin和time_hour联合对应weather表中的复合主键。
-
flights2 <- flights |>
mutate(id = row_number(), .before = 1)14.2 Mutating Join(变异连接)
变异连接(mutating joins):从另一个数据框中提取匹配行的变量,添加到当前数据框中,合并两个数据框中的变量
- 根据
key匹配值。 - 将一个数据框中的变量复制到另一数据框中。
- 主要有4种类型:
-
left_join(x, y, join_by(key.x == key.y)):将y连接至x中,返回的结果总是与x行数相同:- 主要用途是在
x中增加额外的元数据。 - 当无法在
x中找到所匹配的行时,使用缺失值填充。 - 通过
join_by(key.x == key.y)参数可以指定连接的键。
- 主要用途是在
-
inner_join(),right_join(),full_join()与left_join()拥有相同的接口,区别在于保留哪些行:-
inner_join()保留两个数据框中均存在的行,即重叠行。 -
right_join()保留y中所有的行。 -
full_join()保留所有的行。
-
14.3 Filtering Join(过滤连接)
筛选连接(filtering joins):根据是否在另一个数据框中存在匹配项,筛选当前数据框的行。主要有两种类型:
-
semi_join():返回x中与y匹配的所有记录。注意与left_join()的区别。-
semi_join()只关心 是否存在 匹配。它返回x的一个子集,只包含那些在y中能找到对应记录的行。它不会把y的列添加到结果中。 -
left_join()关心 所有信息。它会保留x的每一行,并尝试将y中所有匹配的行的信息都附加到x的对应行后面。如果x的某一行在y中有多个匹配,那么这一行就会被复制多次。如果x的某一行在y中没有匹配,它依然会被保留,但来自y的列会是NA。
-
anti_join():返回x中与y不匹配的所有记录。
x <- tribble(
~key , ~val_x ,
1 , "x1" ,
2 , "x2" ,
3 , "x3"
)
y <- tribble(
~key , ~val_y ,
1 , "y1" ,
2 , "y2" ,
4 , "y3" ,
5 , "y4"
)
inner_join(x, y)# A tibble: 2 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2 left_join(x, y)# A tibble: 3 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA> right_join(x, y)# A tibble: 4 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 4 <NA> y3
4 5 <NA> y4 full_join(x, y)# A tibble: 5 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
4 4 <NA> y3
5 5 <NA> y4 semi_join(x, y)# A tibble: 2 × 2
key val_x
<dbl> <chr>
1 1 x1
2 2 x2 -
inner_join():保留交集,输出结果为key列对应的1,2行。 -
left_join():保留x的所有行,同时匹配y中与x中key匹配的行,由于的key为3的行在y中没有对应项,因此输出结果为3行,且对应的val_y值为NA。 -
right_join():保留y的所有行,同时匹配x中与y中key匹配的行,由于的key为4,5的行在x中没有对应项,因此输出结果为4行,且对应的val_x值为NA。 -
full_join():全连接保留x和y中所有的行。无匹配的部分会填充NA。 -
semi_join():根据y筛选x,输出结果为2行,且不包括val_y(因为y只起到筛选作用)。anti_join()同理。
14.4 非等式连接
- 在上述连接的基础上,将连接条件更改为非等式,即为非等式连接。
- 在执行非等式连接时,总是同时显示两个key。
-
dplyr中的非等式连接有四种:
cross_join():交叉连接,匹配所有的内容,将x与y中的每一行进行连接,返回的结果类似于两个行列式进行乘积。-
不等式连接和滚动连接:同样使用
inner_join()函数,当连接条件为不等式时,inner_join()就转变为了非等式连接。- 不等式连接可以用于限制交叉连接的范围,例如只保留
id小的组合。
- 不等式连接可以用于限制交叉连接的范围,例如只保留
df <- tibble(name = c("John", "Simon", "Tracy", "Max"))
df |>
cross_join(df)# A tibble: 16 × 2
name.x name.y
<chr> <chr>
1 John John
2 John Simon
3 John Tracy
4 John Max
5 Simon John
6 Simon Simon
7 Simon Tracy
8 Simon Max
9 Tracy John
10 Tracy Simon
11 Tracy Tracy
12 Tracy Max
13 Max John
14 Max Simon
15 Max Tracy
16 Max Max # 不等式连接
df <- tibble(id = 1:4, name = c("John", "Simon", "Tracy", "Max"))
df |>
inner_join(df, join_by(id < id))# A tibble: 6 × 4
id.x name.x id.y name.y
<int> <chr> <int> <chr>
1 1 John 2 Simon
2 1 John 3 Tracy
3 1 John 4 Max
4 2 Simon 3 Tracy
5 2 Simon 4 Max
6 3 Tracy 4 Max -
滚动连接时不等式连接的一种特殊类型。通过添加在
join_by参数中添加closet()匹配与满足条件最接近的一条记录,如:-
join_by(closest(x <= y))找到满足y >= x的最小的y。 -
join_by(closest(x > y))找到满足y < x的最大的y。
-
-
重叠连接。重叠连接提供了三个使用不等式连接的助手,使处理间隔变得更容易:
-
between(x, y_lower, y_upper)是 x >= y_lower, x <= y_upper 的简称。 -
within(x_lower, x_upper, y_lower, y_upper)是 x_lower >= y_lower, x_upper <= y_upper 的简称。 -
overlaps(x_lower, x_upper, y_lower, y_upper)是 x_lower <= y_upper, x_upper >= y_lower 的简称。
-
14.4.1 滚动连接和重叠连接的一个例子
例如,假设公司每个季度只举办一次派对,而不是举办单独的派对。确定派对举办时间的规则有点复杂:
- 派对总是在周一举行,
- 因为很多人都在度假,所以跳过了一月的第一个星期,
- 而 2022 年第三季度的第一个星期一是 7 月 4 日,所以必须推迟一周。
通过以上规则确定聚会的日期为:
# A tibble: 4 × 2
season party
<int> <date>
1 1 2022-01-10
2 2 2022-04-04
3 3 2022-07-11
4 4 2022-10-03假设公司员工的生日如下所示:
# A tibble: 100 × 2
name birthday
<chr> <date>
1 Kemba 2022-01-22
2 Orean 2022-06-26
3 Kirstyn 2022-02-11
4 Amparo 2022-11-11
5 Belen 2022-03-25
6 Rayshaun 2022-01-11
7 Brazil 2022-05-01
8 Chaston 2022-10-29
9 Reyn 2022-03-26
10 Ogechi 2022-12-31
# ℹ 90 more rows对于每一个员工,公司都希望找到在他们生日之后(或当天)的第一个聚会日期。即员工生日大于聚会日期的最匹配的日期,回忆一下此时应该用滚动连接。
# A tibble: 233 × 4
name birthday season party
<chr> <date> <int> <date>
1 Kemba 2022-01-22 1 2022-01-10
2 Orean 2022-06-26 1 2022-01-10
3 Orean 2022-06-26 2 2022-04-04
4 Kirstyn 2022-02-11 1 2022-01-10
5 Amparo 2022-11-11 1 2022-01-10
6 Amparo 2022-11-11 2 2022-04-04
7 Amparo 2022-11-11 3 2022-07-11
8 Amparo 2022-11-11 4 2022-10-03
9 Belen 2022-03-25 1 2022-01-10
10 Rayshaun 2022-01-11 1 2022-01-10
# ℹ 223 more rows结果有个问题,1月10日之前过生日的员工永远无法参加聚会,因为公司最早的聚会日期就是1月10日,即:1月1日至9日生日之前没有聚会。因此,最好明确说明每个生日派对所跨越的日期范围,并为这些较早的生日设置一个特例,同时避免在任何开始和结束时间段没有重叠(这时就需要用到重叠连接了)。
# A tibble: 4 × 4
season party start end
<int> <date> <date> <date>
1 1 2022-01-10 2022-01-01 2022-04-03
2 2 2022-04-04 2022-04-04 2022-07-11
3 3 2022-07-11 2022-07-11 2022-10-02
4 4 2022-10-03 2022-10-03 2022-12-31# 检查时间段是否有重叠
parties |>
inner_join(
parties,
join_by(overlaps(start, end, start, end), season < season)
) |>
select(start.x, end.x, start.y, end.y)# A tibble: 1 × 4
start.x end.x start.y end.y
<date> <date> <date> <date>
1 2022-04-04 2022-07-11 2022-07-11 2022-10-02# 发现重叠日期为2022-07-11,日期进行修改。
parties <- tibble(
season = 1:4,
party = ymd(c("2022-01-10", "2022-04-04", "2022-07-11", "2022-10-03")),
start = ymd(c("2022-01-01", "2022-04-04", "2022-07-11", "2022-10-03")),
end = ymd(c("2022-04-03", "2022-07-10", "2022-10-02", "2022-12-31"))
)
# 将每位员工与聚会日期匹配,然后快速找出有哪些员工还没有分配到聚会
employees |>
inner_join(
parties,
join_by(between(birthday, start, end)),
unmatched = "error"
)# A tibble: 100 × 6
name birthday season party start end
<chr> <date> <int> <date> <date> <date>
1 Kemba 2022-01-22 1 2022-01-10 2022-01-01 2022-04-03
2 Orean 2022-06-26 2 2022-04-04 2022-04-04 2022-07-10
3 Kirstyn 2022-02-11 1 2022-01-10 2022-01-01 2022-04-03
4 Amparo 2022-11-11 4 2022-10-03 2022-10-03 2022-12-31
5 Belen 2022-03-25 1 2022-01-10 2022-01-01 2022-04-03
6 Rayshaun 2022-01-11 1 2022-01-10 2022-01-01 2022-04-03
7 Brazil 2022-05-01 2 2022-04-04 2022-04-04 2022-07-10
8 Chaston 2022-10-29 4 2022-10-03 2022-10-03 2022-12-31
9 Reyn 2022-03-26 1 2022-01-10 2022-01-01 2022-04-03
10 Ogechi 2022-12-31 4 2022-10-03 2022-10-03 2022-12-31
# ℹ 90 more rows